
Only one in four developers have access to quality internal documentation. Not one in four at struggling startups. One in four across the entire industry -- more than 32,000 respondents surveyed by Google's DORA research program in 2021.
Three out of four developers are operating without reliable written knowledge about the systems they build, maintain, and depend on. They're navigating by tribal memory, stale wiki pages, and Slack threads that scroll past before anyone bookmarks them.
Meanwhile, the software documentation tools market hit $6.32 billion in 2024 and is projected to reach $12.45 billion by 2033 (Verified Market Reports). Billions of dollars flowing into a category where the primary output -- the document -- begins decaying the moment it's published.
Something is structurally wrong here.
The $6.3 billion bandage
The documentation tools market is enormous because the pain is real. Poor documentation costs a mid-sized engineering team between $500K and $2M annually in lost productivity, context-switching overhead, and repeated interruptions (GetDX). Developers spend 3-10 hours per week searching for information that should already be written down (GetDX). The gap between dependency and delivery is where money burns.
So the market responds. Confluence. Notion. GitBook. ReadMe. Document360. Archbee. Hundreds of tools built to make writing, organizing, and publishing documentation easier. Better editors. Better search. Better collaboration. Better templates.
None of them address the reason documentation fails.
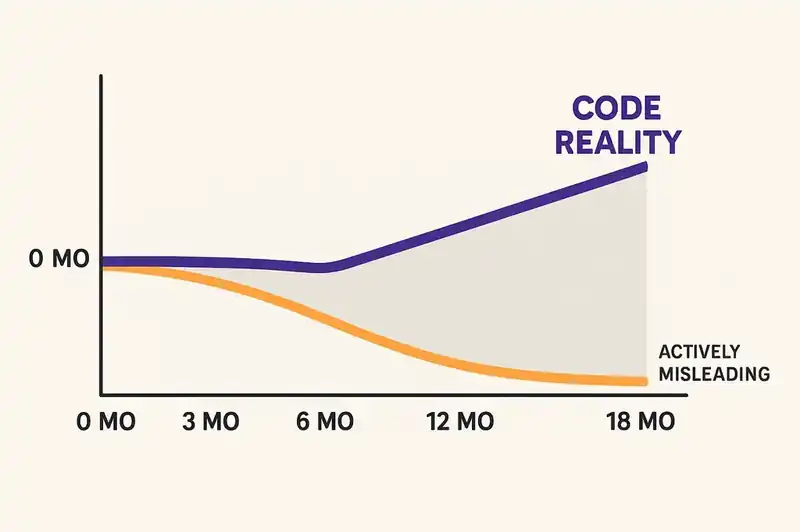
Documentation fails because it's a separate artifact. It exists outside the system it describes. It must be updated manually, by humans who have other priorities, on a timeline that is always slower than the code it's supposed to reflect. The document and the implementation begin diverging the moment the pull request merges. Within 3-12 months without active maintenance, the content is unreliable. Within 18 months, it's actively misleading.
The $6.3 billion market isn't solving the documentation problem. It's making it more comfortable to live with.
What docs-as-code got right
The docs-as-code movement deserves credit. Starting roughly a decade ago and codified by Anne Gentle's "Docs Like Code" in 2017, the core insight was sound: treat documentation like source code. Store it in Git. Review it in pull requests. Build it with CI/CD. Deploy it alongside the application.
This was a meaningful improvement over the prior world of isolated wikis and Word documents emailed between teams. Docs-as-code brought version control, review workflows, and proximity to the codebase. It made documentation a first-class development artifact rather than an afterthought managed by a separate team with separate tools.
It also introduced new problems. Git is complex for writers who aren't developers. Tooling requires custom infrastructure. The review process adds friction that discourages contributions. Tom Johnson, one of the most widely-read voices in technical writing, has catalogued these failures in detail. The writing community has spent years debating whether the promise was ever fully delivered.
But the fundamental limitation of docs-as-code isn't tooling friction. It's that proximity to code is not the same thing as derivation from code. A Markdown file sitting in the same repository as the source code is still a manually maintained artifact. It still requires a human to notice when the implementation changes and update the corresponding documentation. It still decays. It decays slightly slower because the pull request workflow creates a natural reminder, but the reminder is easily ignored under deadline pressure, and it usually is.
Most developers don't document code daily. Not because they don't value documentation. Because they have twenty other things to do, and the documentation is the one that doesn't break the build when you skip it.
Docs-as-code got the location right. It got the mechanism wrong. Storing documentation near code doesn't make it self-maintaining. It makes it slightly harder to forget about.
Why AI documentation tools are patching a broken model
The current wave of AI-powered documentation tools represents the most sophisticated attempt yet to solve the staleness problem. Mintlify hit $10M ARR at the end of 2025, up 10x from $1M the prior year, handling over a million queries monthly. Swimm couples documentation directly to code snippets and uses AI to update content as the codebase changes. GitHub Copilot's /doc command generates inline documentation from function signatures. Eighty-one percent of developers expect AI tools to become more integrated in how they document code over the next year (Stack Overflow, 2024).
These tools are genuinely useful. Mintlify makes beautiful developer-facing documentation sites and has clearly found product-market fit. Swimm's approach of anchoring docs to specific code ranges is clever -- when the anchored code changes, the documentation is flagged for review. Copilot's inline generation reduces the activation energy for writing docstrings.
But watch what each of these tools is actually doing. They're generating or maintaining documents. Better documents. Faster documents. Documents that stay current longer. The unit of output is still a static artifact -- a page, a docstring, a tutorial -- that represents a snapshot of understanding at a point in time.
Mintlify generates documentation sites from your codebase. The site is still a derivative artifact that needs rebuilding when the code changes. Swimm detects drift between documentation and code. The documentation is still a separate thing that drifts. Copilot writes docstrings above functions. The docstring is still a comment that can fall out of sync with the function it describes.
AI makes the maintenance loop faster. It doesn't eliminate the maintenance loop. The document is still there. The divergence is still there. The decay is slower, but it's still decay.
This is an important distinction because it determines where the industry is headed. If you believe the problem is "documentation is too hard to maintain," then AI writing assistants are the answer. If you believe the problem is "documentation is a fundamentally flawed abstraction," then making it easier to produce is treating the symptom.
We believe it's the latter.
The fundamental failure
The structural problem is simple to state: documentation is a lossy, manually-maintained projection of a system's identity.
A payment service has a purpose (process transactions), behavioral contracts (this API guarantees idempotency with P99 latency under 200ms), constraints (PCI-DSS compliance, data residency in the originating region), and relationships (depends on processor-gateway, consumed by checkout-frontend). These facts constitute what the service is.
Documentation is someone's attempt to write those facts down in prose, organize them into pages, and keep them updated as the service evolves. The documentation is a map. The system is the territory. The map is always wrong. The question is how wrong, and how recently someone noticed.
This was tolerable when humans wrote all the code and had the context in their heads. The senior engineer who built the billing module could answer questions about it even when the wiki was six months stale. Tribal knowledge was a fragile backup system, but it was a backup system.
Two shifts have made this model untenable.
First, AI-generated code is now a substantial fraction of what gets committed. GitClear's 2025 analysis of 211 million changed lines found that 41% of committed code is AI-generated. An AI agent writing code for your payment service doesn't have tribal knowledge. It doesn't remember the conversation in Slack where someone decided not to support multi-currency. It doesn't know that the previous team lead intentionally excluded refund processing from this service's scope. If the documentation is stale -- and it is -- the agent has no reliable source of truth about what this service is supposed to be.
Second, team turnover means the human backup system is failing. The engineer who "just knows" the billing module is interviewing somewhere else. When they leave, the stale documentation isn't a suboptimal resource. It's the only resource. And it's wrong.
The documentation-as-artifact model requires continuous human effort to maintain alignment between what the software is and what the documentation says it is. That effort has always been insufficient. It's now catastrophically insufficient, because agents operate at a speed and scale that makes human-maintained documentation a rounding error.
Identity as the source of truth
The alternative is not better documentation. It is eliminating static documentation as the authoritative representation of a system's identity.
Instead: declare the identity itself. Machine-readable, version-controlled, continuously reconciled against implementation. A structured declaration of purpose, contracts, constraints, and relationships that tooling can read, enforce, and generate from.
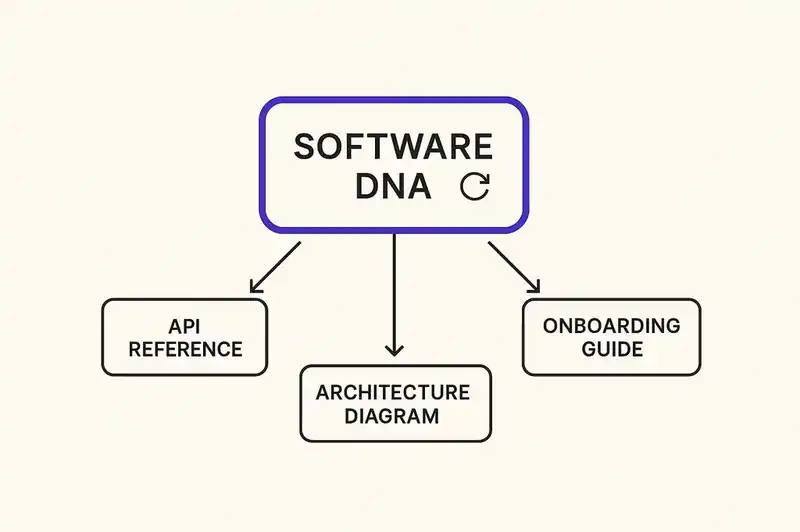
We call this Software DNA. The concept isn't complicated. Your service's identity -- what it does, what it guarantees, what rules it follows, what it connects to -- is declared in a structured format that lives alongside the code. Not as documentation about the code, but as the authoritative specification that the code implements.
From this identity layer, everything that traditional documentation provides can be generated on demand:
API references. The behavioral contracts in the identity declaration specify every endpoint's guarantees, error semantics, and versioning policy. An AI agent generates the API reference page from the contracts. Not from code comments. Not from a hand-maintained OpenAPI spec that someone forgot to update. From the declared contracts that CI validates on every commit.
Architecture diagrams. The relationships section of the identity declaration specifies dependencies, consumers, ownership, and data flows. Diagrams are rendered from these declared relationships. They're accurate by definition because they're drawn from the same source that the reconciliation loop validates.
Onboarding guides. A new developer joins the team and asks: "What does this service do?" An AI agent reads the identity declaration -- purpose, boundaries, contracts, constraints -- and generates a contextual onboarding narrative. Not a guide that was written eighteen months ago for a version of the service that no longer exists. A guide generated from the current declared identity, right now.
Compliance documentation. The constraints section declares regulatory requirements. SOC 2, PCI-DSS, HIPAA, the EU AI Act. Compliance documentation is generated from the declared constraints cross-referenced against the implementation. Auditors get documentation that is provably derived from the enforced specification, not a retrospective summary that may or may not reflect reality.
The documentation isn't gone. It's generated. It's derived from something that has structural integrity rather than something that depends on human diligence. The output looks the same -- pages, diagrams, references -- but the source is different. And the source is what determines whether the output can be trusted.
The map versus the GPS
An analogy might help here.
Traditional documentation is a paper map. Someone surveyed the territory, drew the map, and printed it. The map was accurate on the day it was drawn. Roads get built. Bridges close. New subdivisions appear. The map doesn't update. If you're lucky, someone publishes a new edition annually. If you're unlucky, you're navigating with a map from three years ago and the highway exit you need was renumbered last spring.
AI-assisted documentation tools are a map with a subscription service that sends you update stickers to paste over the parts that changed. Better than the static map. Still a map. You're still depending on someone to identify what changed, draw the sticker, and mail it to you. Sometimes the sticker is late. Sometimes it covers the wrong section. Sometimes you don't apply it because you're busy driving.
Software DNA is GPS coordinates. The territory is the territory. Your position is computed from the territory itself, not from a representation of the territory that someone made last year. When the road changes, your route updates. Not because someone maintained the map, but because the system of record is the territory, and the route is derived from it in real time.
The documentation industry is in the business of making better maps. The question is whether you need a map at all when you can derive directions from the coordinates.
The practical path
We're not naive about what this requires. You don't replace a $6 billion ecosystem overnight, and we're not suggesting anyone burn their existing documentation tomorrow.
The practical path has stages.
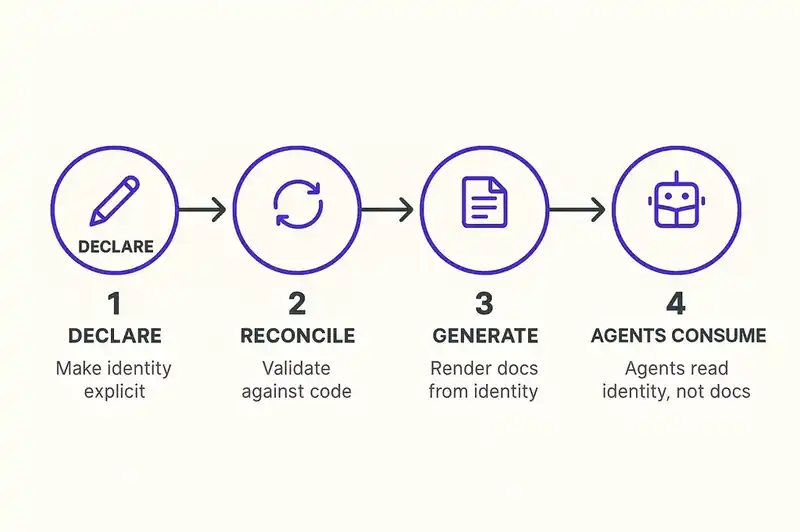
First: declare what you already know. Every team has implicit identity knowledge -- the purpose of each service, the contracts it honors, the constraints it operates under. Most of this lives in the heads of senior engineers and scattered across README files, architectural decision records, and Slack threads. The first step is making it explicit and structured. Not writing more documentation. Writing a declaration that captures identity in a machine-readable format.
Second: reconcile continuously. A declaration that isn't validated against implementation is just another document. The identity layer only works if there's a reconciliation loop -- CI checks, agent-driven audits, drift detection -- that continuously compares what the software declares itself to be against what the software actually does. When the implementation diverges from the declared identity, you get a signal. Not six months later when someone reads the stale wiki and notices a discrepancy. Immediately, on the commit that introduced the drift.
Third: generate instead of maintain. Once the identity layer is the authoritative source, documentation becomes a rendering concern. You don't maintain an API reference page. You render it from the contracts. You don't maintain an architecture diagram. You render it from the relationships. You don't maintain an onboarding guide. You prompt an AI agent with the identity declaration and let it generate a narrative appropriate for the audience. The documentation is a view. The identity is the model. You maintain the model. The views take care of themselves.
Fourth: let agents consume identity, not docs. The biggest practical payoff is for AI coding agents. An agent that reads a structured identity declaration before generating code has context that no amount of RAG over stale documentation can provide. It knows the boundaries, the contracts, the constraints. It doesn't generate code that violates the architecture because the architecture is declared in a format it can parse and respect. DORA's own research supports the downstream impact: teams with high-quality documentation are 2.4x more likely to see better software delivery performance. Now imagine the quality guarantee is structural rather than aspirational.
This is a migration, not a rip-and-replace. You start by declaring identity for your most critical services. You add reconciliation to your CI pipeline. You begin generating documentation from identity instead of maintaining it by hand. Over time, the identity layer becomes the source of truth, and the documentation becomes what it always should have been: a derived output, not a primary artifact.
What documentation cannot solve
The documentation industry has spent decades trying to solve a problem that cannot be solved at the documentation layer. The problem is not that documentation is hard to write, hard to maintain, or hard to find. The problem is that documentation is a separate artifact that must be kept in sync with the system it describes, and that synchronization requires continuous human effort that consistently does not happen. AI makes the effort cheaper. It does not make the architecture sound.
The alternative is an architecture where the system's identity is declared, not described. Where documentation is generated, not maintained. Where the source of truth is a machine-readable specification, not a prose artifact.
This is not a prediction about some distant future. Kent Beck is already governing agents with plan files. GitHub is shipping specification toolkits. ThoughtWorks put spec-driven development on the Technology Radar. The building blocks exist. The pattern is proven — Terraform proved it for infrastructure, Kubernetes proved it for orchestration.
The documentation tools market will keep growing. Documentation will keep decaying. Somewhere between those two facts is an opening for something structurally different.
Better maps will not fix a stale territory. We're building the identity layer that makes the territory declare itself.