
Context engineering is the hottest term in AI development right now. Tobi Lutke named it in June 2025. Andrej Karpathy endorsed it days later, calling it "the delicate art and science of filling the context window with just the right information for the next step." Anthropic, LangChain, and half the AI tooling ecosystem published guides on it within weeks. By late 2025 it had its own conference tracks, its own job titles, its own emerging canon.
The term caught fire because it names something real. The shift from crafting individual prompts to engineering the full information environment around an LLM call -- retrieval, tool definitions, memory, state, few-shot examples -- is a genuine advance. It turned a parlor trick into a discipline.
It is also insufficient.
What context engineering gets right
Context engineering solved a real problem: the gap between what a model knows and what it needs to know to be useful on a specific task.
Prompt engineering was a naming trick for guessing which words make the model do what you want. Context engineering replaced that with systems thinking. Instead of hoping a clever prompt would suffice, engineers started building pipelines: RAG for retrieval, MCP for tool access, memory systems for conversation history, dynamic few-shot selection for pattern matching. The inputs became engineered artifacts, not afterthoughts.
This matters. A model generating code without your repository's conventions produces plausible garbage. A model with your file structure, type definitions, test patterns, and recent commit history in its context window produces something you can actually use. The difference between "AI that demos well" and "AI that ships" is almost entirely a context engineering problem.
Karpathy was right to draw the line. Prompt engineering asks: what do I say? Context engineering asks: what does the model need to see? The second question is harder, more consequential, and more amenable to systematic improvement.
That is all real progress. But it is also where the ceiling starts to show.
The comparison
Before we go deeper, here's the distinction in concrete terms. This table is the argument in compressed form.
| Dimension | Context engineering | Identity engineering |
|---|---|---|
| Scope | Single inference call | Entire software lifecycle |
| Persistence | Ephemeral -- rebuilt per request | Durable -- versioned, stored, reconciled |
| What it defines | What the model sees right now | What the software is and should be |
| Who governs it | The developer running the session | The organization that owns the software |
| Drift detection | None -- context is consumed and discarded | Continuous reconciliation against implementation |
| Cross-agent consistency | No guarantee -- each session builds its own context | Shared source of truth across all agents and tools |
| Compliance enforcement | Per-session, if someone remembers to include it | Declarative constraints enforced at the layer level |
| Analogy | The query you run against a database | The schema that makes the query meaningful |
| Failure mode | Wrong information in, wrong output out | No identity declared, no way to verify any output |
The rest of this piece unpacks why this distinction is structural, not semantic.
Where context engineering fails
Context engineering has three failure modes that no amount of optimization within the paradigm can fix. They aren't bugs. They're architectural limits.
No persistence. Context is assembled for a single inference call and then discarded. The next call starts from scratch. The next agent starts from scratch. The next team member starts from scratch. Every context window is a fresh negotiation between the engineer and the model, and nothing from prior negotiations carries forward unless someone manually rebuilds it.
This means that two agents working on the same codebase can receive completely different contexts and produce contradictory outputs. Both outputs are "correct" relative to the context they received. Neither is correct relative to what the software is supposed to be, because no persistent definition of "supposed to be" exists for either agent to reference.
No governance. Context engineering delegates authority to whoever assembles the context. If a developer includes the security constraints, the model honors them. If a developer forgets -- or never knew about them -- the model generates code that violates policies it was never told about.
This is fine for an individual writing a script. It is not fine for an organization with 200 engineers, 15 repositories, and regulatory obligations that take effect in months. The EU AI Act's high-risk enforcement arrives August 2, 2026. Colorado's AI Act enforcement begins June 30, 2026. These deadlines don't care whether someone remembered to paste the compliance requirements into the context window.
No reconciliation. Context engineering has no mechanism for detecting whether the output is consistent with anything beyond the immediate session. Did the generated code violate an architectural boundary? Did it duplicate logic that exists elsewhere? Did it introduce a dependency that conflicts with an organizational constraint? The context window doesn't know, because the context window contains whatever someone chose to put in it, not what the software actually is.
These are not edge cases. They are the default behavior of every context-engineered system in production today.
The database analogy
The clearest way to think about it is a database.
Context engineering is the query. Identity engineering is the schema.
When you query a relational database, you write SQL against a schema. The schema defines what tables exist, what columns they contain, what types are enforced, what relationships hold between entities. The schema is persistent. It was there before your query. It will be there after. Every query runs against the same schema, which means every result is interpretable within the same structural frame.
Now imagine querying a database with no schema. You send a request. You get data back. The data might be correct. It might be garbage. You have no way to tell, because there's no structural definition to validate against. Every query is an isolated act of faith.
That's context engineering without identity engineering. You assemble information for the model. The model produces output. The output might be consistent with what the software is supposed to be. It might not. You have no persistent structural definition to check against, so "correct" means "looks right to the person who assembled the context." That's a dangerously low bar for systems that handle money, health data, or infrastructure.
A schema doesn't replace queries. You still need to write good SQL. But without the schema, the queries are meaningless. Context engineering is the discipline of writing good queries. Identity engineering is the discipline of building and maintaining the schema.
The ETH Zurich finding
In February 2026, researchers at ETH Zurich published "Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?" (Gloaguen, Mundler, Muller, Raychev, and Vechev). The study tested 138 repository instances across 5,694 pull requests. The agents included Claude Code with Sonnet-4.5, Codex with GPT-5.2 and GPT-5.1 mini, and Qwen Code with Qwen3-30B.
The headline result: LLM-generated AGENTS.md files -- the context files that teams auto-generate to help their agents understand a codebase -- reduced task success rates by an average of 3% compared to providing no context file at all. They also increased inference costs by over 20%.
Read that again. The industry's most popular approach to giving agents codebase context made them perform worse and cost more.
Human-written context files fared better: a 4% average improvement. But the gap between human-written and auto-generated tells you something critical about the nature of the problem. The value wasn't in the volume of context. It was in the judgment behind what to include and what to omit. A human who understands the codebase can identify the non-obvious constraints, the unusual tooling, the conventions that aren't inferable from the code itself. An LLM generating a context file about itself produces verbose, unfocused instructions that compete with the actual task for attention.
The researchers found the mechanism: when a 4,000-token instruction file sits alongside a 2,000-token task description, roughly two-thirds of the model's attention budget goes to instructions, not the work. More context, worse performance. The ETH Zurich team's recommendation was blunt: omit LLM-generated context files entirely. Limit human-written instructions to non-inferable details.
This is a finding about context engineering's ceiling. You can optimize what goes into the context window. You can trim, filter, rank, and dynamically select. But the window is finite, the cost is real, and more information demonstrably degrades performance past a threshold that teams hit routinely.
Context engineering treats the context window as the primary site of intelligence. The ETH Zurich study shows that the context window is a bottleneck, not a solution.
The distinction sharpened
Context and identity operate at different architectural layers. Conflating them is the source of most of the confusion in this space.
Context is what you feed the model right now. It's the contents of the context window for a single inference call: retrieved documents, tool definitions, conversation history, system prompts, user instructions. It's assembled dynamically, consumed once, and discarded. It changes per request. It has no memory across sessions. It's optimized for the immediate task.
Identity is what the software is and should be, persistently. It's the declaration of purpose, behavioral contracts, constraints, compliance requirements, and system relationships that define a piece of software independent of any single interaction. It's versioned, stored, and reconciled against the actual implementation continuously. It doesn't change because someone started a new chat session.
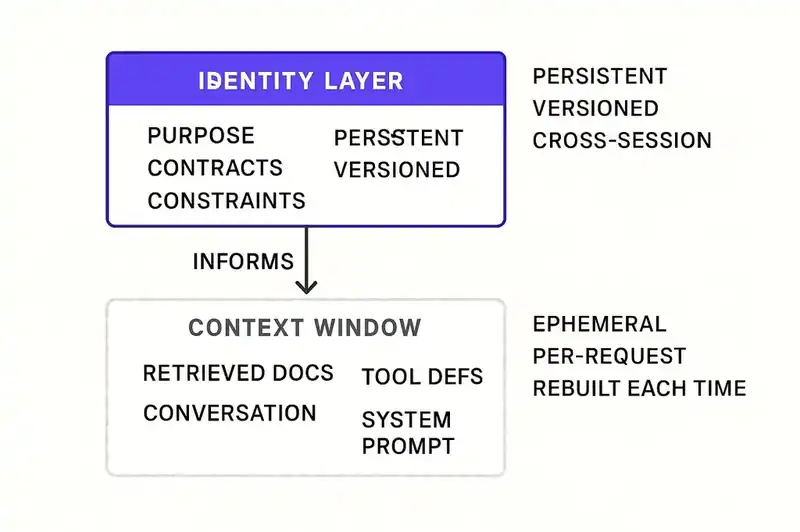
Context engineering is the discipline of assembling the right information for a single model call. Identity engineering is the discipline of defining, persisting, and enforcing what the software is across all model calls, all agents, all tools, all team members, and all time.
They are not competing approaches. Identity sits above context in the stack. Identity informs context. When an agent needs to generate code for a payment service, the context should include the service's identity: its purpose, its contracts, its constraints. But the identity has to exist before the context can reference it. Without a persistent identity layer, context engineers are forced to reconstruct intent from scratch every session, from scattered documentation, tribal knowledge, and whatever happens to be in the developer's head at the time.
That reconstruction is lossy. It varies by person. It degrades as teams grow. It fails completely when the original authors leave.
What identity engineering adds
Identity engineering solves the three failures that context engineering cannot.
Persistence across sessions. A declared identity layer doesn't reset when someone closes a terminal. It's a versioned artifact -- checked into source control, readable by any agent, any tool, any team member. The third developer to touch the codebase sees the same identity as the first. The agent running at 3 a.m. in CI sees the same identity as the developer running a local session at 2 p.m.
Organizational governance. Constraints declared at the identity level are enforced regardless of who assembles the context. A compliance requirement in the identity layer isn't optional. It isn't dependent on someone remembering to paste it into a prompt. It's structural. It applies to every interaction, every agent, every session. Governance moves from "we hope people follow the rules" to "the rules are encoded in the layer that agents read before generating anything."
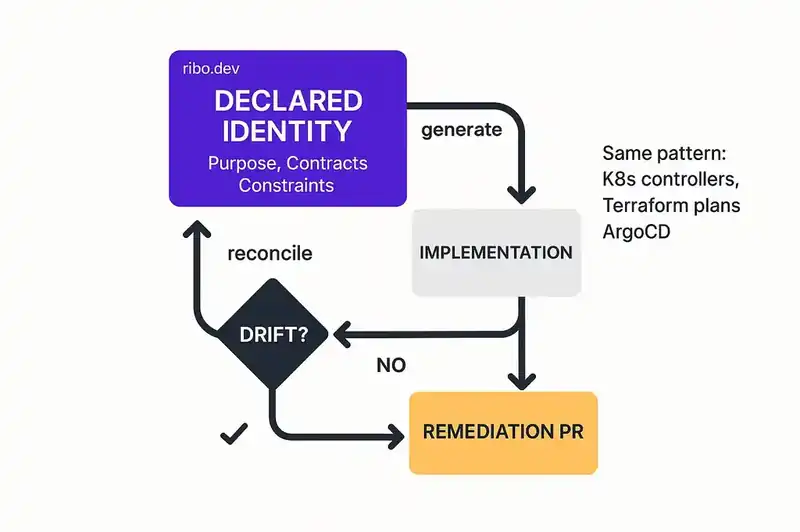
Continuous reconciliation. An identity layer enables drift detection. If the declared identity says the service handles payments and nothing else, and an agent generates code that handles user profiles, the delta is detectable. Not after a code review. Not after a production incident. At the point of generation, or at the point of commit, because the reconciliation loop compares implementation against identity continuously.
This is the pattern that won for infrastructure. Kubernetes controllers reconcile actual state against desired state. Terraform plans detect drift between declared configuration and deployed resources. The pattern works. It works because desired state is declared, persistent, and machine-readable. Apply that pattern to the software itself -- not just the infrastructure it runs on -- and you get identity engineering.
Context engineering is necessary. It is not sufficient.
We want to be honest about where the line is.
Context engineering is a real discipline that solves real problems. Assembling the right information for a model call is non-trivial. RAG, dynamic tool selection, memory management, token optimization -- these are hard engineering problems with meaningful solutions. Nothing in this piece argues that context engineering is wasted effort.
The argument is that context engineering operates within a session. Identity engineering operates across sessions. Context engineering optimizes the query. Identity engineering defines the schema. You need both. But the industry is pouring resources into one while barely acknowledging the existence of the other.
The trajectory is predictable. Context engineering will continue to improve. Context windows will get larger. Retrieval will get smarter. Token costs will fall. MCP servers will proliferate. And teams will still struggle to maintain consistency across agents, enforce compliance across sessions, and prevent drift across time -- because those are not context problems. They're identity problems.
A larger context window doesn't help if you have no persistent definition to put in it. A better RAG pipeline doesn't help if the source documents are stale, scattered, and contradictory. A smarter tool selection algorithm doesn't help if the constraints governing tool usage aren't declared anywhere a machine can read.
The next wave of AI-assisted development will not be defined by who builds the best context pipeline. It will be defined by who builds the persistent identity layer that every context pipeline reads from.
A practical path
If you're convinced that identity engineering matters -- or even just curious enough to test the hypothesis -- here's where to start. No tooling required. Just decisions.
Declare purpose and boundaries for one service. Pick your most important production service. Write down what it does and what it doesn't do. Not a README. Not documentation. A declaration of identity: this service processes payments. It does not manage user profiles. It does not send notifications. Boundaries prevent the scope creep that agents accelerate by default.
Extract your implicit constraints. Every team has unwritten rules. "We don't use that ORM." "All database access goes through the repository pattern." "PII never leaves this service boundary." These constraints live in people's heads. Write them down in a form that agents can read -- as constraints, not suggestions.
Version the identity alongside the code. The declaration lives in the repository. It's reviewed like code. It's versioned like code. When it changes, the change is visible, reviewable, and deliberate. A constraint change is a decision, not an accident.
Reconcile, don't just declare. A declaration that nobody checks is documentation by another name. Build a check -- even a manual one -- that compares the declared identity against the actual implementation. Does the service still honor its boundaries? Do recent commits comply with declared constraints? Drift detection is the difference between a living identity and a dead document.
Feed the identity into context. This is where context engineering and identity engineering compose. When an agent starts a session, the first thing in the context should be the service's declared identity. Not the whole codebase. Not a generated summary. The authoritative declaration of what this software is, what it does, and what it must honor. Context engineering gets dramatically more effective when it has an identity to draw from.
Halfway there
Context engineering earned its hype. It formalized something the industry was doing informally, gave it a name, and built tooling around it. That is genuine progress.
But the conversation stopped too early. We named the discipline of assembling information for a single inference call and treated it as the finish line. It is the starting point. The harder problem, the one that determines whether AI-assisted development actually works at organizational scale, is persistence. What does this software do? What constraints must it honor? What contracts does it guarantee? These questions have answers that should not change because someone started a new chat session or a different agent picked up the task.
Context is what changes. Identity is what persists. The industry got halfway there. Time to finish the job.
Context engineering needs something to draw from. We're building the persistent identity layer every context pipeline reads from.