
A team adds one line of compliance to their identity layer on a Tuesday morning. By afternoon, the security slice-agent has opened seven pull requests across four services. The maintenance slice has updated three schema migrations. The telemetry slice has proposed two new metrics. One of the pull requests stalls because the new compliance rule conflicts with a tradeoff the team declared eighteen months ago. The agent does not guess. It files a clarification back to the identity layer. The engineer on call reads the conflict in plain English, picks the winner, pushes the update. The stalled PR picks up on its next pass and converges.
Most agentic SDLC setups never reach that Tuesday. They look busy instead. Every agent that hits ambiguity picks the most plausible answer it can reconstruct from the code around it, writes a PR against that answer, and moves on. Nobody ratified the choice. Nobody even knew a choice was made. The fix is not a better prompt. It is a place for agents to ask.
Agents guess because you gave them nowhere to ask
The 2025 DORA State of AI-assisted Software Development report is the clearest picture yet of what that looks like at scale. AI lifts individual throughput — Faros's analysis of the same dataset records 33.7% more tasks per developer and 66.2% more epics — and simultaneously tanks stability: bugs per developer up 54%, incidents per pull request up 242.7%. As IT Revolution summarized the pattern, AI does not create organizational excellence. It amplifies whatever you already have.
The teams amplifying in the wrong direction share a shape. Every coding agent rebuilds its understanding of the system from scratch each session, out of code and comments that have already drifted from what the team actually meant. When the agent hits a place where the code does not tell it what to do, there is nowhere authoritative to check. It has to decide. Then it decides again next session. Then again the session after that.
This is not a model problem. The model did exactly what you asked: produce a plausible answer and ship. The gap is that plausible is the best you gave it. Nothing in the system forces the agent to stop, flag the decision, and hand it to a human. Nothing in the system even remembers a decision was made. The output looks like code; it is actually a sequence of unratified judgment calls compressed into a diff.
Give agents a source of truth and a way to ask it questions, and the behavior changes. Asking becomes the default. Guessing becomes the fallback.
A source of truth the agent can read
The identity layer is authoritative, versioned, and declarative. It holds what the system must be, independent of how it is currently built. In ribo, DNA is written in twelve kinds: intent (must-statements about user-observable outcomes), contract (external promises), algorithm (computation rules and thresholds), evaluation (executable judgment: invariants, scenarios, regressions), pace (change ceremony per kind), monitor (observable SLOs), glossary (precise domain terms), integration (external system bindings), reporting (business and audit queries), compliance (regulatory obligations), constraint (technical limits), and tradeoff (priority when concerns clash).
Pace is the part most teams underestimate. Every DNA declaration carries a pace label: fast, medium, or slow. UI copy moves at fast. Public API shapes move at slow. The authentication model moves at slow. Pace is not a speed limit on work. It is a permission model for change. Microsoft's April 2026 Agent Governance Toolkit formalizes the same shape in different words: policy enforcement, identity verification, execution rings, trust scoring. A pace label is where that governance gets teeth. Agents regenerate fast-layer DNA freely. Medium requires review. Slow requires deliberate change with an engineer in the loop.
Evaluations are the backstop. They are executable, and they supersede everything: code style, agent opinions, diffs, vibes. If an invariant fails, the system is rejected. The OWASP Top 10 for Agentic Applications, published December 2025, names goal hijacking, tool misuse, and identity abuse among the top operational risks for autonomous agents. Every one of them assumes the agent has no authoritative reference to defer to. Evaluations are that reference, made enforceable.
The channel the agent uses when the truth is incomplete
Two things happen when a downstream agent runs its pass against DNA.
Most of the time it converges. The intent is clear, the contract is specified, the constraint is satisfiable, the code either matches or needs a straightforward edit. The agent writes the PR.
Some of the time it does not converge. Two intents imply different answers. A contract was declared without its error codes. A constraint was written but the tradeoff that resolves conflicts with it was never named. Or the agent found something the DNA never considered at all: a code path nobody thought about, an edge case a new provider introduced, a subtlety in the data that was never written down. In the guess-first world, this is where the agent picks a plausible answer and moves on. Here, the agent files a clarification.
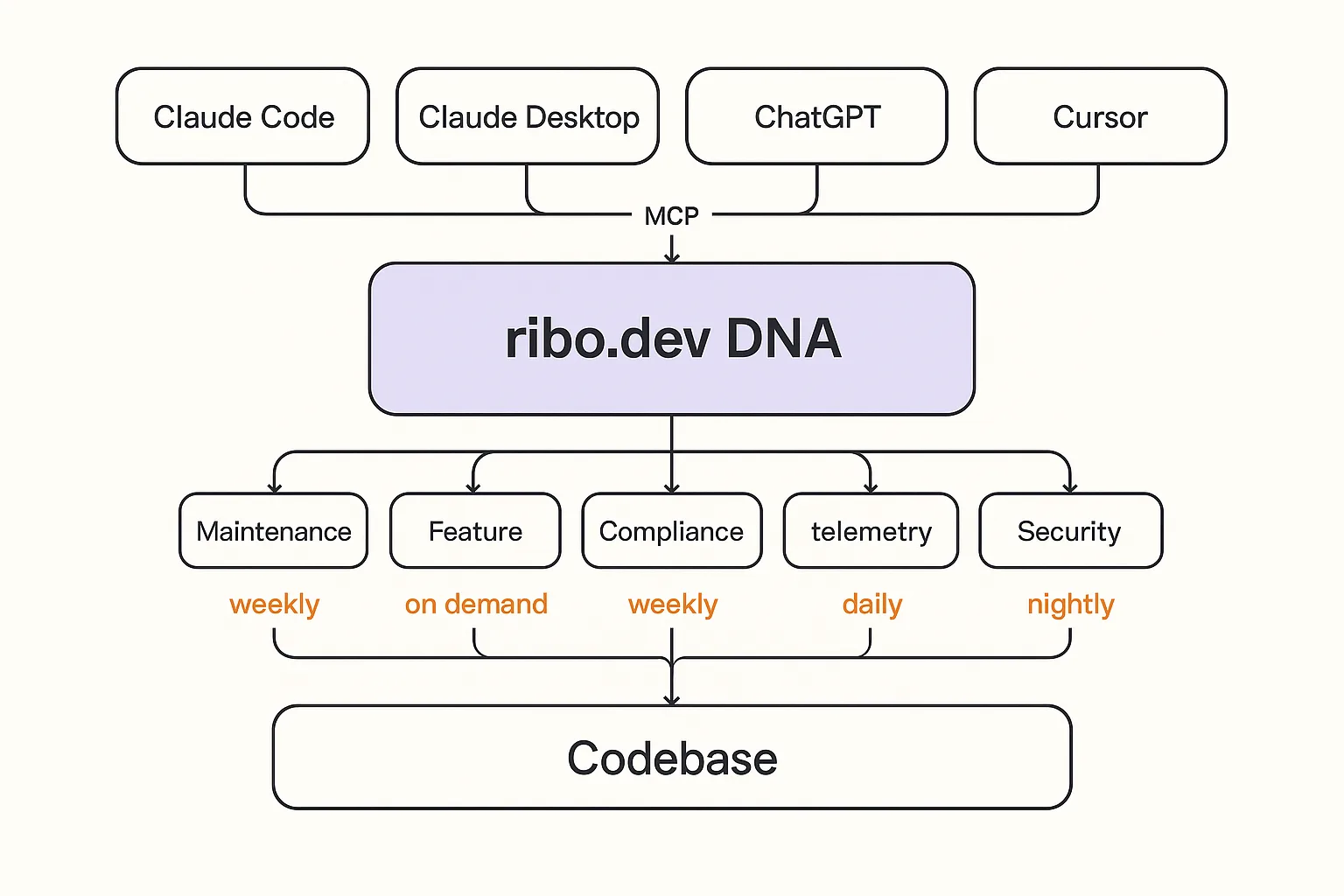
The clarification goes back to the identity layer, which is where you and your arsenal already spend your time. Claude Code, Claude Desktop, ChatGPT, Cursor, whichever mix your team runs, reading and writing DNA over the Model Context Protocol. MCP passed 97 million monthly SDK downloads by December 2025 across languages, with more than 10,000 active servers in production. Anthropic donated it to the newly formed Agentic AI Foundation, a directed fund under the Linux Foundation co-founded with Block and OpenAI and supported by Google, Microsoft, AWS, Cloudflare, and Bloomberg. Your arsenal already knows how to talk to a ribo-shaped server.
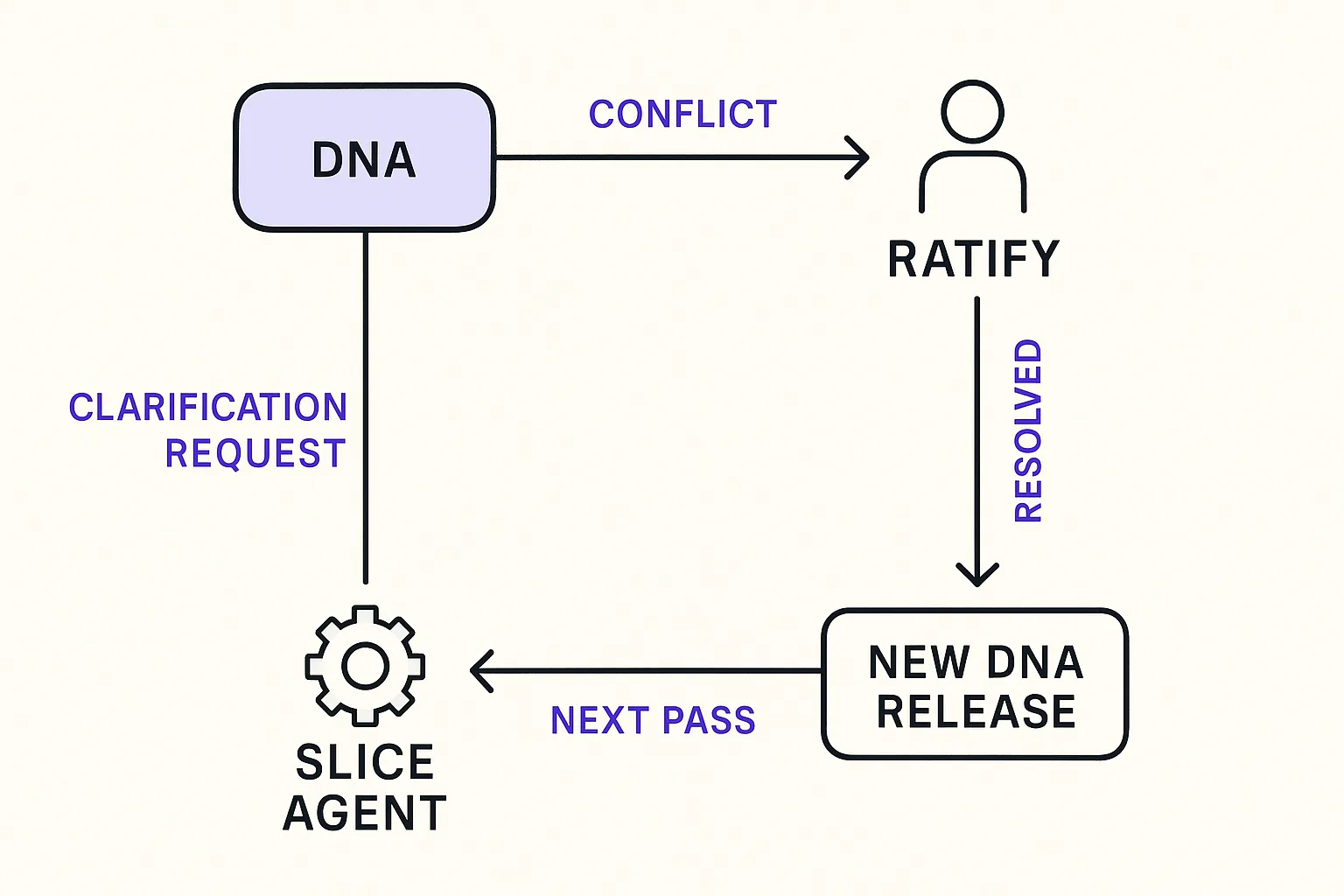
The clarification shows up in the same surface where you manage DNA. You resolve it in plain English. The resolution becomes a new DNA release. Downstream agents pick it up on their next pass. The stalled PR converges.
This is the piece most spec-driven setups skip. InfoQ's survey of the space describes the industry arc as making specifications executable and authoritative. That works for specs that are complete. It does not describe what the agent should do when the spec is wrong or missing. The clarification loop is the answer. Ambiguity never becomes code. It becomes a question back to the humans who ratify the answer.
Downstream is a fleet, not a hero
The mistake most teams make is deploying one general coding agent and hoping it learns the whole system. Ribo's downstream is not one agent. It is a set of slices, each with a narrow job and a predictable input.
- Maintenance reconciles existing code against current DNA and catches drift introduced by prior changes.
- Feature converges code toward newly ratified intent and contracts.
- Compliance maps code against the compliance kind and files clarifications when coverage is ambiguous.
- Telemetry maps code against monitor and reporting kinds, flagging missing metrics and broken SLO wiring.
- Security maps code against constraints, evaluations, and must-not rules, surfacing attack-surface changes a prompt-based agent would miss.
Slices exist because generalist agents cannot reliably maintain a codebase against their own memory. The SWE-CI benchmark for continuous-integration maintenance tasks found most models scoring below 0.25 on zero-regression rate across sustained passes, with only the strongest frontier configurations holding above 0.5. Agents without a narrow contract and a stable reference regress. Narrowing the contract is half the fix. The stable reference is the other half.
Each slice runs on its own cadence. Security can run nightly, or hourly on sensitive services. Compliance can run weekly before a release cut. Maintenance can run daily on a low-priority model tier. Feature runs on demand. None of them run continuously. Iterative passes are not a promise of speed. They are a budget knob.
This is the part that maps to economics directly. Each pass is bounded token spend against a known input (DNA) and a known output (delta against code). You choose the model per slice. Cheap model plus more passes for maintenance. Expensive model plus fewer passes for security-critical logic. You can spend twenty dollars a month on a slice that runs hourly against the smallest model, or two hundred a week on one that runs thoroughly against the largest. The decision is yours, and it is legible, because the budget is a dial and the work is repeatable.
The path from zero to ask-first
You do not need a complete DNA to benefit. You need enough for the first clarification to land.
Week one. Write intent and constraint entries for the part of the system that breaks most often. Ten to thirty declarations. Skip compliance, reporting, and evaluation at this stage. The goal is a first draft of what the system is supposed to do, in language an engineer and an agent can both read.
Month one. Add pace labels to everything you have written. This is the cheapest governance you can install, and it changes how agents behave immediately. Fast-layer regeneration becomes safe. Slow-layer change becomes visible.
Month two. Turn on exactly one downstream slice, compliance or security, whichever has the loudest stakeholders. Run it on a slow cadence, once a week. Read what it files as clarifications. Those are the holes in your DNA. Fill them in.
Month three. Add faster cadences for the slices whose output is clearly priced. Tune the model tier per slice. Track the DORA metrics that matter to your team against the new baseline. The throughput gains are easy. The stability gains are where the return lives.
Tuesday, again
The scene in the opening is not a demo. It is what happens when the agent has somewhere to ask and something to defer to, and someone is around to answer. The slice-agent opens PRs. The one that stalls does not stall quietly; it stalls out loud, with a question the engineer can answer in a sentence. By the end of the morning, the conflict is in the DNA, the PR is merged, and nobody spent their afternoon explaining to three different agents why the auth model is the way it is.
The teams that get there are not the ones with the best prompts. They are the ones who stopped asking their agents to hold the system in their heads and started letting them defer to something outside the code. The difference shows up as fewer guesses, fewer meetings about things that should have been written down, and PRs that close themselves once the human has answered the one question nobody realized needed asking.
Ask upstream. Converge downstream.
Agents stop guessing when they have somewhere to ask. We are building the tooling that makes DNA answerable by agents, not just readable by humans.