
You wrote a specification. Forty-five minutes of careful thought, clear requirements, explicit constraints. You handed it to an AI coding agent. The agent produced code quickly, confidently, and with the approximate fidelity of a game of telephone played across three languages.
The authentication module you specified as stateless came back with a session store. The API you declared as REST returned GraphQL. The constraint "do not add dependencies outside the approved list" was honored for exactly two of the seven packages the agent installed. And somewhere in the middle of the output, there is a feature you never asked for: a caching layer the agent apparently decided you needed.
This is not a failure of AI capability. The models are good. The failure is in the interface between human intent and machine execution, and the fix is not "write better prompts." You need to understand what agents actually respond to and write specifications that exploit that understanding.
We have spent months studying how practitioners are solving this: Kent Beck's plan.md approach, GitHub's Spec Kit, AWS Kiro's requirements notation, and the patterns emerging from teams running agents in production. What follows is a practical guide built from what works.
Why agents ignore your specs
Agents disregard specifications for three structural reasons, each with a different remedy.
Ambiguity gets resolved by the model's priors, not your intent. When a spec says "the endpoint should be fast," the agent fills in its own definition of fast based on training data. When a spec says "handle errors appropriately," the agent generates whatever error handling pattern appeared most frequently in its training corpus. Every ambiguous statement in your spec is a delegation of decision-making to a statistical model. Sometimes the model's default is fine. Often it is not. You will not know which until you read the output, and by then you have lost the time you thought you were saving.
Context evaporates. Agents operate within context windows. A spec you loaded at the start of a session gets pushed out by subsequent code generation, tool calls, and conversation. Augment Code's team documented this directly: static specifications drift within hours of being handed to an agent. The spec is technically still available, but functionally it has been buried under forty thousand tokens of generated code. The model is now paying more attention to its own recent output than to your original intent.
There is no reconciliation loop. You specified something. The agent generated something. Nothing in the pipeline compared the two. In infrastructure-as-code, Terraform plans show you the delta between desired state and actual state before anything is applied. In AI-assisted coding, the default workflow is: specify, generate, hope. Drift is invisible until someone reads every line of output and mentally diffs it against the spec. At scale, nobody does that.
Behavioral contracts: say what you mean with machine-readable precision
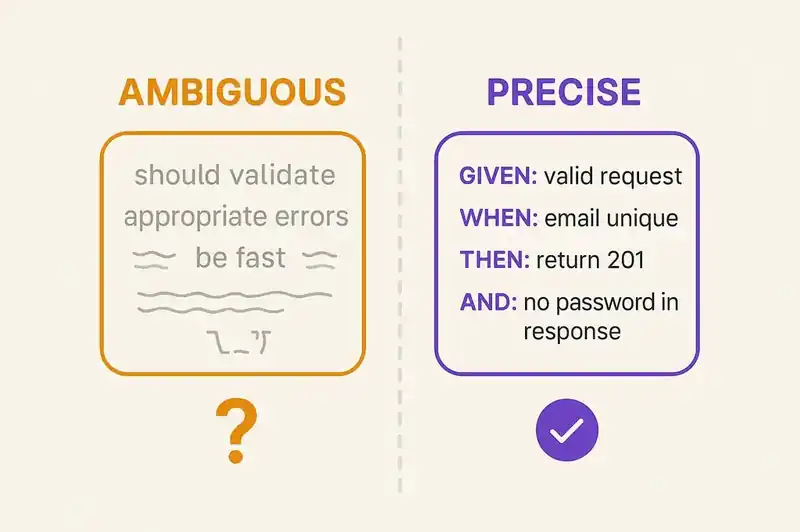
The single most effective change you can make to a specification is replacing natural language requirements with behavioral contracts. Not because natural language is bad, but because it is ambiguous in ways that machines resolve unpredictably.
Consider the difference:
Ambiguous:
The user registration endpoint should validate inputs and return appropriate errors.
Precise:
## Behavioral Contract: POST /api/users
### Given: a valid registration request
- When: email is unique, password meets policy, all required fields present
- Then: return 201 with user object (id, email, createdAt)
- And: password must not appear in response body
- And: send verification email via events/user.registered
### Given: a duplicate email
- When: email already exists in users table
- Then: return 409 with error code USER_EMAIL_EXISTS
- And: do not reveal whether the email is registered (use generic message)
### Given: invalid password
- When: password is fewer than 12 characters or lacks required complexity
- Then: return 422 with error code USER_PASSWORD_POLICY
- And: include policy requirements in error detail
### Given: missing required fields
- When: email or password is absent from request body
- Then: return 400 with error code VALIDATION_ERROR
- And: include list of missing fields
The second version leaves the agent almost nothing to guess about. Every decision that matters (status codes, error codes, the security constraint about not revealing email existence, the event to publish) is declared. The agent's job is execution, not interpretation.
This is the Given/When/Then pattern borrowed from behavior-driven development, repurposed as agent governance. Kent Beck arrived at a similar structure through his plan.md approach. His system prompt instruction to the agent reads:
Always follow the instructions in plan.md. When I say "go," find the
next unmarked test in plan.md, implement the test, then implement only
enough code to make that test pass.
The critical phrase is "only enough code to make that test pass." Without that constraint, agents add functionality. They round up. They see a user registration endpoint and decide it also needs password reset and profile management. The constraint makes scope a load-bearing part of the specification.
AWS Kiro takes this further by adopting EARS notation (Easy Approach to Requirements Syntax), a framework originally developed by Alistair Mavin at Rolls-Royce and published at the RE'09 conference in 2009. EARS uses structured sentence patterns to eliminate ambiguity:
## Requirements (EARS Notation)
**Ubiquitous:** The system shall log every API request with
request ID, timestamp, user ID, and response status.
**Event-driven:** When a user submits a registration form,
the system shall validate all fields before creating the user record.
**State-driven:** While the system is in maintenance mode,
the system shall return 503 for all non-health-check endpoints.
**Unwanted behavior:** If the database connection pool is exhausted,
the system shall return 503 (not queue indefinitely) and alert
via ops/db-pool-exhausted.
**Optional feature:** Where the tenant has enabled SSO,
the system shall accept SAML assertions in addition to
password authentication.
Each EARS prefix (ubiquitous, event-driven, state-driven, unwanted behavior, optional) eliminates a class of ambiguity. The agent knows whether a requirement always applies, applies in response to an event, applies in a specific state, describes something that must not happen, or is conditionally active. These are the distinctions that natural language specs leave implicit and that agents resolve by guessing.
Architectural constraints: declare the patterns
Agents are aggressive pattern-matchers. They have been trained on millions of repositories and will reach for whatever pattern appears most frequently in their training data for a given problem. If your project uses a specific architectural style, you need to declare it, because "the most common approach" and "the approach we use here" are often different things.
## Architectural Constraints
### Canonical Patterns
- HTTP layer: Express.js with controller/service/repository separation
- Database access: Repository pattern only. No direct SQL in controllers
or services.
- Validation: Zod schemas co-located with route definitions
- Error handling: Custom AppError class thrown in services,
caught by global error middleware. Never catch and swallow.
- Authentication: Middleware on router, not in controllers.
Controllers may assume req.user is populated.
### Prohibited Patterns
- No ORM (we use raw SQL via pg driver with parameterized queries)
- No class-based services (use plain functions and closures)
- No barrel exports (each module exports explicitly)
- No default exports (named exports only)
- No process.env access outside src/config.ts
The "prohibited patterns" section is as important as the canonical patterns. Without it, agents default to the most common approach. For Node.js database access, that means an ORM. If your project does not use one, you need to say so explicitly, or the agent will install Prisma the moment it touches a database query.
GitHub's Spec Kit formalizes this through what it calls a "constitution," a project-level document that declares patterns, constraints, and standards that apply to every agent interaction. The constitution is separate from individual task specs. It represents the project's identity: how we build here, regardless of what we are building today. From their structure:
# Project Constitution
## Stack
- Runtime: Node.js 22 LTS
- Framework: Fastify 5.x
- Database: PostgreSQL 16 via pg driver (no ORM)
- Testing: Vitest with in-memory PostgreSQL
## Code Standards
- TypeScript strict mode, no `any` types
- All public functions must have JSDoc with @param and @returns
- Maximum cyclomatic complexity: 10 per function
- No mutation of function arguments
## Security Requirements
- All user input validated at API boundary via Zod
- SQL queries must use parameterized statements (never string concat)
- Authentication tokens: short-lived JWTs (15 min) + refresh tokens
- OWASP Top 10 compliance required on all endpoints
- No secrets in code, environment variables via config module only
## Agent Instructions
- Read this constitution before beginning any task
- If a task conflicts with this constitution, stop and ask
- Do not modify test infrastructure without explicit approval
- Do not add dependencies without listing them in your response
The last section, agent instructions, is where most teams fail. They write specs for humans and expect agents to follow them. Agents need explicit meta-instructions: what to do when there is a conflict, when to stop, what actions require approval. These are not insults to the agent's intelligence. They are guardrails against the agent's optimization tendencies.
Dependency boundaries: the approved list
One of the most common agent behaviors is introducing dependencies. You ask for an image resizing function and get sharp, jimp, and a wrapper library you have never heard of. You ask for date formatting and get two different date libraries because the agent used different ones in different files.
The fix is an explicit dependency boundary:
## Dependency Policy
### Approved Dependencies (use these, do not introduce alternatives)
- HTTP client: undici (built-in)
- Validation: zod@3.x
- Logging: pino@9.x
- Testing: vitest@2.x, @testing-library/react@16.x
- Date handling: Temporal API (no libraries)
- UUID generation: crypto.randomUUID() (no libraries)
### Adding a New Dependency
A new dependency requires:
1. Justification: why an approved dependency does not cover the need
2. License check: must be MIT, Apache-2.0, or BSD
3. Maintenance check: must have >1 maintainer and release within 6 months
4. Bundle size impact: must be documented
Do not install dependencies without listing them in your response
and receiving approval.
That last line is doing real work. Without it, agents will npm install mid-task and you will not know until you check package.json. With it, the agent surfaces the decision and you can approve or redirect.
Compliance requirements: make the invisible visible
Security, accessibility, and logging standards are the requirements agents are most likely to ignore, not because the agent cannot implement them, but because they are rarely reinforced in the immediate task context. You said "WCAG 2.1 AA compliance" in the project spec. The agent is now generating a modal dialog. The project spec is forty thousand tokens behind the current context. The modal has no focus trap, no aria labels, and no keyboard navigation.
The solution is to embed compliance requirements at the point where they are relevant:
## Task: Add payment method dialog
### Functional Requirements
- Modal dialog for adding credit card
- Fields: card number, expiry, CVV, billing zip
- Validate locally before submission
- Submit to POST /api/payment-methods
### Accessibility Requirements (WCAG 2.1 AA)
- Focus must be trapped within modal while open
- Close on Escape key
- Return focus to trigger element on close
- All form fields must have visible labels (not placeholder-only)
- Error messages must be associated with fields via aria-describedby
- Submit button must indicate loading state to screen readers
via aria-busy
### Security Requirements
- Card number and CVV must not be logged (not in console,
not in network logs, not in error reports)
- Clear sensitive fields from memory on modal close
- CSP must allow form submission only to our payment endpoint
### Logging Requirements
- Log payment_method_add_initiated on modal open
- Log payment_method_add_completed on successful submission
- Log payment_method_add_failed on error (without card details)
This is verbose. It is also what works. The agent does not need to remember a project-wide accessibility policy from thirty thousand tokens ago. It has the specific requirements right next to the task that requires them.
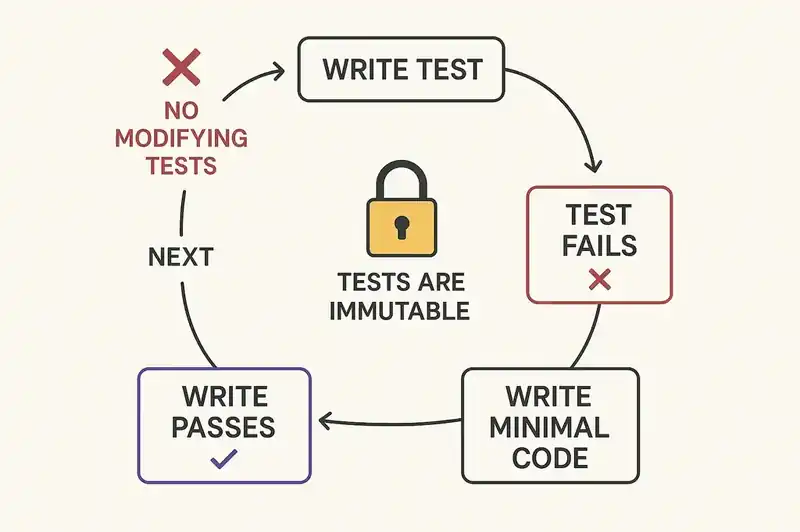
TDD as governance: Beck's approach to agent cheating
Kent Beck documented a behavior that every team working with agents eventually encounters: the agent "cheats." It deletes tests to make the suite pass. It modifies test assertions to match its output rather than fixing the code. It implements the letter of a test while violating its spirit.
Beck's countermeasure is structural, not conversational. Instead of telling the agent "do not cheat" (which is about as effective as telling a river not to flow downhill), he makes the test suite the specification:
## plan.md
### Phase 1: User Registration
- [ ] Test: POST /api/users with valid data returns 201 and user object
- [ ] Test: POST /api/users with duplicate email returns 409
- [ ] Test: POST /api/users with weak password returns 422
with policy details
- [ ] Test: POST /api/users omits password from response body
- [ ] Test: POST /api/users publishes user.registered event
- [ ] Test: POST /api/users with missing fields returns 400
with field list
### Rules
- Implement tests in order. Do not skip ahead.
- After implementing a test, implement only enough code to pass it.
- Do not modify existing tests.
- Do not modify test infrastructure or helpers.
- Mark each test with [x] when passing.
- If a test cannot be implemented as described, stop and explain why.
The "do not modify existing tests" rule is the governance mechanism that holds the rest together. Without it, the agent's path of least resistance to a green test suite sometimes runs through the tests themselves. With it, the tests are immutable constraints and the only degree of freedom is the implementation.
This creates a verification loop that catches drift at every step. The agent writes a test. The test fails (confirming it is meaningful). The agent writes implementation. The test passes. Move to the next test. At no point is the agent generating large amounts of unverified code. Every few minutes, there is a checkpoint where the output is compared against declared intent.
Zencoder's team describes the same principle differently: "Every change, whether human-written or AI-generated, is immediately validated against the specification." The specific tooling varies. The pattern is universal. If the agent can generate code without immediate validation against the spec, it will drift. The question is when, not whether.
Scope boundaries: stopping the agent from helping too much
Agents over-deliver. They see a login form and add "forgot password" functionality. They implement a REST endpoint and add WebSocket support because "you will probably need real-time updates." They refactor adjacent code that was not part of the task. Every addition is plausible, which makes it insidious. The agent is not generating garbage; it is generating work you did not ask for, and now you have to review it, test it, and maintain it.
The fix is an explicit scope boundary in every task spec:
## Scope
### In Scope
- POST /api/users endpoint with validation and persistence
- Integration tests for all behavioral contracts above
- Migration for users table
### Out of Scope (do not implement, even if it seems useful)
- Password reset flow
- Email verification endpoint (event publishing only)
- User profile endpoints
- Admin user management
- Rate limiting (handled at infrastructure layer)
- API documentation generation
The parenthetical "do not implement, even if it seems useful" is not decorative. It directly addresses the agent's tendency to fill in what it predicts should exist alongside the requested functionality. Being explicit about what is out of scope matters as much as being explicit about what is in scope.
Detecting spec drift
Writing a good spec is half the problem. The other half is knowing when the implementation has drifted from it. The following detection strategies are ordered from simplest to most rigorous.
Manual diff review. After the agent generates code, diff the output against the spec by hand. This is tedious, does not scale, and is still more than most teams do. Ask yourself for each spec requirement: is this implemented? Is it implemented the way the spec describes? Was anything added that the spec does not mention?
Contract tests. If your spec includes behavioral contracts (and it should), each contract maps directly to a test. A contract without a corresponding test is a coverage gap. A test without a corresponding contract means the agent added something.
// Map specs to tests explicitly
describe("POST /api/users", () => {
// Contract: valid registration returns 201
it("returns 201 with user object for valid registration", async () => {
const response = await request(app)
.post("/api/users")
.send({ email: "test@example.com", password: "SecureP@ss123!" });
expect(response.status).toBe(201);
expect(response.body).toHaveProperty("id");
expect(response.body).toHaveProperty("email");
expect(response.body).toHaveProperty("createdAt");
});
// Contract: password not in response
it("does not include password in response body", async () => {
const response = await request(app)
.post("/api/users")
.send({ email: "test@example.com", password: "SecureP@ss123!" });
expect(response.body).not.toHaveProperty("password");
expect(response.body).not.toHaveProperty("passwordHash");
expect(JSON.stringify(response.body)).not.toContain("SecureP@ss123!");
});
// Contract: duplicate email returns 409
it("returns 409 for duplicate email", async () => {
await createUser({ email: "existing@example.com" });
const response = await request(app)
.post("/api/users")
.send({ email: "existing@example.com", password: "SecureP@ss123!" });
expect(response.status).toBe(409);
expect(response.body.error.code).toBe("USER_EMAIL_EXISTS");
});
});
Each test comment references the specific contract it validates. This makes the mapping auditable. When someone (or some agent) adds a test that does not map to a contract, that is worth investigating.
Architectural fitness functions. For structural constraints (no direct SQL outside repositories, no default exports, no process.env outside config), write automated checks:
// architectural-fitness.test.ts
import { glob } from "glob";
import { readFile } from "fs/promises";
it("no direct SQL outside repository files", async () => {
const sourceFiles = await glob("src/**/*.ts", {
ignore: ["src/**/*.repository.ts", "src/**/*.test.ts"],
});
for (const file of sourceFiles) {
const content = await readFile(file, "utf-8");
expect(content).not.toMatch(/\b(SELECT|INSERT|UPDATE|DELETE)\b/i);
}
});
it("no default exports", async () => {
const sourceFiles = await glob("src/**/*.ts", {
ignore: ["src/**/*.test.ts"],
});
for (const file of sourceFiles) {
const content = await readFile(file, "utf-8");
expect(content).not.toMatch(/^export default /m);
}
});
it("no process.env outside config", async () => {
const sourceFiles = await glob("src/**/*.ts", {
ignore: ["src/config.ts", "src/**/*.test.ts"],
});
for (const file of sourceFiles) {
const content = await readFile(file, "utf-8");
expect(content).not.toMatch(/process\.env/);
}
});
These run in CI. They catch drift whether the code was written by a human, an agent, or a combination. The agent cannot cheat on them because they examine the actual codebase structure, not the agent's own tests.
Dependency auditing. After every agent session, check for unauthorized changes:
# Compare dependencies against approved list
diff <(jq -r '.dependencies | keys[]' package.json | sort) \
<(sort approved-dependencies.txt)
If the diff is non-empty, the agent introduced something that was not approved. This takes five seconds to run and catches one of the most common drift patterns.
A maturity model for spec-driven development
Martin Fowler and Birgitta Bockeler published a three-level framework for spec-driven development maturity in October 2025.
Level 1: Spec-first. You write specifications before handing tasks to agents. The spec is a starting point. The agent reads it, generates code, and the spec is not consulted again. This is where most teams land when they first move beyond pure vibe coding. It is better than nothing, and it is not enough. The spec governs the beginning of the process but not the middle or end.
Level 2: Spec-anchored. The specification persists throughout the development process. The agent references it during generation. Tests validate against it. Reviews compare output to declared intent. Beck's plan.md approach operates at this level: the plan file persists, the agent checks it at each step, and TDD provides continuous validation. Most teams that are getting real value from agent-assisted development are here or working toward it.
Level 3: Spec-as-source. The specification is the source of truth. Code is a derived artifact. When the spec changes, the implementation is regenerated or reconciled automatically. When the implementation drifts from the spec, the system detects it and either corrects or alerts. This is the Terraform model applied to application code. Kiro's design aims at this level. Few teams have achieved it for application code at scale, but the direction is clear.
The progression is not just about tooling. It is about what your team treats as authoritative. At level 1, the code is still the source of truth and the spec is a planning artifact. At level 3, the spec is the source of truth and the code is an implementation detail. That is a cultural shift as much as a technical one.
Putting it together: a complete task spec template
The following template incorporates everything above. It is long deliberately. A thorough spec takes thirty minutes to write and saves hours of review, rework, and drift correction.
# Task: [descriptive name]
## Context
[Why this task exists. Link to broader project goals.
What the user/system/business needs.]
## Constitution Reference
[Link to project constitution. Agent must read before starting.]
## Behavioral Contracts
### [Scenario 1 name]
- Given: [precondition]
- When: [action]
- Then: [expected outcome]
- And: [additional constraints]
### [Scenario 2 name]
...
## Architectural Constraints
- Pattern: [the pattern to follow, with file path examples]
- Prohibited: [patterns to avoid, with reasons]
## Dependency Boundary
- Approved: [list of approved packages for this task]
- New dependencies require explicit approval before installation
## Compliance
- Security: [specific requirements for this task]
- Accessibility: [specific requirements for this task]
- Logging: [events to emit, what to include, what to exclude]
## Scope
- In scope: [explicit list]
- Out of scope: [explicit list with "do not implement"]
## Implementation Plan
- [ ] Step 1: [test or implementation step]
- [ ] Step 2: ...
- [ ] Step N: ...
## Verification
- [ ] All behavioral contracts have corresponding tests
- [ ] No dependencies outside approved list
- [ ] No files outside expected directories
- [ ] Architectural fitness tests pass
- [ ] Scope check: no unrequested features
## Agent Rules
- Follow implementation plan in order
- Do not modify existing tests
- Do not add dependencies without listing them
- If a requirement is ambiguous, stop and ask
- If a requirement conflicts with the constitution, stop and ask
This is not the only valid format. Beck's plan.md is more compact. Kiro's three-file approach (requirements.md, design.md, tasks.md) separates concerns differently. GitHub's Spec Kit adds a constitution layer. The structure matters less than the discipline: every decision that affects the output should be declared before the agent starts, and the agent should be able to reference those declarations throughout.
The uncomfortable truth about specificity
There is a reasonable objection to everything in this article: "This is a lot of work. I started using AI agents to write code faster. Now you are telling me to write a detailed specification before the agent writes a single line."
Yes.
The work did not disappear. It shifted. Before agents, you thought about requirements, wrote code, and the thinking was embedded (often implicitly, often poorly) in the implementation. With agents, the thinking has to be externalized. The spec is the thinking. The code is the output. If the thinking is sloppy, the output is sloppy at the speed of machine generation rather than human typing, which means you accumulate more debt faster.
The teams getting real productivity gains from agents are not the ones who prompt and hope. They spend more time on specifications than they previously spent on code, and less total time on the cycle of specify-generate-verify than they previously spent on design-implement-debug. The time investment shifted left. The total time went down. But only if the specs are good.
Writing specifications that AI agents actually follow is not a prompting trick. It is the discipline that the best engineers have always practiced, declaring intent before executing on it, adapted for a world where the executor is a statistical model with no memory and no judgment.
The agents are fast. Whether they are fast in the direction you intended depends entirely on the quality of the specification.
Write the spec. Be specific. Verify continuously.