
In 2009, Twitter began rewriting its backend from Ruby on Rails to Scala and Java. By 2014, the migration was functionally complete. Throughput went from 200-300 requests per second per host to 10,000-20,000. The Ruby code that once powered every tweet, every follow, every DM -- all of it was gone.
Airbnb's engineers called their Ruby on Rails monolith "Monorail." By 2015, engineers were losing 15 hours per week to deployment issues caused by tight coupling in that single application. They migrated to a service-oriented architecture built primarily on Java. Monorail still exists in some vestigial form, but the code that ran Airbnb's core business for most of a decade has been largely replaced.
Uber runs roughly 4,500 stateless microservices, deployed over 100,000 times per week by 4,000 engineers. The measured half-life of an Uber microservice is 1.5 years. Every 18 months, half the codebase is replaced. Uber's engineering leadership has a term for the operational reality this creates: "migration hell."
Three of the most successful software companies of the last two decades. In each case, the code is gone. Not deprecated. Not archived. Gone. Different code, different languages, different architectures, different people.
And yet Twitter was still Twitter. Airbnb was still Airbnb. Uber was still Uber. Users didn't notice. The product worked. The contracts held.
So what survived?
The question nobody asked
The software industry treats code as the primary asset. We version it, review it, test it, measure it, celebrate it. Entire cultures have formed around how code is written -- tabs versus spaces, monorepos versus polyrepos, object-oriented versus functional. We care deeply about the artifact.
But code is the most replaceable part of a software system. It always has been. The evidence is everywhere, and we keep not seeing it.
The majority of large-scale rewrites fail to meet their goals on time, budget, and scope. But the ones that succeed -- Twitter, Airbnb, Netflix's migration from monolith to microservices, Amazon's decomposition of its original bookstore codebase -- succeed because something other than the code persisted through the transition. The behavioral contracts. The constraints. The reason the thing existed in the first place. The engineering teams that pulled off these migrations didn't preserve the code. They preserved the identity.
We didn't have good language for this until Rich Hickey gave us some.
Identity is not state
In his 2009 keynote at the JVM Languages Summit, "Are We There Yet?", Rich Hickey made a distinction that the industry has spent fifteen years failing to fully absorb. He defined identity as "a putative entity we associate with a series of causally related values over time."
Read that again. Identity is not a value. It is not a state. It is not a snapshot. Identity is the thing we point to and say "that" -- the persistent reference that connects a series of changing states into something we recognize as a coherent entity.
Hickey's point was about programming languages and immutable data. But the insight extends far beyond Clojure. Every software system has an identity that is distinct from its implementation at any given moment. Twitter's identity -- the set of behaviors, contracts, and constraints that made it Twitter -- persisted across the Ruby implementation, the Scala implementation, and whatever comes next. The implementations were values. The identity was the thread connecting them.
"The biggest problem we have," Hickey said, "is we've conflated two things. We've said the idea that I attach to this thing that lasts over time is the thing that lasts over time." Object-oriented programming taught us to fuse identity and state into a single mutable object. The result is that when the state changes -- when you rewrite the code -- you feel like you've lost the identity. You haven't. You've lost one value in a series. The identity was never the code.
The cause of causes
Aristotle would have found this obvious.
His framework of four causes -- the four ways to answer "why does this thing exist?" -- turns out to describe software systems with more precision than most software frameworks do.
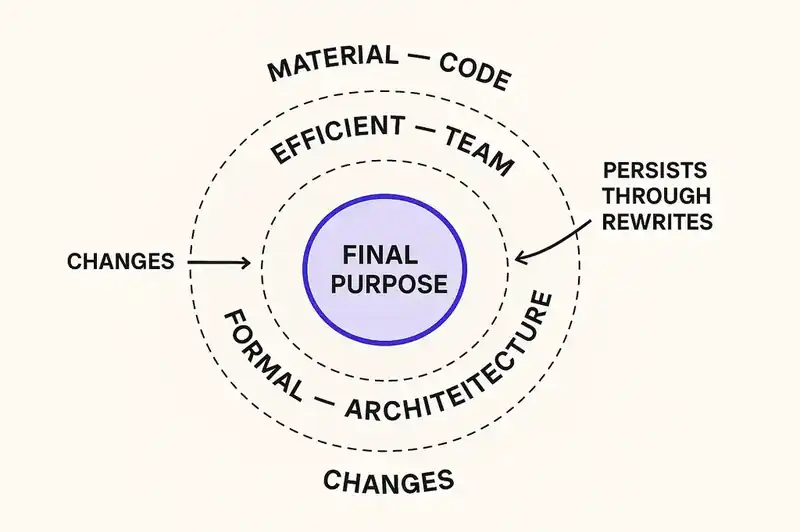
The material cause is what something is made of. In software: the code. Ruby, Scala, Java -- the specific lines and modules that constitute the implementation at a point in time.
The efficient cause is what brought it into being. The developers, the team, the organization that wrote and deployed the code.
The formal cause is its structure. The architecture -- microservices, monolith, event-driven, request-response.
The final cause is its purpose. Why it exists and for whom.
Aristotle called the final cause "the cause of causes." The purpose determines the structure. The structure determines what needs to be built. What needs to be built determines who builds it. Purpose sits upstream of everything.
When Twitter migrated from Ruby to Scala, the material cause changed completely. The efficient cause changed (different engineers wrote the new system). The formal cause changed (the architecture shifted dramatically). The final cause -- a real-time public messaging platform with specific latency, throughput, and consistency guarantees -- did not change. It's what made the migration coherent rather than chaotic. The purpose was the anchor.
Fred Brooks made a parallel observation in "No Silver Bullet" in 1986. He distinguished essential complexity from accidental complexity. The essential complexity of a software system is "a construct of interlocking concepts: data sets, relationships among data items, algorithms, and invocations of functions." The accidental complexity is everything imposed by the tools and techniques of implementation. Brooks argued that most of the hard problems in software are essential, not accidental. The choice of language, framework, and runtime -- these are accidental. The behavioral requirements, the domain constraints, the contracts with consumers -- these are essential.
Essential complexity survives rewrites. Accidental complexity is what gets rewritten.
The Ship of Theseus sails to production
The ancient thought experiment asks: if you replace every plank of a ship, one at a time, is it still the same ship? Philosophers have argued about this for two thousand years. Software engineers answer it every day without realizing it.
Every deployment is a partial replacement. Every refactor swaps planks. Every migration replaces the hull. And yet we keep calling it the same system, because it maintains the same contracts, serves the same consumers, and fulfills the same purpose.
Domain-Driven Design gives us precise vocabulary for this. In Eric Evans' framework, an Entity has identity that survives changes to its attributes. A Value Object is defined entirely by its attributes -- change one and it's a different object. The ship is an Entity. The planks are Value Objects. The ship's identity isn't a function of any particular plank, or even all the planks together. It's the continuity we assign to the thing across time.
Code is a Value Object. It has no identity of its own. It is defined by its content. Change a line and it's a different artifact. The system the code implements is an Entity. Its identity persists across changes to the material.
This is not a metaphor. This is literally how version control works. Git tracks content, not identity. Every commit is a new snapshot -- a new value. The branch name, the repository, the deployment target -- these are the identity references that give coherence to the series of values over time. We already have the mechanism. We just haven't recognized what it implies about where the real asset lives.
The law of continuous change
Meir Lehman saw this coming in 1974.
His Laws of Software Evolution, refined over three decades of empirical research, describe the dynamics that govern real-world software systems. Two of them matter here.
First: a system used in the real world must be continuously adapted, or it becomes progressively less satisfactory. Software that doesn't change dies. Not eventually. Continuously.
Second: as a system evolves, its complexity increases unless explicit work is done to maintain or reduce it.
These two laws together create a ratchet. You must change the software to keep it alive. But every change increases complexity unless you actively fight entropy. The result is that every sufficiently long-lived system eventually reaches a complexity threshold where a rewrite becomes cheaper than continued modification.
This is why Twitter rewrote. This is why Airbnb rewrote. This is why Uber's microservices have a half-life instead of a lifespan. Lehman's laws guarantee that code is temporary. The only question is how long "temporary" lasts.
But notice what Lehman's first law actually says. The system must be continuously adapted. Not the code. The system. The identity of the system -- its purpose, contracts, and constraints -- is what must remain satisfactory. The code is the medium through which adaptation happens. And mediums are, by nature, replaceable.
What protocols teach us
If code is ephemeral, what is permanent?
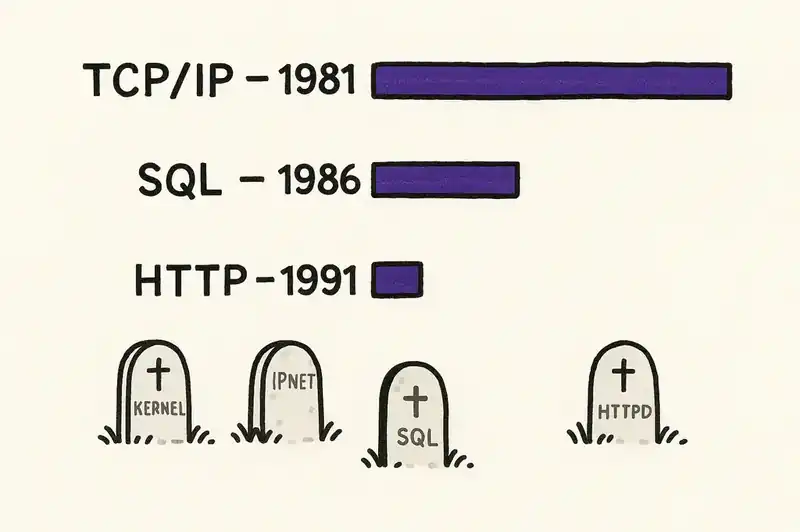
Look at what persists. TCP/IP was specified in 1981. Every implementation has been rewritten many times over. The protocol persists. SQL was standardized in 1986. The databases that implement it -- Oracle, PostgreSQL, MySQL, SQLite -- share almost no code. The language persists. POSIX was formalized in 1988. Implementations span from ancient Unix machines to the macOS kernel running on your laptop right now. The interface persists.
This is the Lindy Effect applied to software: the things that have lasted longest are most likely to continue lasting. And the things that last are never implementations. They're specifications, contracts, interfaces -- declarations of behavior that any number of implementations can satisfy.
HTTP is 35 years old. No line of code from the original CERN implementation survives. The protocol runs roughly half the world's economy. The x86 instruction set has been maintained for over four decades while the silicon underneath has been redesigned from scratch at least a dozen times. The instruction set -- the contract between software and hardware -- is the persistent layer. The transistors are the planks.
The pattern is so consistent it's strange that we haven't built our entire practice around it. What survives is always declarative. What, not how. Behavior, not implementation.
Code reaches post-scarcity
Everything above has been true for decades. But now there's a forcing function.
When Andrej Karpathy coined "vibe coding" in February 2025, he was naming something bigger than a development technique. He described code as "free, ephemeral, malleable, discardable after single use." He vibe coded entire throwaway applications just to find a single bug -- because why not? Code is free now.
By end of 2025, Karpathy had moved past even that framing. He dropped "vibe coding" for "agentic engineering" -- a model where "you are not writing the code directly 99% of the time, you are orchestrating agents." The code is still there. You just don't touch it.
Google reported that 69% of code edits internally are now LLM-generated, and that AI assistance cut migration time by 50%. This isn't a forecast. This is what one of the world's largest engineering organizations looks like today.
Greg Brockman, co-founder of OpenAI, posted the bluntest version: "Code is a liability, not an asset. So the goal of software engineering is delivering the maximum amount of desired functionality at the cost of the least amount of code complexity, even as desired functionality evolves over time."
Google's own Software Engineering at Google book said something similar years earlier: "Code itself doesn't bring value: it is the functionality that it provides."
If code is a liability, and AI makes producing code nearly free, the cost of the liability drops. Fine. But the value of the liability was always zero. Code was never the asset. The asset was the thing the code implemented -- the behavior, the contracts, the constraints, the purpose.
When producing code is cheap, the question shifts from "how do we write this?" to "what should this be?" The specification becomes more valuable than the implementation. The specification is what you hand to the next agent, the next team, the next rewrite. The implementation is disposable by design.
The bus factor is an identity problem

Avelino et al. studied open-source projects and found that 65% have a bus factor of two or fewer. Two people. If two people leave, the project's continuity is at risk. Not because the code disappears -- it's sitting in a repository. Because the knowledge of what the code is supposed to do, why it was built that way, and what constraints it must honor lives in those two people's heads.
This is an identity problem dressed up as a staffing problem. The bus factor measures how many people carry the identity of the system in their heads. When that identity is implicit -- embedded in code, scattered across commit messages, half-remembered from a design review eighteen months ago -- it's fragile. It walks out the door when people do.
Every engineering leader has lived this. A senior engineer leaves, and the team spends weeks reverse-engineering intent from implementation. Not because the code is badly written. Because code, no matter how well written, expresses how. The why -- the purpose, the constraints, the contracts, the relationships -- was never written down in a form that could survive the departure.
This was tolerable when teams were stable and code was expensive to produce. You could afford to keep identity in people's heads because the people stuck around and the code didn't change much. Neither of those conditions holds anymore. Team tenure is shorter. Code is being generated at industrial scale. The identity-in-heads model is failing at a rate proportional to the acceleration of everything else.
Declare what persists
If you accept the argument -- that code is the ephemeral part and identity is what persists -- then the practical implication is direct.
Declare the identity.
Not in a wiki. Not in a README that nobody updates. Not in a Confluence page that requires three clicks and a prayer to find. Declare it in a form that is version-controlled, machine-readable, and enforceable.
What does that mean in practice? The purpose -- what this system is, what it isn't, why it exists. The contracts -- what it guarantees to its consumers, in terms specific enough that a machine can validate them. The constraints -- what it must honor regardless of what features ship or what language the next version is written in. The relationships -- what it depends on, what depends on it, what breaks if something changes.
None of this is new. Architects declare buildings before building them. Electrical engineers declare circuits before fabricating them. Mechanical engineers declare tolerances before machining parts. Every engineering discipline that builds physical things puts the specification upstream of the implementation.
Software reversed the order. We build first and describe later, if ever. The result is that the most important information about a software system -- its identity -- exists only as an emergent property of the code. You can derive it, if you read carefully enough, for long enough. But it was never stated directly. And when the code is replaced, the derivation has to start over.
The shift is to put the identity first. Declare what the system is. Let the implementation be generated, rewritten, migrated, replaced. The implementation is the plank. The declaration is the ship.
What this is really about
We're not arguing that code doesn't matter. Code is how software works. It's the material cause, and materials matter. A bridge made of cardboard is a bad bridge.
But we are arguing that the industry's center of gravity is wrong. We invest enormous energy in the artifact that changes most frequently and least energy in the specification that should change least. We have sophisticated tools for writing, reviewing, testing, and deploying code. We have almost nothing for declaring, versioning, and enforcing the identity of the system the code implements.
When a system is rewritten, the rewrite succeeds or fails based on whether the team correctly preserved the identity through the transition. Not the code. The identity. Twitter's rewrite succeeded because the engineers understood the behavioral contracts well enough to re-implement them. The 70% of rewrites that fail? Somewhere in the translation, identity was lost. A contract was violated. A constraint was forgotten. A purpose was misunderstood. The code was fine. The identity wasn't preserved.
When an AI agent generates code, the quality of the output depends on the quality of the specification it was given. Not the prompt -- the specification. The declared purpose, contracts, constraints, and relationships that tell the agent what the code should be, not just what it should look like. The teams getting the best results from AI coding tools are the teams with the clearest specifications. That's not a coincidence -- it's the whole point.
When an engineer leaves and takes implicit knowledge with them, what's lost is not the ability to write code. It's the understanding of what the code should be. If that understanding were declared, versioned, and maintained independently of the code, the departure would be a staffing event. Instead it's a knowledge crisis.
Code is ephemeral. It always was. The migration histories prove it. Lehman's laws predict it. The economics of AI guarantee it.
The question was never how to write better code. The question was always what survives when the code is replaced.
Identity is permanent -- or it should be. For most software systems right now, identity is as ephemeral as the code, because it was never separated from the code in the first place. It lives in heads, in stale wikis, in tribal knowledge that evaporates on a two-week notice period.
That's the problem worth solving.