
Ask a product manager how a feature works and you will hear one of two answers. "Check the spec" (last updated before the feature shipped) or the honest one: "You'd have to ask an engineer to look at the code."
That last answer has become so normal that nobody questions it. The code is the source of truth. Everyone says it. It sits alongside "use version control" and "don't deploy on Fridays" in the unwritten canon of software development.
But it is not a law. It is a surrender. The code did not earn the title of source of truth. It inherited the title by default, because every other candidate failed first.
The accidental source of truth
Rewind to the start of any project. Someone writes a spec. For a brief window -- maybe a week, maybe two -- the spec and the code agree. Then the first change request comes in. The code adjusts. The spec does not. Within weeks, the spec describes a system that no longer exists. Within months, it is actively misleading. Within a year, nobody references it at all.
Documentation follows the same arc. Someone writes a wiki page explaining the billing module. Then the billing module gets refactored. The wiki page does not. Google's DORA research program, surveying over 32,000 professionals across multiple years, found that teams with quality internal documentation see 25% higher performance. Most teams don't have it. The ones that do gain a measurable edge that compounds over time.
Then there is tribal knowledge, the understanding that lives in people's heads. The senior engineer who knows why the retry logic uses three attempts instead of five. The architect who remembers that the payment gateway timeout was negotiated with the vendor after six weeks of production failures. This knowledge is real and irreplaceable, but it is attached to a person whose median tenure in the industry is less than two years. When that person leaves (and 69% of software developers stay fewer than two years at a job) the knowledge leaves with them.
Every artifact that could serve as a source of truth failed. The spec drifted. The docs rotted. The tribal knowledge walked out the door. The code survived because it is the one artifact that actually runs. But surviving is not the same as being correct.
What code actually tells you
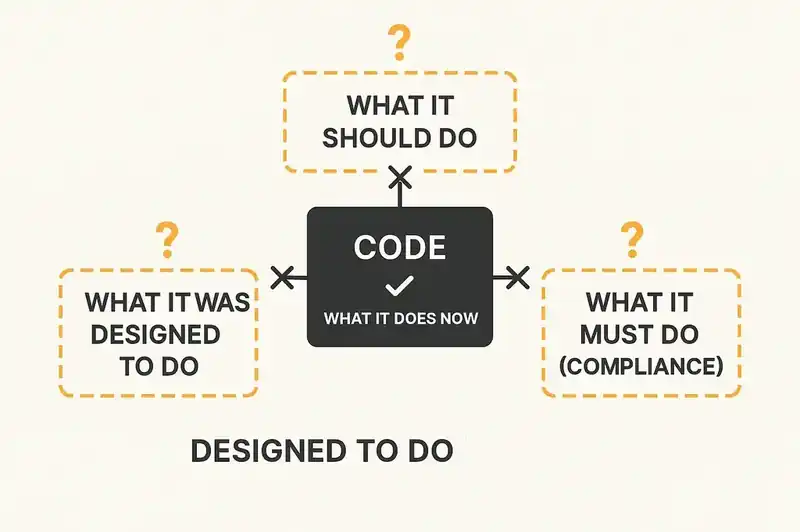
Code tells you what the software does right now. That sounds like a source of truth until you think about what it leaves out.
It does not tell you what the software should do. A bug is in the code. A half-implemented feature is in the code. A feature flag that was turned on in the configuration but never wired into a user-facing entry point -- that is in the code. The code treats all of these the same way. It executes them without distinction. There is no marker in the source that says "this is intentional" versus "this is a mistake we haven't fixed yet."
It does not tell you what the software was designed to do. The original architect had a mental model that influenced the structure, the naming, the separation of concerns. That model was never written down in a way that survived the architect's departure. Two years and four engineers later, the code reflects pragmatic decisions layered on top of a design nobody fully remembers.
It does not tell you what the software needs to do next quarter for compliance. A regulatory requirement demands that all API endpoints log access events. The code can tell you which endpoints currently log. It cannot tell you that all of them must log, or that the three that don't are violations, or that the deadline is ninety days away.
Code is an implementation. It captures the what. It does not capture the why, the should, or the must. Once a system gets large enough, the what without the why is a puzzle missing half its pieces.
"Just ask the engineer" -- and the interpretation problem
When product needs to understand how something works, the default workflow is to ask an engineer. That engineer opens the codebase, reads the relevant modules, and provides an interpretation.
But it is an interpretation, not a reading. The engineer filters the code through their own context -- what they remember about the original design, what they know about recent changes, what they assume about intent. A different engineer, reading the same code, will produce a different interpretation. Neither is wrong. Both are incomplete.
Anyone who has been in a meeting where two senior engineers disagree about how a feature works, while looking at the same code, has watched this play out. The code is not ambiguous because it is poorly written. It is ambiguous because implementation details do not carry intent. A function named processPayment might handle refunds, partial captures, currency conversion, and fraud checks. The name tells you nothing about which behaviors are intentional, which are vestigial, and which are bugs that happen to produce correct output most of the time.
The popular counterargument is "just use AI to understand the codebase." But AI reads what is written, not what is intended. If the code has a bug, the AI will describe the bug as a feature. If a feature flag gates something that should be accessible to users but the entry point was never connected, the AI will report it as correctly gated. AI can tell you what the code does. It cannot tell you what the code should do. It has the same limitation as the code itself -- it can only work with the implementation, and the implementation is not the intent.
How agile made this worse (on purpose)
The Agile Manifesto, written in 2001, includes the principle: "Working software over comprehensive documentation." This was a fair correction. Waterfall-era specifications ran to hundreds of pages and were outdated before the ink dried.
But the correction left a vacuum. James Grenning, one of the Manifesto's authors, later clarified: "Our intention was not to imply that teams shouldn't produce any documentation." Yet that is exactly how most teams read it. The phrasing, "one thing over another," became "one thing and not the other." Documentation became associated with waterfall. Agile teams shipped working software. The code was the artifact that mattered.
Agile was right that heavyweight documentation does not work. But it never answered the question it raised: if not comprehensive documentation, then what? For twenty-five years, the implicit answer has been "the code, plus whatever is in people's heads." That worked, barely, when teams were small and turnover was low and every line of code was written by a human who could explain it.
It does not work when AI generates 41% of committed code. It does not work when the engineer who understood the intent left two sprints ago and took 42% of the role-specific knowledge with them. It does not work when the team that inherits the codebase is reading an implementation that nobody alive can fully interpret.
The distinction nobody makes
We have conflated two different things.
There is what the code is -- the current implementation, with all its bugs, shortcuts, half-finished migrations, and forgotten TODOs. And there is what the code should be -- the intended behavior, the contractual obligations, the compliance requirements, the design constraints.
When you treat the code as the source of truth, you lose the ability to distinguish between these two. A bug is not a bug if the code is the source of truth -- it is just "how it works." A missing feature is not missing -- it is just "not implemented yet." A compliance gap is not a gap -- it is invisible, because there is nothing to measure the implementation against.
This conflation has a practical consequence: you cannot ask "is this code correct?" Correct relative to what? If the code is the only artifact, there is no reference point. The code is correct by definition, because the code is all there is.
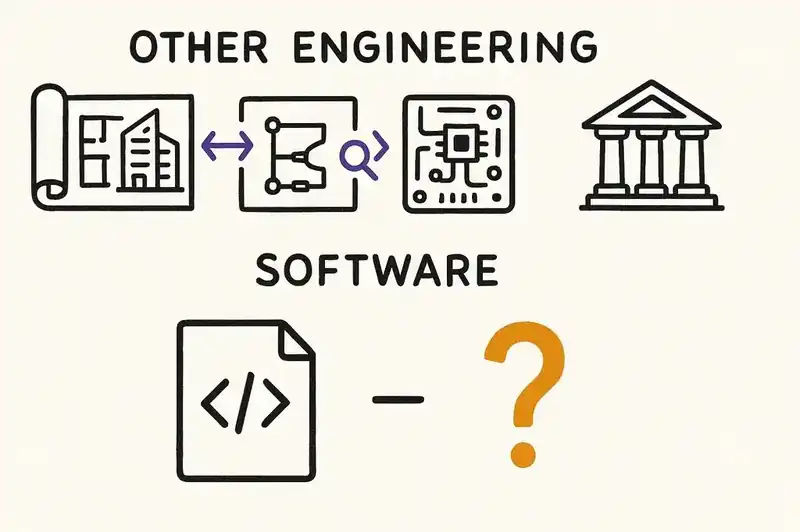
Every other engineering discipline separates the declaration from the implementation. A building has blueprints. A circuit has schematics. A legal system has statutes. The blueprints say what the building should be. The building is what was actually constructed. When they differ, you have found something worth investigating. The difference is visible and measurable.
Software has no equivalent. The implementation and the intent are fused into a single artifact. And when they are fused, drift is invisible. You cannot see the gap between what the system does and what the system should do, because "what it should do" was never declared independently of "what it does."
The scenarios where it breaks
The abstract argument is fine. The failures are what keep people up at night.
"Do we support X?" Product asks whether the system supports multi-currency. An engineer investigates and reports back: "Technically yes -- there's a feature flag for it. But it was never enabled in production, and the checkout flow doesn't pass the currency parameter." The code says yes. Production says no. The answer depends entirely on which artifact you trust and which engineer you ask.
"Are we compliant?" A compliance audit asks whether all API endpoints log access events. An engineer checks the five endpoints they are familiar with. All five log correctly. Three endpoints they did not check -- built by an engineer who left last year -- do not log at all. The code is partially compliant. Nobody knows which parts. The audit finds out the hard way.
"How does this service work?" A new engineer joins, reads the codebase, and builds a mental model. That model is wrong in a dozen places because the code contains bugs the team has been working around for months. The workarounds are in Slack threads, not in the code. The new engineer does not know the workarounds exist. The code taught the wrong lesson.
"Generate code consistent with our patterns." An AI agent reads the codebase and produces new code that follows existing conventions. One of those conventions is an anti-pattern the team agreed to stop using six months ago but never cleaned up. The AI perpetuates the mistake because the code says it is correct. The code is the source of truth, and the source of truth contains the error.
Each scenario has the same root cause. The code is carrying a job it was never designed to do. We have asked it to be a specification, a compliance record, an onboarding guide, and an architectural document. It is bad at all of those jobs, because none of them are its purpose.
The actual source of truth
Code should remain a source of truth. It is the authority on what the system currently does. That is what code is for. The question is whether it should be the only source of truth, whether the implementation should also serve as the declaration of intent.
The answer, once you frame it that way, is obviously no.
What is needed is a separate layer: a persistent, machine-readable declaration of what the software should be. Its purpose. Its behavioral contracts. Its constraints. A declaration of the intent behind the code, maintained as a first-class artifact that exists independently of any particular implementation.
When you have that layer, the source of truth shifts. The declaration says what the software should be. The code says what it currently is. The gap between them is visible and measurable. "How does this feature work?" now has two answers: "Here is what the identity declares" and "here is what the code does." If those differ, you have found something worth investigating.
Product can query the identity layer directly without waiting for an engineer's interpretation. Compliance can audit against declared constraints without reverse-engineering the implementation. New engineers can understand the system's purpose and boundaries before reading a single line of code. AI agents can generate code that aligns with declared intent, not just existing patterns, including the patterns that should have been retired.
The recognition
None of this is new. You have felt the friction of code-as-truth even if you never had a name for it. A product manager asks a straightforward question about the system and the answer requires a three-day investigation by a senior engineer. An incident responder stares at an unfamiliar service with no documentation, no spec, and no one awake who built it. Due diligence on an acquisition reveals that the entire system's architecture lives in two people's heads, and both have retention packages that expire in six months.
We built a trillion-dollar software ecosystem on the implicit assumption that code could carry the full weight of institutional knowledge. It carried it for decades, not because it was good at the job, but because there was nothing else.
The code was never the source of truth. It was just the last thing standing.