
In March 2025, a startup we'll call Velo shipped a fintech product in eleven days. Two founders, no employees, Cursor on one screen and Lovable on the other. The demo looked polished. The onboarding flow worked. They applied to Y Combinator, got in, raised a seed round, and started onboarding real users by June.
By September, three things had happened. A security researcher found that their Supabase instance had no Row Level Security policies, meaning any authenticated user could read any other user's transaction history. A second engineer they hired to build a payments integration spent two weeks trying to understand the existing codebase before telling the founders it would be faster to rewrite it. And a compliance review for their Series A flagged that nobody on the team could explain how their authentication system worked -- because it had been generated across seven separate files with duplicate logic that no human had designed.
Velo is a composite, but every detail is real, drawn from audits, incident reports, and founder postmortems published over the past year. They are not an outlier. They are the median.
The scale of the rebuild
In March 2025, Y Combinator CEO Garry Tan posted on X: "For 25% of the Winter 2025 batch, 95% of lines of code are LLM generated. That's not a typo. The age of vibe coding is here." YC managing partner Jared Friedman confirmed the figure during a recorded conversation, noting that the 95% excluded things like code written to import libraries -- meaning the figure represented substantive application code.
The YC W25 batch had roughly 300 companies. That's 75 startups with almost entirely AI-generated codebases in a single cohort. Scale that pattern across the thousands of startups that launched in 2025 using Cursor, Lovable, Replit, Bolt, and similar tools, and the numbers get large fast.
Tech Startups estimated in December 2025 that roughly 10,000 startups attempted to build production applications primarily with AI coding assistants, and that 8,000 of them now require partial or full rebuilds. That number is an industry estimate, not a census. But the order of magnitude is consistent with what we're seeing: rebuild costs running $50,000 to $500,000 per startup, timelines of four to eight months for re-architecture, and a total cleanup bill estimated between $400 million and $4 billion.
Rescue engineering (stabilizing and rebuilding codebases that shipped without sufficient human oversight) is emerging as one of the most in-demand specializations in 2026.
What actually went wrong
The problem is not AI. The problem is the absence of specification.
When Tan reflected on the trend he'd celebrated, he acknowledged the gap. "Let's say a startup with 95% AI-generated code goes out in the market, and a year or two out, they have 100 million users on that product. Does it fall over or not? The first versions of reasoning models are not good at debugging. So you have to go in-depth of what's happening with the product."
"Going in-depth" presupposes that someone understands the intent behind the implementation. That the system's purpose, boundaries, and behavioral contracts exist somewhere outside the code. For the majority of vibe-coded startups, they do not.
AlterSquare audited five vibe-coded startups and found the same three problems in every single codebase:
Inconsistent code and duplicate logic. One startup's authentication system had login logic duplicated across seven files. A marketplace app contained 47 different date-formatting implementations. Variable names like data1, temp, and res appeared everywhere. Each prompt generates a locally correct solution with no awareness of the existing architecture. The AI does not know what the system is, so it invents a new answer every time.
Missing error handling and security gaps. Over 80% of audited startups had critical security vulnerabilities: hardcoded AWS credentials, databases without access controls, client-side "security" that hid buttons in the UI while leaving backend endpoints wide open. One startup's exposed credentials resulted in $50,000 in unauthorized charges within twelve minutes of discovery.
Weak architecture and no testing. Tightly coupled components where a minor UI change triggered a full system redeployment. Happy-path code with no handling for database timeouts, malformed input, or concurrent access. Systems that worked on a laptop but failed in containers because filesystem paths were hardcoded.
The GitClear 2025 analysis of 211 million changed lines puts numbers on this pattern: code that was revised within two weeks of being written rose from 3.1% in 2020 to 7.1% in 2024. Copy-pasted code blocks increased eightfold. Refactoring -- the practice of improving existing code -- dropped from 25% of changed lines to less than 10%. AI-generated code is being produced faster and reworked sooner, while the structural improvements that make code maintainable are disappearing.
The Stack Overflow 2025 Developer Survey captured the practitioner experience: 84% of developers now use AI tools, but only 29% trust the accuracy of the output, down from 40% the previous year. The number-one frustration, cited by 45% of respondents: dealing with AI solutions that are "almost right, but not quite."
Almost right is the most expensive kind of wrong in software.
The security reckoning
The quality problems are expensive. The security problems are worse.
In May 2025, security researcher Matt Palmer published CVE-2025-48757, documenting a critical vulnerability in applications built with Lovable, one of the most popular AI app-building platforms. The root cause: Lovable-generated projects systematically failed to implement Row Level Security policies in their Supabase databases. Palmer's tests retrieved emails, phone numbers, payment details, API keys, and government identification documents from at least 170 Lovable-built applications.
By February 2026, The Register reported that a single Lovable-hosted app contained 16 vulnerabilities (six of them critical) and had leaked more than 18,000 people's data. Lovable had already responded to the CVE with a "security scan" feature in its April 2025 Lovable 2.0 release. It checked whether RLS policies existed but not whether they actually worked. A checkbox that created false confidence.
The broader research confirms this is not platform-specific. A Veracode study testing more than 100 LLMs found that AI-generated code contains 2.74 times more vulnerabilities than human-written code. Earlier work by Pearce et al. found that approximately 40% of GitHub Copilot outputs contained vulnerabilities from the industry's top 25 most dangerous software weaknesses. A GitGuardian analysis found that repositories using GitHub Copilot have a 40% higher rate of leaked secrets -- hardcoded API keys, passwords, tokens, and certificates embedded directly in source code.
These are not theoretical risks. In July 2025, the dating safety app Tea left its Firebase instance open with default settings, exposing 72,000 images -- 13,000 government ID photos and 59,000 images from posts, comments, and direct messages -- along with 1.1 million private messages. In February 2026, the AI-agent social network Moltbook suffered a breach when a misconfigured Supabase database exposed 1.5 million API keys and 35,000 user email addresses. A solo SaaS founder documented how embedded OpenAI API keys in his AI-built product were discovered by malicious users, resulting in thousands of dollars in unauthorized usage before the app was forced offline.
The pattern is the same every time: AI generates working code with default configurations, default configurations are insecure, and nobody who understands security architecture reviewed the output.
The canary signals
The open source community noticed the problems before the startups did.
In January 2026, Daniel Stenberg shut down the cURL bug bounty program after being overwhelmed by AI-generated submissions. By mid-2025, 95% of HackerOne reports to the cURL project were invalid. Submission volume had spiked to eight times the normal rate. Stenberg called it removing "the incentive for people to submit crap." The irony: in September 2025, a researcher using a purpose-built AI security scanner submitted roughly 50 real bugs to cURL -- what Stenberg called "actually, truly awesome findings." The difference was not the tool. It was the intent and the specification behind its use.
Mitchell Hashimoto, creator of Terraform and Ghostty, updated Ghostty's contribution policy to restrict AI-assisted pull requests to accepted issues only. Drive-by AI PRs are closed without review. Repeat offenders are permanently banned. Hashimoto's framing is precise: Ghostty itself is written with substantial AI assistance. His maintainers use AI daily. What he banned was not AI. He banned unspecified AI output: code generated without a clear understanding of what it should accomplish and how it fits into the existing system.
Open source is moving from "default trust" to "default deny" for AI contributions. Not because AI is bad, but because AI without specification produces plausible garbage at scale.
The pattern that worked
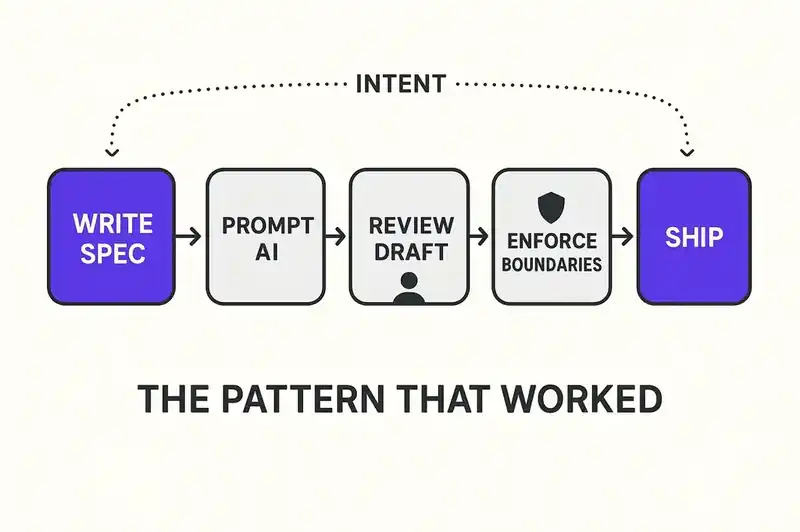
Not every startup that built with AI in 2025 is paying for a rebuild. Some shipped fast, scaled, and kept their codebases under control. They share a pattern.
They wrote specifications before they wrote prompts. Short, declarative statements of what each component does, what it guarantees, what it cannot do, and how it relates to adjacent components. The specification was the primary artifact. The code was derived from it.
They treated AI output as a draft. Every generated module went through human review focused on three questions: Does this match the specification? Does this handle failure modes? Does this duplicate logic that exists elsewhere? Teams that skipped this step saved hours per week and lost months per year.
They maintained architectural boundaries. When an AI suggested a quick fix that crossed service boundaries or added responsibilities to the wrong component, they rejected it. They had something to reject it against: a documented definition of what each component is and is not. Without that definition, every AI suggestion looks reasonable in isolation.
They version-controlled intent alongside implementation. When a specification changed, that change was tracked and reviewed independently from the code change that implemented it. The decision and the execution were separate artifacts.
They concentrated security review where it mattered. Not every module needs a security audit. But authentication, authorization, payment processing, and data storage do. Teams that flagged these domains and routed AI-generated code through additional review avoided the breaches that hit their peers.
A feature is not done when the tests pass. It is done when someone on the team can modify it six months from now without the AI that wrote it.
A framework for founders building with AI now
If you are a founder using AI coding tools today, the evidence is clear about how to avoid building a codebase that requires a $300,000 rescue in eighteen months.
Start with a specification, not a prompt. Before you ask an AI to generate anything, write down what the component does, what it should not do, and what contracts it has with other components. A paragraph works. A YAML file works. The format matters less than the existence. If you cannot articulate what you are building, the AI cannot build it correctly.
Define security-sensitive boundaries explicitly. Authentication, authorization, payment processing, data storage, PII handling. These are the domains where AI-generated defaults will fail you. Mark them and route code in these areas through human review or specialized security tooling. The 40% vulnerability rate in AI-generated code concentrates in exactly these areas.
Track architectural decisions outside the code. Why did you choose this database? Why is authentication handled by this service and not that one? Why does this API return data in this shape? These decisions will be invisible to the next developer (or the next AI agent) that touches the code. Write them down. Keep them next to the code. Version them together.
Budget for review, not just generation. The economics of AI-assisted development are not "AI writes code for free." They are "AI generates drafts quickly, and humans review and integrate those drafts." If your development process does not include review time, you are not saving money. You are deferring costs to a period when they will be larger and less predictable.
Plan for the second engineer. The moment your startup hires its second developer, or its first contractor, they need to understand the system without having been present when every prompt was written. If the only record of your system's architecture is a conversation history in Cursor, you have a single point of failure with a half-life of weeks.
Test the boundaries, not just the happy path. AI-generated code handles the normal case well. It fails on the abnormal case just as reliably. Malformed input, concurrent access, network failures, resource exhaustion, malicious users. Write tests for the edges. If you do not know what the edges are, that is a specification problem.
The honest assessment
We do not have a clean answer to this.
The rebuild problem is real. The security failures are real. Thousands of startups are discovering simultaneously that velocity without specification produces fragile, insecure, unmaintainable software.
But the answer is not to stop using AI. A two-person team can now build what previously required ten people, and that advantage is too large to abandon. Giving up AI coding tools in 2026 would be like giving up version control in 2010 because some teams used it poorly.
The answer is to treat specification as infrastructure. The primary artifact that AI reads, humans review, and systems validate against. The thing that persists when the code gets rewritten, the team turns over, and the AI models that generated the original implementation are three generations obsolete.
The 8,000 startups that need a rebuild right now let AI generate code without first defining what their software is. The startups that will not need a rebuild in 2027 will treat their specifications as the source of truth and their code as a replaceable expression of it.
The rebuild wave is here. What comes after is specification-first development, persistent intent that survives every rewrite. That is the work ahead.