
Last month, a platform lead at a Series B fintech told us she ran an experiment. She gave the same ticket to four engineers on her team: "Add rate limiting to the payments API." Same acceptance criteria. Same deadline. Same codebase.
She got back four implementations that looked like they came from four different companies.
One used a token bucket algorithm with Redis. One used a sliding window with an in-memory store. One bolted on a third-party rate limiting library with 14 transitive dependencies. One implemented rate limiting as Express middleware but forgot the service had a 99.9% SLO and didn't account for the latency the middleware added.
Every implementation worked. None of them were consistent with each other. And the differences had nothing to do with the engineers' skill levels. The differences traced directly to which AI tool each engineer was using, what context that tool had, and what prompting patterns the engineer had developed over months of individual use.
Four engineers. Four AI setups. Four architectures for the same requirement.
The consistency you think you have
Most engineering leaders believe their team writes reasonably consistent code. They have a style guide. They have linting. They have PR review. They have maybe a few senior engineers who serve as the architectural immune system, catching deviations during review.
Here's what that picture misses: the AI each developer uses has never read your style guide. Not unless someone manually pasted it into context, and even then, only for that session. SmartBear's analysis of code reviews across multiple organizations found that reviews catch 60-90% of defects before they leave development. That range is wide because effectiveness collapses when PRs exceed 400 lines of code. And AI-assisted PRs are getting bigger, fast. The 2025 DORA report data, analyzed by Faros AI across 10,000+ developers, showed a 154% increase in pull request size correlated with high AI adoption.
So the filter that's supposed to catch inconsistency -- code review -- is seeing bigger PRs with more AI-generated code, reviewed by humans who have less context about why the code looks the way it does. The 10-40% of issues that slip through review have always shipped. Now they ship carrying patterns that no human on the team chose.
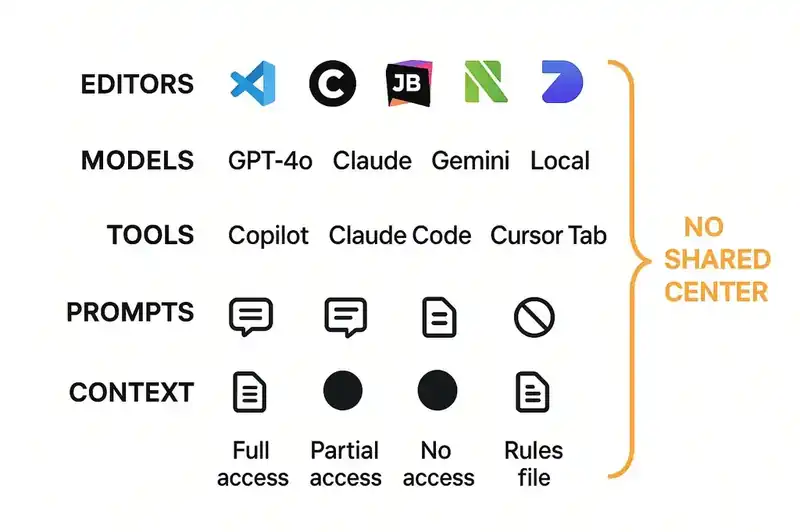
The fragmentation nobody inventoried
If you manage an engineering team of any size, try this exercise. Ask every developer to write down:
Which editor they use. VS Code, Cursor, JetBrains, Neovim, Zed, Windsurf, Xcode, vim with a custom LLM plugin someone built over a weekend. The Stack Overflow 2025 Developer Survey showed VS Code still dominant, but 18% of developers now use Cursor and 10% use Claude Code. On a team of twenty, you could easily have five different editors.
Which AI tools they run. GitHub Copilot, Cursor Tab, Claude Code, Codeium, Supermaven, a ChatGPT window they paste into. The same survey found that 82% of developers use ChatGPT and 68% use GitHub Copilot, but 43% also use Claude models and 35% use Gemini. A 2025 industry survey found that 59% of developers run three or more AI tools in parallel. Not sequentially. In parallel.
Which models power those tools. GPT-4o, Claude Sonnet 3.5, Claude Sonnet 4, Gemini 2.5 Pro, a local Llama model, whatever the tool auto-selected. The Stack Overflow survey tracked this: 81% use OpenAI GPT models, 43% use Claude Sonnet, 35% use Gemini Flash. On a ten-person team, you might have four or five different models making architectural decisions about your codebase.
Which rules files exist in the repo, and whether anyone has read them. .cursorrules, CLAUDE.md, .github/copilot-instructions.md, AGENTS.md, .windsurf/rules, .cursor/rules/ with YAML frontmatter, JULES.md. Each tool has its own format. Some support scoping (Copilot's glob-pattern frontmatter since July 2025, Cursor's activation modes). Some are flat markdown. The content is almost identical across formats, but teams maintaining them end up with five copies of the same information, each slightly different, each slightly stale.
How they prompt. Verbose multi-paragraph instructions. Terse two-word commands. System prompts refined over months. No system prompts at all. Agent loops that iterate five times before producing output. Single-shot generation with manual editing afterward.
What context they have access to. Some developers have production access and can ask their AI about real system behavior. Some have internal documentation loaded into context. Some have nothing beyond the code in front of them.
The aggregate picture will surprise you. No individual choice is wrong -- that's the thing. Every developer picked tools that make them productive. But the result is ten developers with six different "architects" making decisions about your codebase, and none of those architects have read the same brief.
Why standardizing tools is the wrong move
The obvious reaction is to standardize. "Everyone uses Cursor with Claude Sonnet. Done."
This fails for four reasons, and any engineering leader who's tried a tool mandate already knows at least three of them.
First, developers resist tool mandates and productivity drops. An engineer who's spent six months building muscle memory in Neovim with a custom Claude Code workflow will not thank you for forcing them into Cursor. Their throughput drops for weeks or months. Multiply that across a team and you've traded a consistency problem for a productivity problem.
Second, the tool landscape changes every quarter. Claude Code went from zero to the most-used AI coding tool in eight months. Cursor acquired Graphite for its code review capabilities in December 2025. GitHub shipped Agent HQ. Windsurf launched, got traction, got acquired. Any tool you standardize on today may not be the right tool in ninety days. You're signing up for perpetual re-standardization.
Third, even identical tools produce inconsistent results. Give two developers the same editor, the same AI tool, the same model, and the same ticket. They'll prompt differently. They'll iterate differently. One will provide architectural context; the other won't. The tool is a multiplier of the developer's approach. Same tool, different approach, different code.
And fourth -- this is the real insight -- the tool is the wrong layer to standardize. You're trying to control the output by controlling the instrument. But the instrument isn't the variable that matters. What matters is what the instrument knows about your system before it starts generating code. Right now, that knowledge is different for every developer, in every session, with every tool.
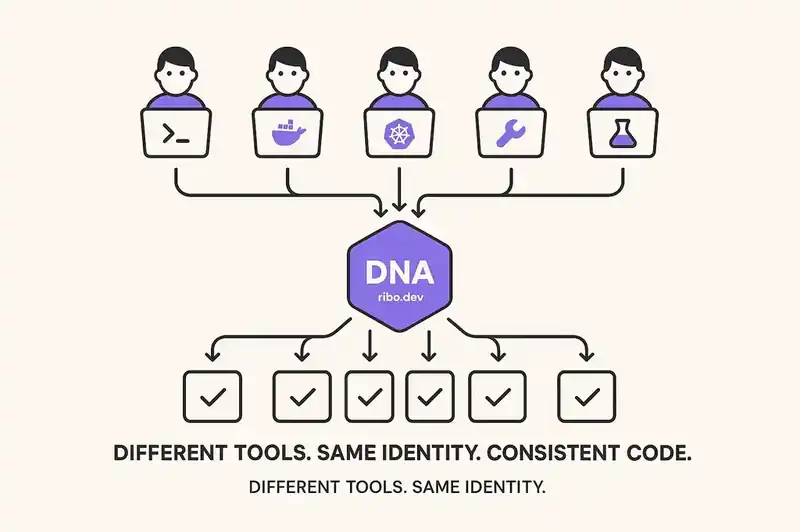
The layer that actually needs to be consistent
What should be identical across all of those developers, editors, AI tools, sessions, and prompts is the identity of the software itself: what the system is, what constraints it honors, what patterns to follow, what contracts exist between components.
This is the DNA layer. A declarative, machine-readable, version-controlled specification that gets injected into AI sessions as context -- regardless of which tool the developer uses.
When the engineer picks up that rate limiting ticket, their AI tool -- whatever it is -- reads the relevant slice: "The payments service declares a 99.9% SLO. All endpoints require authentication. Rate limiting uses the shared middleware pattern. Error responses follow RFC 7807. The service depends on Redis for state, and Redis connections are pooled through the shared client."
The developer doesn't need to know all this by heart or find the right Confluence page or have spent two years absorbing tribal knowledge. The identity layer supplies the context. The AI generates code that honors it. A junior with a basic Copilot setup and a senior with a custom Claude Code workflow both produce code that follows the same constraints, because the constraints came from the identity layer, not from anyone's memory or prompting skill.
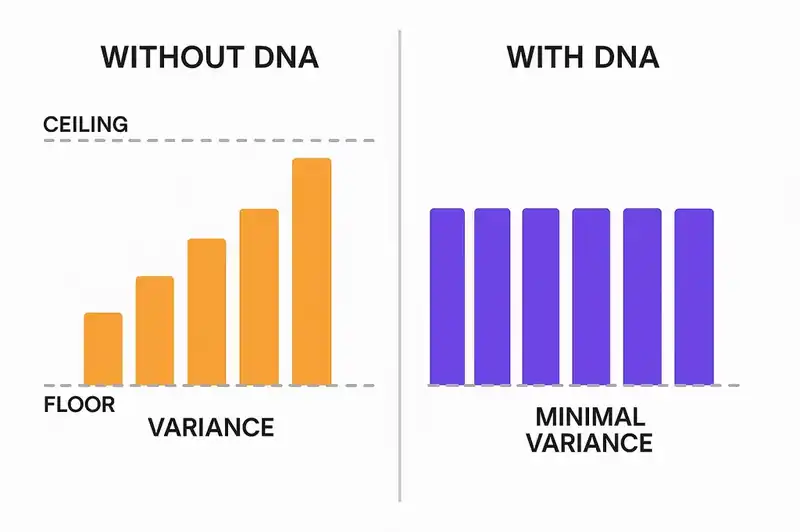
Individual skill becomes declarative context
Today, whether your code has good error handling depends on whether the developer writing it knows your error handling conventions. Whether your logging follows the team's structured format depends on whether the developer has seen the logging guide, remembers it, and prompts their AI to follow it. Whether a new endpoint respects the rate limiting pattern depends on whether the developer even knows the pattern exists.
All of these outcomes hinge on individual knowledge, and individual knowledge varies wildly across any team.
With an identity layer, these outcomes become declarative. Error handling conventions, logging format, rate limiting patterns -- they live in the DNA, and every AI tool reads them regardless of who's driving. The developer who joined last week gets the same constraints as the developer who's been there three years, because the constraints come from a declaration, not from tribal memory.
The team's floor rises to match its ceiling. You declared what the software is, and every tool enforces that declaration automatically.
GitClear's analysis of 211 million changed lines found that code churn -- code discarded within two weeks of being written -- rose from a 3.3% baseline in 2021 to 5.7-7.1% in 2024-2025. That churn represents code that was written, reviewed, merged, and then thrown away because it didn't actually fit. An identity layer catches the misfit before the code is written, not after it's shipped and reverted.
The rules file problem is a symptom
Teams that recognize the fragmentation problem often try to solve it with rules files. They write a .cursorrules file. Then someone uses Claude Code, so they write a CLAUDE.md. Then someone uses Copilot, so they create .github/copilot-instructions.md. Then Google ships Jules, so they add JULES.md. AGENTS.md emerged as a potential standard -- the Linux Foundation backed it, and most tools now read it -- but even AGENTS.md is a flat file. It's static text that the developer or tool must remember to load.
The proliferation of rule converters tells the story. Tools like rule-porter exist specifically to convert .cursor/rules/ into CLAUDE.md and copilot-instructions.md. Developers replace tool-specific files with symlinks to a single AGENTS.md to avoid maintaining five copies. These are workarounds for a structural problem: the rules live in the wrong place.
Rules files are per-tool. The identity layer is per-system. Rules files are static text. The identity layer is queryable. Rules files are all-or-nothing; you load the whole file or you don't. The identity layer is sliceable; when a developer works on the payments service, they get the payments service's contracts, constraints, and dependencies. Not the entire system's documentation. The relevant slice. In context. On demand.
What this looks like Monday morning
You don't get here by ripping out your existing setup. You get here incrementally.
Start with a contract audit. Pick your three most critical services. For each one, write down what it guarantees to consumers, what its performance constraints are, what patterns new code must follow, and what it depends on. Most teams discover they can't answer these questions without pulling three people into a room. That gap is the problem.
Then encode the answers as machine-readable declarations. Not a wiki page. Not a README section. A structured specification that a tool can parse and inject into context. This is what the DNA layer provides: a queryable, version-controlled store of what the software is.
Once the declarations exist, make them available to every AI tool. The identity layer is tool-agnostic by design. Cursor, Claude Code, Copilot, a custom LLM integration -- they all read from the same source. The developer's tool choice stops mattering, because the constraints come from the declaration, not from the tool.
Finally, validate against the declarations in CI. When a PR lands, check it against the declared contracts and constraints. Not just linting. Not just tests. Semantic validation: does this change violate a declared SLO? Does it break a contract that another service depends on? Does it introduce a dependency that conflicts with a declared constraint?
The hard parts
Maintaining a living identity layer takes discipline. Declarations that drift from reality are worse than no declarations at all, because they create false confidence. The reconciliation problem -- keeping the declaration in sync with the codebase -- is real engineering work.
Writing good declarations is also hard. Too vague and the AI ignores them. Too specific and they break every time someone refactors. The right level of abstraction is behavioral contracts and system constraints, not implementation details. "The payments service responds within 200ms at P99" is a good declaration. "The payments service uses a HashMap on line 47 of rate_limiter.rs" is not.
We've been working through these problems with production teams. The pattern that works is starting small -- two or three declarations per service, focused on the contracts that actually matter -- and expanding as the team builds confidence. The teams that try to declare everything on day one burn out. The teams that start with their highest-churn, highest-incident services see results in weeks.
The consistency problem in AI-assisted development is real, it's measurable, and it compounds as AI writes more code and developers adopt more tools. Standardizing tools won't solve it. A shared, declarative, tool-agnostic source of truth about what the software is will. Think of it this way: the developer's editor and AI tool are the instrument. The DNA layer is the score. You can let every musician pick their own instrument. You just need them reading from the same page.