
A mid-stage fintech company spends $80,000 and 300 engineering hours to get SOC 2 Type 2 certified. The auditor signs off. Champagne in Slack. Six weeks later, a product team ships a new microservice that stores PII in an unencrypted field, logs session tokens to a third-party observability platform, and violates two of the controls the company just paid to certify.
Nobody catches it for four months. The next audit cycle begins. The compliance team opens a spreadsheet. The whole thing starts over.
This is not a failure of tooling. It is a failure of architecture. The compliance industry has spent billions building systems that detect non-compliance and absolutely nothing that resolves it.
The $200K treadmill
SOC 2 compliance costs between $20,000 and $150,000 per certification cycle, depending on scope and organizational complexity. First-time certifications routinely exceed $200,000 when you include internal engineering time, readiness assessments, policy authoring, and the audit itself. Engineering teams report 200 to 600 hours of effort per cycle across engineering, legal, and management.
The bulk of that cost is not the audit. It is the scramble before the audit: collecting evidence, remediating findings, documenting controls that should have been documented when the code was written. It is the gap between "we know what we need to do" and "we have actually done it across every service, every deployment, every configuration."
And SOC 2 is the easy one. GDPR remediation for a mid-size company runs $50,000 to several hundred thousand. CMMC Level 2 compliance budgets range from $50,000 to $500,000+ depending on remediation scope. FedRAMP authorization can cost north of a million. The EU AI Act's high-risk provisions hit August 2, 2026. Colorado's AI Act enforcement begins June 30, 2026. Each new framework multiplies the manual burden.
The governance, risk, and compliance market is worth over $51 billion in 2025 and growing at 13%+ annually. A lot of money is moving. Very little of it is reducing the actual work.
A $6 billion monitoring industry
Vanta, valued at $4.15 billion after its $150 million Series D, has built an extraordinary business. Twelve thousand customers. $220 million in ARR. Vanta continuously monitors your infrastructure, maps evidence to controls, and tells you where you stand relative to SOC 2, ISO 27001, HIPAA, and a growing list of frameworks.
Drata, valued at $2 billion, does the same thing for over 7,000 customers across 20+ frameworks. Sprinto, Secureframe, Laika, Thoropass -- the space is crowded because the pain is real.
But here is what every one of these platforms does: it tells you that you are non-compliant. It shows you a dashboard. It generates a finding. It may even auto-generate a Jira ticket.
What it does not do is fix the code.
The finding lands in a ticketing system. A compliance lead triages it. An engineering manager assigns it. An engineer picks it up, context-switches into compliance mode, reads the control description, figures out what needs to change, makes the change, opens a PR, gets it reviewed, gets it merged, gets it deployed, and then manually marks the finding as resolved in the compliance platform.
That loop takes days. Sometimes weeks. In every organization we have talked to, the median time from compliance finding to deployed remediation is measured in business days, not minutes. Not hours. Days.
Vanta did not build a compliance enforcement tool. Vanta built a compliance awareness tool. That distinction is worth billions in unrealized value.
Policy-as-code: the other half that also stops short
On the other side of the stack, the infrastructure and security community built policy engines.
Open Policy Agent (OPA), a CNCF graduated project with broad adoption across the cloud-native ecosystem, lets you write policies in Rego and enforce them at admission time. Want to block Kubernetes deployments that don't have resource limits? OPA can do that. Want to prevent Terraform plans that open port 22 to the internet? OPA can do that.
HashiCorp's Sentinel does the same for the Terraform ecosystem. Checkov scans infrastructure-as-code for misconfigurations. Bridgecrew (acquired by Palo Alto Networks) extended this to CI/CD pipelines. AWS Config Rules, Azure Policy, GCP Organization Policy Constraints -- every major cloud provider has a native policy enforcement layer.
These tools are real and valuable. They prevent known-bad configurations from reaching production. That matters.
But they share Vanta's limitation from the opposite direction. Vanta detects non-compliance after the fact. OPA blocks non-compliance at deployment time. Neither one modifies the code.
When OPA rejects a deployment, what happens? A CI pipeline fails. An engineer reads an error message. The engineer figures out what policy was violated, figures out what needs to change, makes the change, pushes a new commit, and reruns the pipeline. If the engineer does not understand the policy -- and Rego is not a language most application developers read fluently -- the cycle takes longer. If the policy violation is in application code rather than infrastructure configuration, OPA never sees it at all.
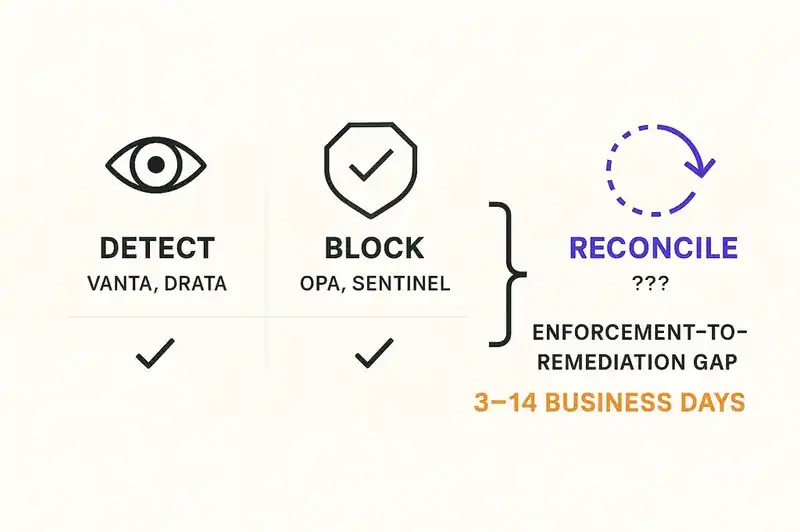
Detection. Blocking. Detection. Blocking. The entire compliance automation market has built variations on two verbs, and neither of them is "fix."
The enforcement-to-remediation gap
Name the gap: the enforcement-to-remediation gap. The distance between a system detecting a compliance violation and the violation actually being resolved in code, in configuration, in production.
For monitoring tools like Vanta, the gap is: finding generated, ticket filed, engineer assigned, context loaded, change made, PR reviewed, deployed, finding closed. Median: 3-14 business days, depending on severity and team capacity.
For policy-as-code tools like OPA, the gap is smaller but still manual: pipeline blocked, error read, code changed, pipeline rerun. Median: hours to days, depending on the engineer's familiarity with the policy.
For neither category does the gap approach zero. For neither category is the gap automated. For neither category does a new compliance requirement propagate across an entire codebase without human intervention.
Gartner predicted that 70% of enterprises would integrate compliance-as-code into their DevOps toolchains by 2026. We are in 2026. The integration is happening. But "compliance-as-code" as currently practiced means writing policies that block or alert. It does not mean writing policies that reconcile. The verb matters.
What cascading compliance actually looks like
Consider what Kubernetes does with a Deployment manifest.
You declare: I want three replicas of this container, running this image, with these resource limits, behind this service. You apply the manifest. The Kubernetes control plane reads the declaration and begins reconciling reality against it. If a pod dies, the controller brings up a new one. If you change the replica count, the controller scales. You never SSH into a node and start a container manually. You declare desired state. The system reconciles continuously.
Now apply that pattern to compliance.
You declare, in a machine-readable identity layer: this service handles PII. All PII fields must be encrypted at rest. Logs must not contain session tokens. All API endpoints must enforce authentication. Data must not leave the EU region. The service must comply with SOC 2 CC6.1 (logical and physical access controls) and CC6.7 (data transmission protection).
That declaration lives in the service's Software DNA -- its persistent, version-controlled identity. It is not a wiki page. It is not a spreadsheet. It is a structured artifact that tooling can parse and agents can act on.
When an AI coding agent generates a new feature for this service, it reads the DNA first. The DNA says PII must be encrypted. The agent generates code that encrypts PII. Not because the prompt said "encrypt PII" -- the developer may not have thought to mention it -- but because the constraint is declared in the identity layer and the agent is bound to honor it.
When a CI/CD pipeline validates a PR against this service, it checks the DNA. Does the diff introduce an unencrypted PII field? Does it log anything that matches a session token pattern? Does it add an unauthenticated endpoint? The validation is not a generic linter. It is a DNA-aware check that understands this service's specific constraints.
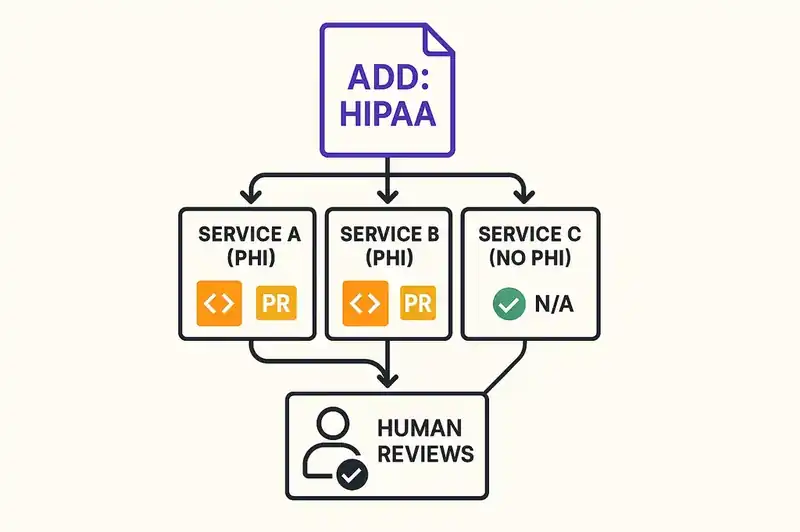
When a new compliance requirement is added -- say, the organization adopts HIPAA because it is entering healthcare -- the relevant constraints cascade. Every service whose DNA declares that it handles PHI gets a new set of requirements. Agents can scan every service, diff the current implementation against the new constraints, and generate remediation PRs. Not tickets. PRs. Code changes, ready for human review.
That is the difference. Vanta tells you that Service A is non-compliant with HIPAA's encryption requirements. OPA blocks Service A's next deployment if it lacks encryption. Cascading compliance generates the encryption implementation, opens a PR, and waits for a human to approve it.
Detection. Blocking. Reconciliation. Three verbs. The industry has built the first two. The third is what changes the economics.
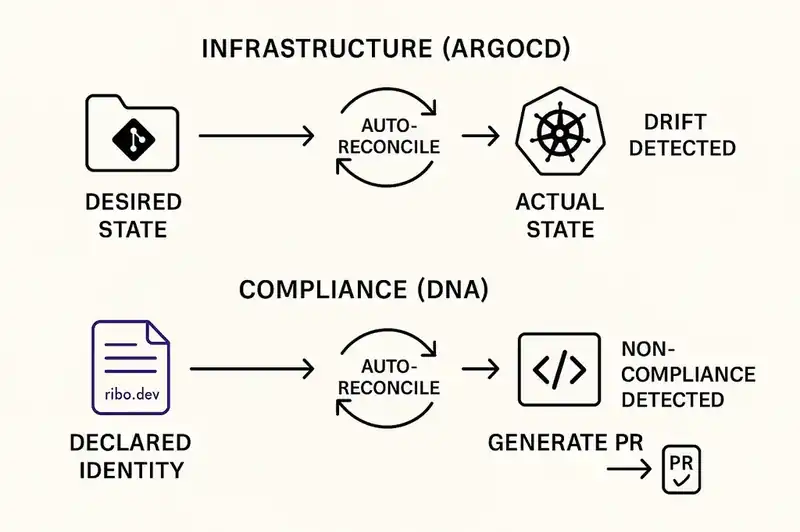
The ArgoCD analogy
ArgoCD popularized a specific pattern: GitOps. You define your desired Kubernetes state in a Git repository. ArgoCD watches the repository. When the repo changes, ArgoCD reconciles the cluster. When the cluster drifts, ArgoCD detects it and can auto-reconcile back to the declared state.
The critical insight of GitOps is that the Git repository is the source of truth, not the running cluster. The running cluster is a projection of the declared state. Drift is not a problem to investigate -- it is a condition to automatically correct.
Software DNA applies the same insight to compliance. The identity layer is the source of truth, not the running code. The running code is a projection of the declared identity. Non-compliance is not a finding to triage -- it is a condition to automatically reconcile.
ArgoCD does not file a Jira ticket when the cluster drifts. It fixes the drift. That is the design pattern compliance needs.
The difference is that compliance reconciliation involves code changes, not just infrastructure state. The reconciliation agent needs to understand application logic, not just Kubernetes manifests. This is harder. But with AI agents that can read, understand, and modify codebases, it is no longer theoretical. The capability exists. What is missing is the declarative layer that tells the agent what "compliant" means for this specific service.
The enterprise angle
Enterprise compliance officers manage dozens of frameworks simultaneously. SOC 2. ISO 27001. HIPAA. PCI DSS. GDPR. CCPA. FedRAMP. CMMC. And now the EU AI Act and Colorado's AI Act, with more state-level AI legislation in draft.
Each framework maps to hundreds of controls. Each control maps to technical requirements. Each technical requirement must be implemented across every relevant service. When a new framework is adopted or an existing framework is updated, the compliance team must assess the gap, create a remediation plan, file tickets, and track implementation across engineering teams that have their own roadmaps and their own priorities.
Cascading compliance changes this math entirely.
A single change to the identity layer -- adding "HIPAA" to a service's compliance requirements -- triggers an automatic assessment: which controls are already satisfied by existing constraints, which controls require new constraints, and which constraints require code changes. The assessment is not a report for a human to interpret. It is a machine-readable diff between current state and required state.
Agents generate remediation PRs for every gap. Engineers review code, not compliance matrices. The compliance officer tracks PR merge status, not ticket status. The audit trail is the Git history. The evidence is the DNA declaration, the generated code, the PR review, and the deployment record.
One declaration. Codebase-wide reconciliation. Continuous, not periodic. That is the structural shift.
For organizations managing multiple frameworks, the leverage compounds. Many frameworks share underlying controls -- SOC 2's CC6.1 and ISO 27001's A.9.1.1 both address access control. A constraint declared once in the identity layer satisfies both. When the next framework arrives, the system already knows which controls are covered and which are new. The marginal cost of adopting a new framework drops from months of engineering effort to a set of incremental constraint declarations and their automatically generated remediations.
The practical path
This is not a future that requires rebuilding your stack. It requires three things.
First, a declarative identity layer per service. A structured file -- call it a DNA manifest, a service identity, whatever fits your naming convention -- that declares what the service is, what constraints it must honor, and what compliance frameworks apply. This file is version-controlled alongside the code. It is the contract that agents and tooling read.
Start with one service. Pick the one that just failed a compliance check. Define its identity. Declare its constraints. Make the implicit explicit.
Second, agent-aware constraint enforcement. Your AI coding agents need to read the identity layer before generating code. Your CI/CD pipeline needs to validate against it. This is integration work, not invention. The primitives exist: structured configuration files, pre-generation prompts, pipeline checks. The gap is connecting them to a persistent identity rather than ad-hoc rules.
Third, reconciliation loops. When a constraint changes or a new framework is added, something needs to diff current state against required state and generate the changes. Today, that something is an engineer reading a compliance report. Tomorrow, it is an agent that reads the identity layer, scans the codebase, and opens PRs. The human stays in the loop -- reviewing and approving, not researching and implementing.
The organizations that will navigate the coming regulatory landscape -- EU AI Act, Colorado AI Act, whatever comes next -- without drowning in manual remediation are the ones that build the identity layer now. The tooling is not perfect today. But the pattern is correct, and incremental adoption is possible.
The honest version
We are not claiming this is solved. Cascading compliance as described here requires AI agents that can reliably generate correct, context-aware code changes. That capability is improving fast but is not flawless. It requires identity declarations that are comprehensive enough to be useful and maintainable enough not to become another abandoned artifact. It requires organizational discipline to keep the identity layer current -- which is the same discipline that compliance already demands, just directed at a different artifact.
The monitoring tools are real and valuable. If you are not using Vanta or Drata or something equivalent, start there. Knowing where you stand is a prerequisite to reconciling where you stand.
The policy engines are real and valuable. If you are not using OPA or Sentinel or cloud-native policy constraints, start there. Blocking known-bad configurations at deployment time prevents a category of compliance failures.
But if you stop at detection and blocking, you are paying for the ability to know you are broken without the ability to fix yourself. You are paying for a dashboard that shows drift without a system that corrects it. You are paying $80,000 per audit cycle and 300 engineering hours because the architecture of compliance has not caught up to the architecture of the systems it governs.
The declarative reconciliation pattern is not new. Kubernetes proved it for infrastructure. Terraform proved it for cloud resources. ArgoCD proved it for deployment state. The question is not whether the pattern works. The question is when the compliance industry applies it to the thing that actually matters: the code.
A single declaration, in a persistent identity layer, continuously reconciled across every service and every deployment. Compliance as a property of the system itself, not a dashboard you check quarterly.
Declare it once. Reconcile it forever.