
This happened at a real company in early 2026. A team of four engineers used AI coding tools to ship 47 pull requests in a single sprint. The PRs were clean. The tests passed. The CI pipeline was green. The VP of Engineering found out about three of those changes two weeks later, during an incident review, when it became clear that a new data pipeline was writing customer PII to a logging service hosted outside the EU.
Nobody made a bad decision. That is the thing. Nobody decided anything at all. The feature was requested, the agent generated the code, the code was reviewed for correctness (it was correct), and the system changed. What the system was -- its constraints, its compliance posture, its data residency commitments -- was never part of the conversation. The code was right. The decision was missing.
That is the new failure mode. Not bad code. Missing decisions.
The economics flipped and nobody updated the org chart
For most of software history, the expensive part was typing. Writing code took time, skill, and staffing. A senior engineer's value was substantially tied to the ability to translate intent into working implementation. The bottleneck was production.
That bottleneck is dissolving. AI-authored code now accounts for roughly 41% of all production code, up from negligible levels two years ago. Developers using AI tools merge 98% more pull requests per week. Google reported that 69% of internal code edits are LLM-generated. The marginal cost of producing a line of code is approaching zero.
When production is cheap, the constraint moves upstream. The scarce resource is no longer the ability to write code. It is the ability to decide what should be written. More precisely: the ability to decide what the software should become.
That is not a philosophical distinction. It is an operational one. The teams drowning right now are not drowning in bad code. They are drowning in unreviewed decisions. PRs are up 98%, but PR review time is up 91%. Teams that handled 10-15 pull requests per week are now facing 50-100. The code is fine. The governance is gone.
Two kinds of change

Every change to a software system falls into one of two categories, and the discipline of the next era is learning to tell them apart.
The first kind: a change to what the system does. A new endpoint. A performance optimization. A refactored module. A bug fix. These are implementation changes. They happen inside the boundaries of what the system already is. They are the domain of engineers and agents. They should be fast, frequent, and cheap.
The second kind: a change to what the system is. A new data residency commitment. A shift in who the software serves. A new compliance obligation. A change to a behavioral contract that downstream consumers depend on. These are identity changes. They redefine the boundaries themselves. They should be deliberate, visible, and reviewed by people who understand the business consequences.
The problem is that we have no mechanism to distinguish the two. In a codebase, both look the same: a diff. A pull request. Lines added, lines removed. The change that optimizes a database query and the change that introduces a new PII processing pipeline show up in the same review queue, subject to the same process, visible to the same audience.
When code was expensive to produce, this worked well enough. The small volume of changes meant a senior engineer could eyeball the queue and catch the ones that mattered. When code is generated at industrial scale, this collapses. You cannot distinguish signal from noise when the noise has increased tenfold and the signal looks identical to everything else.
Identity diffs
The governance mechanism: separate the layers.
An identity layer -- what we call Software DNA -- is a declarative, version-controlled specification of what the software is. Its purpose, its behavioral contracts, its constraints, its relationships to other systems. It lives alongside the code but is not the code. When something in the identity layer changes, that change produces its own diff. An identity diff.
An identity diff is categorically different from a code diff. Consider the difference:
A code diff says: "Lines 47-63 of pipeline.go were modified. A new function writeToLogService was added. The function accepts a UserEvent struct and writes it to the external logging endpoint."
An identity diff says: "The data residency constraint for this service changed. Customer PII is now transmitted to a third-party logging service outside the EU compliance boundary."
The first requires an engineer to read Go, understand the codebase, and infer the implications. The second requires a human who can read a sentence.
That is not a minor convenience. It is a structural change in who can participate in governance.
The $75 million sentence
PMI's research found that for every $1 billion spent on projects, $75 million -- 56% of the at-risk dollars -- is lost to ineffective communication. Not failed execution. Failed communication. The work got done. The wrong people found out too late, or in a form they could not parse, or never found out at all.
Software has the worst version of this problem. The artifact that records decisions -- the codebase -- is legible to maybe 20% of the people affected by those decisions. When the VP of Legal needs to understand whether a system change affects GDPR compliance, the answer lives in a pull request written in TypeScript. When the Head of Product needs to know whether a behavioral contract changed, the evidence is a 400-line diff across six files. When the CISO asks what changed since the last audit, the honest answer is "about 10,000 commits, good luck."
The communication cost is not that people do not talk. It is that the primary record of change is in a language most stakeholders cannot read. Every code review is an engineering-to-engineering conversation about a change that may have business-wide implications. The business finds out later, if it finds out at all.
Identity diffs fix this. Not because they are simpler -- because they are in a different language. They describe what the system is, not how it is built. A compliance officer can review an identity diff. A product manager can review an identity diff. A VP of Engineering can review an identity diff without reading the implementation. The change is described at the level where the decision lives.
Gartner's research on change management found that 74% of leaders say they involve employees in change strategy, but only 42% of employees feel included. The gap is not malice. It is legibility. Leaders communicate changes in forms that do not land with the people affected. Software engineering has the same gap, in the opposite direction: engineers make changes that affect the business in forms the business cannot read.
The decision layer
There is a deeper point here, about where organizational authority actually lives.
When you add something to the identity layer -- a new constraint, a new behavioral contract, a new compliance obligation -- you are making a deliberate architectural decision about what the software permanently is. "Permanently" in the software sense, meaning: this persists across implementations, across rewrites, across the next three agents that touch this codebase. A decision that affects the shape of everything built on top of it. It deserves scrutiny, sign-off, and a record.
When you add something to the codebase -- a new function, a new module, a refactored class -- you are implementing within the boundaries that the identity layer defines. This is execution. It should be fast. It should be automated where possible. It should not require a committee.
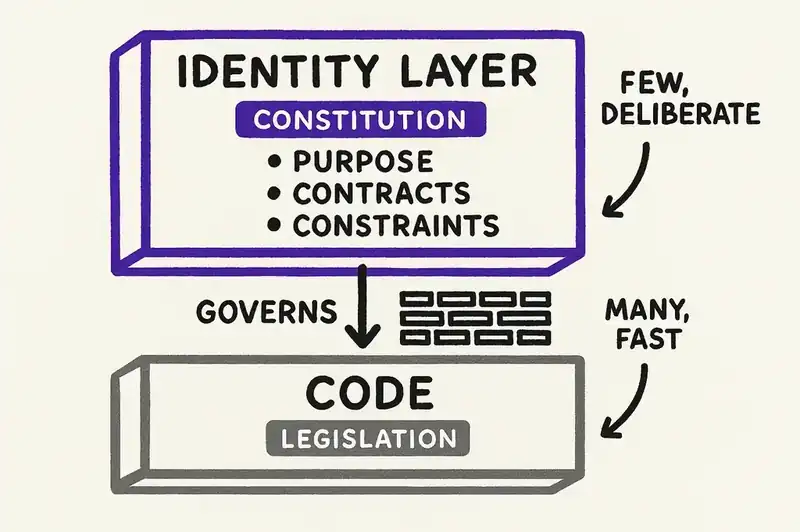
The distinction creates a natural governance model. Identity changes get reviewed by people with the authority to make architectural and business decisions. Code changes get reviewed (or auto-reviewed) for correctness against the identity. The identity layer is the constitution. The code is legislation. You do not amend the constitution every time you pass a bill, and you do not convene a constitutional convention every time someone fixes a bug.
That is how you scale governance when agents are producing code at a rate that makes human review of every line impossible. You do not review every line. You review every decision. The identity layer tells you which changes are decisions.
The compliance case is the easy case
The global GRC market hit $62.5 billion in 2024 and is projected to reach $151.5 billion by 2034. That trajectory reflects what every VP of Engineering already feels: regulatory obligations are growing faster than the ability to verify compliance against them.
The EU AI Act's high-risk system requirements take effect August 2, 2026. Colorado's AI Act enforcement begins June 30, 2026. The SEC's cybersecurity disclosure rules are already in play. Each creates an obligation that is not about code. It is about behavior, constraints, and guarantees -- the things that live in the identity layer.
Today, compliance verification looks like this: an auditor asks what controls are in place. An engineer explains the architecture. The auditor asks for evidence. The engineer points to code, tests, and maybe a stale architecture diagram. The auditor writes up findings. The whole process takes weeks and produces a point-in-time snapshot that starts decaying the moment it is complete.
With a declared identity layer, compliance verification looks like this: the auditor reads the identity spec. The constraints are declared. The data residency requirements are explicit. The behavioral contracts are versioned. The auditor can diff the identity between audit periods and see exactly what changed at the decision level, without reading a line of code. Continuous compliance becomes possible because the thing being audited -- the identity, not the implementation -- is legible to the people doing the auditing.
This is how infrastructure compliance already works in organizations that use Terraform or Pulumi with policy-as-code tools like Open Policy Agent. The infrastructure is declared. The policies are declared. Compliance is a function of comparing the two. We have not applied the same pattern to the application layer.
The rework multiplier
The requirements literature is clear on this: 50% of software rework traces to requirements issues. Fixing errors caused by vague or incomplete requirements can consume up to 40% of a project's total budget. Research on error cost escalation, including work by Boehm and subsequent studies, found that the cost to fix an error increases by roughly 10x at each stage of development -- from requirements to design to implementation to testing to production.
All of these statistics point to the same cause: the cost of making decisions implicitly rather than explicitly. When the identity of a system is implicit -- embedded in code, inferred from behavior, carried in an engineer's head -- every downstream decision is built on an assumption about what the system is supposed to be. When that assumption is wrong, you get rework. When it is right, you got lucky.
An explicit identity layer does not eliminate rework. But it converts implicit assumptions into explicit declarations that can be validated before implementation begins. The question shifts from "did we build it right?" to "did we declare it right?" -- and the second question is cheaper to answer by orders of magnitude, because the declaration is legible to everyone involved in the decision.
This matters more in an AI-generating-code world, not less. When a human writes code based on a misunderstood requirement, you get a bug. When an agent generates code based on a missing identity constraint, you get a structurally compliant, well-tested, green-CI violation of a business rule that nobody catches until production. The code is better than ever. The decisions are worse than ever. That is the paradox.
What this looks like in practice
A team operating with an identity layer has two review tracks running in parallel.
The identity track is low-volume, high-stakes. Changes to purpose, contracts, constraints, or relationships are proposed as identity diffs. They're reviewed by the people with the authority and context to evaluate them: engineering leads, product managers, compliance officers, architects. The review is fast because the diff is readable. You don't need to understand Go or Rust or TypeScript to evaluate whether adding a third-party data processor to the PII pipeline is acceptable under your GDPR obligations. You need to understand the business.
The code track is high-volume, low-ceremony. Implementation changes that operate within the declared identity are reviewed for correctness -- does this code do what the identity says the system should do? Most of that review can be automated. Agents check implementation against declared contracts. CI validates that constraint boundaries are not violated. Human review focuses on cases where the tooling flags a potential identity violation, not on every line of every PR.
The result: decision velocity stays high because decisions are concentrated in a legible, reviewable layer. Implementation velocity stays high because implementation isn't blocked by governance overhead. The VP of Engineering knows what the system is becoming because identity changes are visible at the level they operate at. The compliance team can audit without scheduling a two-week war room. The product manager can see what changed about the system's commitments without learning to read diffs.
The agent era needs a constitution
Within 18 months, the majority of code in most production systems will be generated by agents. We are already at 41%. The trajectory is clear. The teams that thrive will not be the ones that review every line of agent output. That is already impossible at current volumes.
The teams that thrive will be the ones that established what the system is -- explicitly, declaratively, in a form that agents can read and humans can govern -- and then let the agents implement within those boundaries. The identity layer is the constitution that agents operate under. Without it, every agent commit is an unreviewed decision. With it, agent commits are implementation, and the decisions were made upstream, by humans, in a language humans can read.
That is the discipline of the next era. Not "how do we write code faster?" That is solved. The discipline is: how do we decide what the software should be, and how do we make those decisions visible to everyone who needs to see them?
Adding to DNA is a decision. Adding to code is just typing.
The teams that cannot tell the difference will move fast and break things they did not know they had.