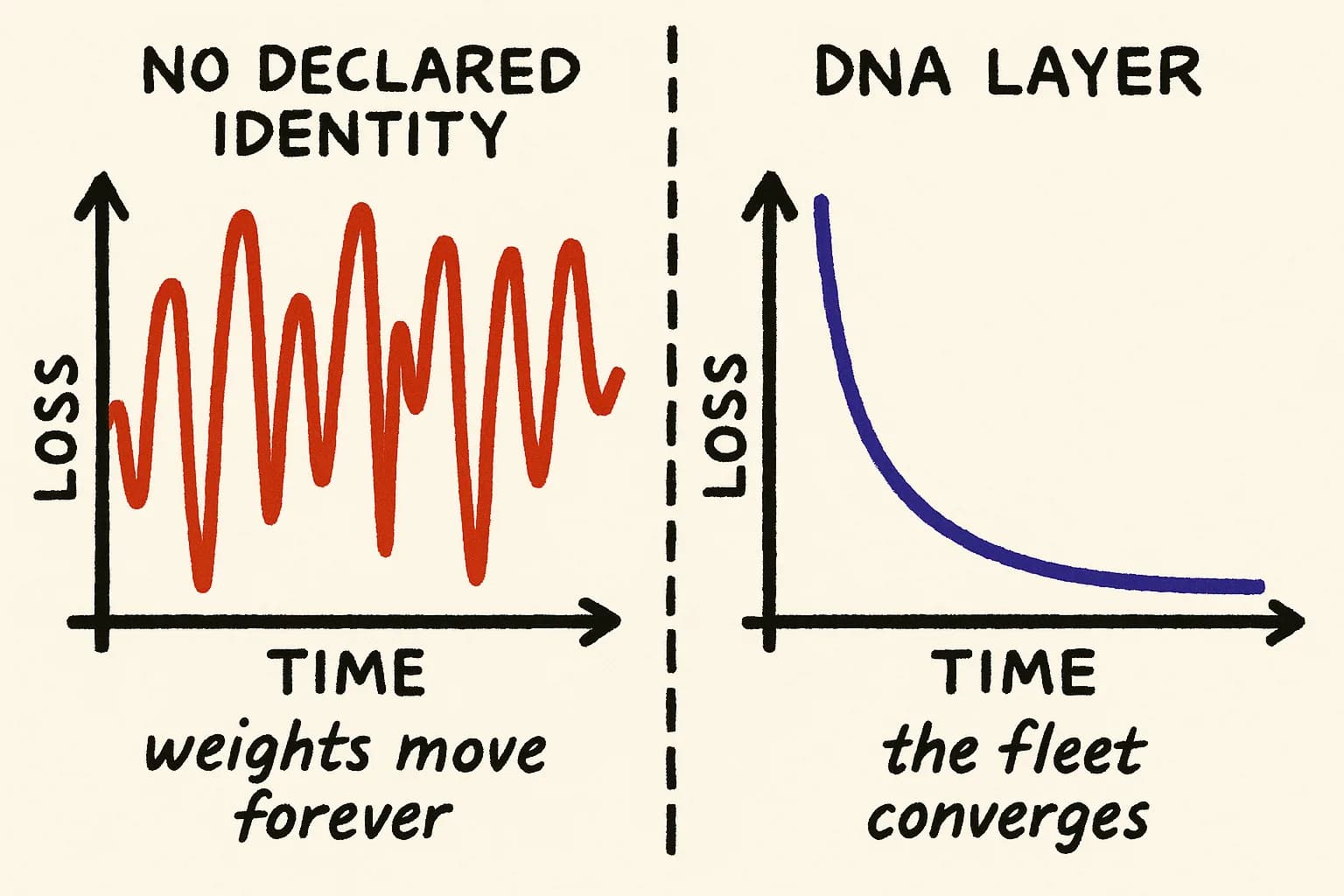
A neural network with no loss function is not a bad model. It is not a model at all. It is a pile of weights that updates forever without approaching anything. Most multi-agent development setups right now are piles of weights.
The parallel is not rhetorical. The structural requirement for convergence is the same in both domains. A learning system needs a target it can measure distance from. Without one, every update is motion without direction. You can run the process for a week, a month, a year. The parameters will change. The system will not improve.
Every fleet is a learning system, whether you designed it that way or not
A single agent editing a codebase is a tool. A fleet of agents editing the same codebase, each producing PRs, each responding to reviews, each incorporating the results of previous merges, is a learning system. It has all the structural properties of one.
- Each PR is a parameter update.
- Each merge is a gradient step that commits the update to the shared state.
- Each review comment, failing test, or rollback is a loss signal that the system uses to adjust the next update.
- The codebase is the model. The agents are the optimizer. The humans are, at best, a noisy reward channel.
The uncomfortable question most teams have not asked: what is this system optimizing toward?
If you cannot answer that in a machine-readable form — not as a slide, not as a vibes statement, not as a quarterly OKR, but as something an agent can read and check its own output against — then you are running training with no loss function. The weights move. They do not converge.
Training without a target is just oscillation

In supervised learning, the loss function is the distance between predicted output and labeled truth. In reinforcement learning, it is the negative of reward. In generative pretraining, it is next-token likelihood against a reference distribution. The mechanics differ. The requirement is invariant: a signal the optimizer can follow toward a fixed point.
Stochastic gradient descent converges under specific conditions. The loss surface must be differentiable enough to admit a gradient. The learning rate must decay. And critically, the objective must be stationary — the target cannot move faster than the optimizer can approach it.
Look at what happens in a multi-agent fleet that has none of this:
- No stationary target. Each agent has its own prompt, its own context window, its own slice of the repo. What counts as "correct" for Agent A's refactor is defined by Agent A's local view. What counts as correct for Agent B is defined by Agent B's local view. The target is not just moving — it is forking.
- No gradient. A passing test is a sparse, binary signal. A human approval on a PR is an even sparser one. The optimizer has no smooth surface to descend. It hill-climbs blindly.
- No learning rate schedule. Agents merge at whatever pace the orchestrator allows, regardless of whether earlier merges have stabilized. The equivalent of running SGD at a constant step size and wondering why the loss oscillates.
The 2025 DORA report found that high AI adoption correlated with a 9% increase in bug rates, a 91% increase in code review time, and a 154% increase in pull request size — findings echoed by Faros AI's independent telemetry analysis of more than 10,000 developers. Those numbers come from a world where most teams are still running one agent at a time. That is the one-agent loss surface. Now picture twenty.
Overfitting has always been the risk
In ML, overfitting is what happens when a model minimizes training loss without minimizing true loss. It fits the examples it has seen and fails on the ones it has not. The fix is regularization, held-out validation, and early stopping — mechanisms that penalize the model for getting too comfortable with local signal.
Agent fleets overfit constantly, and nobody calls it that.
An agent that passes every test in the suite while breaking an unstated architectural contract is overfit to the test set. An agent that refactors a module to make its own assigned task cleaner, at the cost of an interface three other modules depend on, is overfit to its prompt. An agent that produces a PR that merges cleanly and then subtly breaks a contract that was never written down is overfit to the reviewer's attention budget.
The fix is the same fix ML has used for thirty years: a validation signal that is independent of the training signal. For an agent, the training signal is the prompt and the test suite. The validation signal has to be something the agent did not write, cannot rewrite, and must be checked against before its work counts as done. A declared identity — the contracts, invariants, module boundaries, and purpose of the system — is exactly that validation signal. It is the held-out set for software.
Catastrophic forgetting is not a metaphor either
Neural networks trained sequentially on new tasks lose performance on earlier ones. Kirkpatrick et al. named this "catastrophic forgetting" and proposed Elastic Weight Consolidation: identify the parameters that matter for previously learned tasks, and penalize updates that move them. The model keeps learning new things without silently erasing old ones.
Codebases have the same failure mode. An architectural decision made twelve months ago — a module boundary, a contract, an invariant — gets silently overwritten by an agent that has no memory of why the decision existed. The test suite may not catch it, because the test was written under the old assumption and the new change is syntactically consistent. The reviewer may not catch it, because the reviewer was not in the room when the decision was made. The only thing that can catch it is a persistent representation of which parameters of the system are load-bearing and must not move without deliberate consent.
A DNA layer is EWC for a codebase. It marks which properties of the system are protected and flags any change that would move them. Not through a comment in a README, not through tribal memory, but through a machine-readable declaration that every agent reads before writing and every PR is checked against before merging.
Ensembles need a shared evaluation signal
One of the oldest results in machine learning: an ensemble of diverse models outperforms any single model, but only if the ensemble has a shared evaluation signal to combine their outputs against. Bagging, boosting, stacking — all of them depend on a loss function that is defined once, at the level of the ensemble, not separately per base learner. Without that shared signal, diversity becomes noise.
Gartner predicts that by 2027, 70% of multi-agent systems will use narrowly specialized agents. Specialization is the diversity part of the ensemble. It is cheap. Every vendor is selling it. What nobody is selling is the shared evaluation signal — the equivalent of the ensemble loss function that tells a database agent, a security agent, and a frontend agent whether their combined output is any good.
Without that, specialization does not compound. It fragments. You get a database agent that optimizes its local loss, a security agent that optimizes its local loss, and a frontend agent that optimizes its local loss, and the ensemble's actual loss — does the system do what it is supposed to do — is unmonitored.
The DNA layer is the loss function
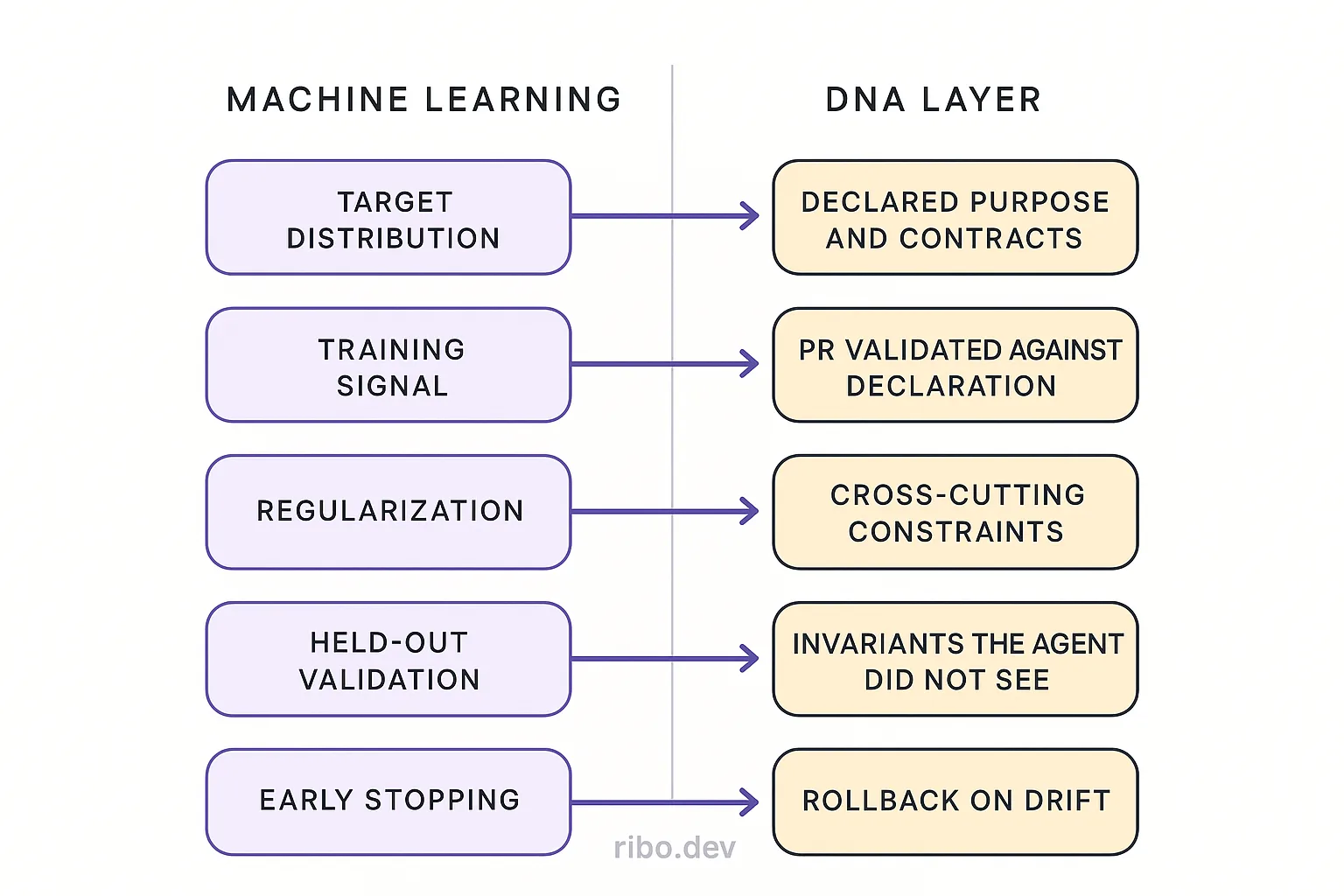
- The target distribution is what the system is supposed to be: its purpose, its contracts, its invariants, its boundaries. Declared, versioned, machine-readable.
- The training signal is each agent's output against that declaration. Does this PR honor the invariants? Does it respect the contracts? Does it preserve the boundaries? The answer is a real signal, not a vibe.
- Regularization is the constraint set: performance budgets, compliance requirements, security policies. Penalties on updates that violate cross-cutting concerns, whether or not they pass local tests.
- Held-out validation is the portion of the declaration the agent did not see while generating its change. The agent's output has to generalize across the full identity, not just the slice of it embedded in the prompt.
- Early stopping is the rollback protocol: when validation loss against the declared identity starts increasing, stop merging and investigate.
This is not a rebranding of tests, specs, or linters. Tests check examples. Linters check syntax. Specs, when they exist, tend to be prose. A DNA layer is a declaration of identity precise enough for an agent to validate against and general enough to cover behaviors no test was written for. It is the reference against which the fleet converges, or fails to.
Anthropic's 2026 Agentic Coding Trends Report describes multi-agent systems in which "an orchestrator delegates subtasks to specialized agents working simultaneously, then stitches everything together." The stitching is the part that has no theory yet. Stitching without a shared target is concatenation. Stitching against a declared identity is reconciliation.
What to do Monday
Before you add another agent to the fleet, answer four questions in writing. If you cannot, the next agent is not going to speed you up. It is going to add variance to an untrained optimizer.
- What is this system's loss function? In a form an agent can read. Not "ship the Q2 roadmap." Not "move fast." The contracts, invariants, and purpose that define what correctness means at the system level.
- What is the held-out validation set? Which properties of the system must every change be checked against, regardless of what the change is for?
- What are the protected parameters? Which architectural decisions are load-bearing, and what is the process for deliberately changing them?
- Who reads the declaration before writing? If the answer is "nobody, the prompt contains enough context," you are running local training on a global problem.
These are answerable questions. The honest answer for most teams today is that their loss function is implicit, their validation set is the production incident channel, their protected parameters live in the heads of two senior engineers, and their agents do not read anything resembling a declaration before writing. That is the current state. It is not a stable one.
Where the analogy breaks
Code is discrete. Model parameters are continuous. There is no smooth gradient in PR-space, and no clean notion of a learning rate for a fleet of agents. The math of SGD does not literally apply.
The structural requirement does. A learning system without a convergence target does not converge. A fleet of agents without a declared identity does not converge. The mechanism for reaching the target differs — reconciliation loops instead of gradient descent, policy checks instead of regularization penalties, versioned declarations instead of held-out validation sets. The requirement is the same requirement the ML community worked out a generation ago and has been refining ever since.
The industry spent the last decade learning how to train models. It is about to spend the next decade learning that a fleet of agents editing a shared codebase is the same kind of problem. The teams that figure out their loss function first are the ones whose fleets will actually converge. The rest will keep updating weights.