
In 1968, a researcher at IBM's Yorktown Heights facility named Meir Lehman received an assignment that would define his career: investigate IBM's internal software development process for OS/360. What he found was strange. Developers were producing code at a steady rate, but debugging activity per module was declining at the same rate. The system was growing, but it wasn't getting better. It was getting harder to understand and harder to change, drifting further from what users actually needed.
Over the next twenty-eight years, Lehman formalized eight laws describing what happens to software that operates in the real world. He called these "E-type" systems -- software embedded in reality, where the requirements shift because the world shifts. Not academic exercises. Not compilers with fixed specifications. The messy, evolving, business-critical systems that every engineering organization actually builds.
Those eight laws read like a diagnosis of every codebase you've ever inherited. They also read like a specification for something that didn't exist when Lehman wrote them.
Why these laws matter now
Lehman published his laws between 1974 and 1996. For most of that period, and for the two decades that followed, the only mechanism for honoring them was human attention. Engineers read the code. Engineers noticed the drift. Engineers held the mental model of what the system was supposed to be. When that attention lapsed -- because people left, or the team grew faster than knowledge could transfer, or the backlog got too deep -- the laws won. Complexity increased. Quality declined. The system drifted from its purpose.
That was expensive but survivable when humans wrote all the code. GitClear's 2025 analysis of 211 million changed lines found that 41% of committed code is now AI-generated. Agents produce code at a volume and velocity that outpaces any human's ability to maintain the mental model. The laws haven't changed. The speed at which they punish you has.
Identity engineering -- a persistent, machine-readable declaration of what software is, what it should do, and what constraints it must honor, continuously reconciled against the actual codebase -- is the first architecture that can honor Lehman's laws at the speed they now demand. Not because it's clever. Because Lehman described exactly what's needed, and the technology to build it didn't exist until now.
Here are all eight laws, and what each one requires.
Law I: Continuing Change (1974)
"An E-type system must be continually adapted or it becomes progressively less satisfactory."
Every team has shipped a v1 and thought "we're done." Lehman's first law says you're never done. Software operating in the real world can't be finished because the world it operates in keeps changing. Regulations update. User expectations shift. Competitors move. A system that stops adapting doesn't hold steady. It rots.
The 2024 DORA report found that organizations with strong platform foundations see improvements compound -- each investment makes the next change cheaper. The inverse is also true. Each deferred adaptation makes the next one more expensive. The system accumulates fitness debt, and the interest rate is nonlinear.
Identity engineering makes continuing change directed rather than chaotic. The identity layer itself evolves: new constraints get added, outdated contracts get removed, boundaries get redrawn. Each change is an identity mutation -- a versioned, reviewable decision about what the software should be right now. Without a declared identity, "change" is drift with good intentions. With one, it's evolution with a direction.
Law II: Increasing Complexity (1974)
"As an E-type system evolves, its complexity increases unless explicit work is done to maintain or reduce it."
The weight in that sentence falls on "explicit work." Complexity doesn't accumulate because anyone wants it to. It accumulates because reducing it requires effort that produces no visible output. Nobody gets promoted for removing dead code paths. Nobody's sprint velocity improves because they simplified a module boundary. The work is invisible, so it doesn't get prioritized, so the complexity compounds.
This is what background reconciliation agents are built for. The "explicit work" Lehman demanded -- identifying dead paths, flagging architectural drift, cleaning up constraint violations -- is exactly the kind of continuous, unglamorous maintenance that agents handle well and humans consistently defer. A reconciliation loop that compares code against declared identity surfaces complexity that humans can't see because they've stopped looking. The agent doesn't get bored. It doesn't get pulled into a production incident and forget to come back. It runs the diff, reports the delta, and keeps running.
The alternative is what most organizations have today: complexity that accumulates silently until someone tries to change something and discovers the system has become incomprehensible. By then, the cost of simplification exceeds the cost of rewriting. Lehman observed this pattern in 1974. Fifty-two years later, it is still the default.
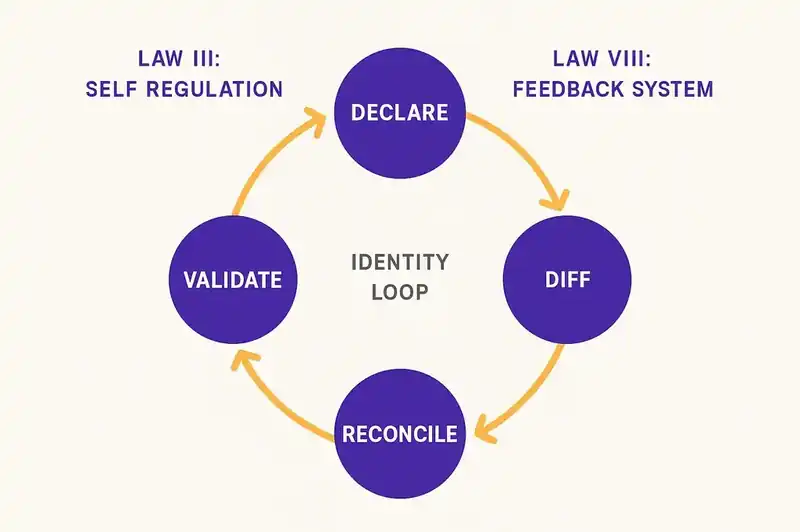
Law III: Self Regulation (1974)
"E-type system evolution processes are self-regulating with the distribution of product and process measures close to normal."
This one surprises people. Lehman found that large software systems develop their own statistical regularity -- release sizes, defect rates, and change volumes tend toward a normal distribution over time, regardless of management interventions. You can't force a system to evolve faster than its natural rate by adding headcount or declaring a "big bang" release. The system pushes back.
The reconciliation loop in identity engineering is a self-regulating system by design. Declare identity. Diff against code. Agents reconcile. Validate the reconciliation. Repeat. The feedback loop creates natural bounds on how fast the system changes and how far it drifts before correction kicks in. When the delta is large, reconciliation activity increases. When the system is converged, activity decreases. The regulation is structural, not dependent on someone remembering to check.
Without this loop, self-regulation happens through human attention -- which is scarce, unevenly distributed, and interrupted by every Slack message and production alert. The system still self-regulates (Lehman observed that it always does), but it regulates around whatever humans happen to notice, not around what the software is supposed to be.
Law IV: Conservation of Organisational Stability (1978)
"The average effective global activity rate in an evolving E-type system is invariant over the product's lifetime."
If you've lived through a hiring spree, you already know this one in your bones: adding people doesn't proportionally increase the rate of effective change. Organizations have a roughly constant throughput of meaningful change they can absorb, regardless of team size. Onboarding costs, coordination overhead, and communication complexity eat the gains from additional headcount. Brooks described the mechanism in 1975. Lehman measured the outcome.
Identity engineering doesn't try to increase that rate. It redirects it. Right now, a significant portion of your engineering capacity goes to comprehension -- reading code to understand what it does, reviewing pull requests to determine if a change is safe, rediscovering tribal knowledge that exists only in someone's head. With a declared identity layer, agents handle the reconciliation and drift detection. Humans spend their finite change budget on identity decisions: what should this software be? What constraints should apply? What contracts need to change?
The total throughput stays roughly constant. That's Lehman's point. But the allocation shifts from maintenance comprehension to architectural judgment. The budget is the same. The value per unit of effort goes up.
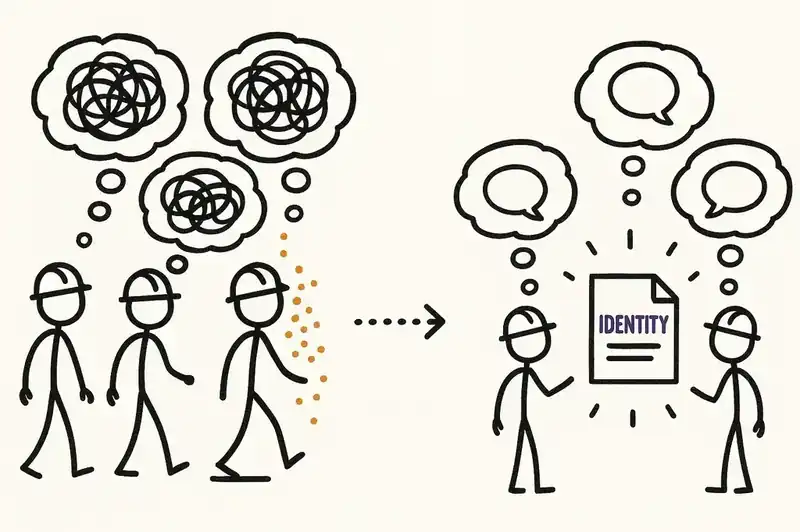
Law V: Conservation of Familiarity (1978)
"As an E-type system evolves, all associated with it must maintain mastery of its content and behaviour to achieve satisfactory evolution."
This is the tribal knowledge problem stated as physics. When a system grows faster than the people around it can understand it, evolution quality degrades. The system needs to be familiar to the people changing it. Unfamiliar changes produce unfamiliar bugs.
AI-generated code breaks this law by default. When 41% of your codebase was written by agents, and that percentage is climbing, the humans on the team have not read most of the code they're responsible for. They didn't write it. They didn't review all of it. They can't hold it in their heads. Familiarity, in Lehman's sense, is already collapsing in most organizations that have adopted agentic coding tools aggressively.
The identity layer externalizes familiarity. Instead of mastery living in individuals' heads -- where it leaves when they leave -- it lives in a declared, versioned, machine-readable artifact. A new engineer reads the identity declaration and knows what the payment service is, what it guarantees, what constraints it honors, and what it explicitly does not do. A new agent reads the same declaration and operates within the same boundaries. Familiarity becomes a property of the system, not a property of the people who happened to be in the room when the decisions were made.
This doesn't eliminate the need for human understanding. It changes what humans need to understand. You need mastery of the identity -- the what and why. You don't need mastery of every implementation detail -- the how. The identity layer is the compression layer. It encodes the decisions that matter at a level humans can maintain mastery of, even as the implementation grows beyond any individual's comprehension.
Law VI: Continuing Growth (1991)
"The functional content of an E-type system must be continually increased to maintain user satisfaction over its lifetime."
Features must grow. Users demand more from software over time, and a system that stops adding functionality loses users to systems that don't stop. Lehman formalized what every product manager already knows: you ship or you die.
The problem is that feature growth without governance is how you get the "everything service." A payment service that also handles user profiles because someone needed it once. A notification system that grew a reporting engine because it was convenient. Scope creep isn't a planning failure. It's what happens when there's no declared boundary for what the software is.
The DNA layer declares those boundaries -- what the software is and what it is not. Growth happens within declared purpose. When someone proposes a feature that falls outside the boundary, the identity layer surfaces the conflict before code gets written, not after. The decision to expand the boundary is a decision -- reviewable, versioned, deliberate. The decision to add a feature within the boundary is execution.
Without declared purpose, every feature request is equally valid because there's no definition of scope to evaluate against. With declared purpose, growth is directed. Lehman's law still holds -- the system must grow -- but the growth follows a path instead of spreading in every direction.
Law VII: Declining Quality (1996)
"The quality of an E-type system will appear to be declining unless it is rigorously maintained and adapted to operational environment changes."
"Rigorously maintained" is doing a lot of work in that sentence. Not maintained when someone has a free afternoon. Not maintained during a quarterly tech debt sprint that gets cancelled halfway through. Rigorously. Lehman observed that quality decline is the default state. Holding quality steady requires continuous, active effort. Improving quality requires even more.
Background agents running continuous reconciliation against declared constraints is rigorous maintenance, automated. The agents don't check quality once per sprint. They check it continuously. When a new commit introduces a constraint violation, the reconciliation loop flags it before the next deploy. When the operational environment changes (a new compliance requirement, a dependency upgrade, an infrastructure migration), the identity layer records the change and agents begin reconciling the codebase against the new reality.
The convergence chart -- showing the gap between declared identity and actual implementation over time -- is quality trajectory made visible. Without an identity layer, you can't even measure quality decline in a meaningful way because you have no baseline. "Quality" becomes whatever the team feels like it is, which is usually "fine" right until something breaks in production. With a declared identity, quality is the distance between what the software should be and what it is. That distance is something you can actually track, week over week, and act on before it compounds.
Law VIII: Feedback System (1996)
"E-type evolution processes constitute multi-level, multi-loop, multi-agent feedback systems and must be treated as such."
Read that formulation again. Multi-level. Multi-loop. Multi-agent. Lehman wrote this in 1996, thirty years before agentic development existed as a category. He was describing what software evolution processes inherently are, whether anyone designs them that way or not. The question is whether you build the system intentionally or let it emerge accidentally.
Identity engineering is this law made concrete. Multiple levels: the identity layer sits above the code layer, declaring what should be true while implementation handles how. Multiple loops: reconciliation cycles that run continuously, each pass comparing declared state to actual state and computing the delta. Multiple agents: background reconciliation agents, CI validation agents, infrastructure agents, each operating at a different level of the stack with a shared reference point.
Lehman observed that treating software evolution as a simple, single-loop process produces bad outcomes. He was right. Most organizations still run a single loop: developer writes code, reviewer checks code, CI runs tests, code ships. The identity engineering architecture adds the loops Lehman said were necessary: identity declaration, continuous reconciliation, drift detection, convergence tracking. The architecture he described. Built with technology he couldn't have anticipated.
Lehman described the system. We're building it.
Lehman's laws are empirical observations. He watched real systems evolve over decades and described what happened. He didn't prescribe solutions because the technology to implement them didn't exist. The solution his laws imply requires three things:
A persistent declaration of what the software should be. A living, versioned, machine-readable identity that agents and humans both reference -- the anchor that makes every other mechanism possible.
Agents that continuously reconcile code against that declaration. The kind of automated, tireless reconciliation that catches drift when it's small, before it compounds into the architectural problems that make VPs of Engineering lose sleep. The "explicit work" of Law II. The "rigorous maintenance" of Law VII.
Feedback loops that let the system self-regulate. Multiple loops operating at different levels and speeds, because Lehman was right that a single pass from commit to deploy isn't enough. The multi-level, multi-loop, multi-agent system of Law VIII.
Lehman published his first three laws the same year that Vint Cerf published the TCP specification. He published his last two the same year that Java 1.0 shipped. Across that entire span, and for the thirty years that followed, the only way to honor his laws was to hire enough good engineers and hope they stayed long enough to maintain familiarity with the system. That approach was always fragile. With AI-generated code now comprising nearly half of what gets committed, it's breaking.
The eight laws haven't changed. The speed at which software evolves has. Identity engineering is the architecture that can match that speed -- not by replacing human judgment, but by giving human judgment a persistent foundation to build on and agents a declared truth to reconcile against.
Lehman told us what software needs. Fifty-two years is long enough to wait.
If you're working through the same problems Lehman described -- drift, complexity, declining quality in an agentic world -- we'd like to compare notes.