
The Model Context Protocol went from an internal Anthropic experiment to 97 million monthly SDK downloads in roughly eighteen months. It has first-class client support in ChatGPT, Claude, Cursor, Gemini, Microsoft Copilot, Visual Studio Code, and dozens of other tools. The ecosystem has grown to over 10,000 active servers. Anthropic donated MCP to the Agentic AI Foundation under the Linux Foundation, co-founded with Block and OpenAI, with support from Google, Microsoft, AWS, Cloudflare, and Bloomberg.
By any reasonable measure, MCP is becoming the universal standard for how AI agents interact with tools and data.
It also has no built-in identity layer. There is no native concept of "who is this software" or "what should this software be," and no mechanism for an agent to understand the intent, constraints, architecture, or compliance requirements of the codebase it is operating on.
That is the gap. And the security implications are compounding faster than the ecosystem is growing.
What MCP does, and what it does not do
MCP solves a real problem well. Before MCP, every AI tool integration was bespoke. If you wanted Claude to talk to your database, you built a custom integration. If you wanted Cursor to access your issue tracker, you built a different custom integration. MCP standardizes the protocol -- the transport layer, the message format, the capability negotiation -- so that any MCP-compatible client can talk to any MCP-compatible server.
Think of it as USB for AI agents. Before USB, every peripheral needed its own connector. USB standardized the physical and logical interface. MCP does the same thing for agent-tool communication.
But USB does not know what kind of document you are printing. It does not know whether you are authorized to print it. It does not know whether the document complies with your organization's data classification policy. USB moves bits. What the bits mean, whether they should be moved, and what constraints apply -- that is someone else's problem.
MCP is in the same position. It moves context. What the context means, whether the agent should act on it, and what constraints apply -- that is currently nobody's problem. Or rather, it is everybody's problem, solved inconsistently across a mess of static rules files that do not talk to each other.
The vulnerability surface

The security research community has been cataloging MCP vulnerabilities with increasing urgency, and the pattern is consistent: the protocol's lack of built-in identity and authorization creates attack surfaces at every layer.
Security researchers documented that 43% of MCP servers contain command injection vulnerabilities. Forty-three percent. Not edge cases. Not exotic attack vectors. Nearly half of all MCP servers are vulnerable to remote code execution through the protocol's standard communication channels.
The same research found that 33% of MCP servers allow unrestricted network access -- meaning a compromised server can download malware, exfiltrate data, or establish command-and-control communications. And roughly 5% of open-source MCP servers already contain tool poisoning attacks, where the tool description presented to the AI agent differs from what the tool actually does.
These are not theoretical risks. They are producing real breaches.
In mid-2025, security researchers demonstrated that the Supabase MCP server, when used with Cursor, could be exploited through prompt injection. The MCP server ran with service-role privileges that bypassed all row-level security. When the agent read user-submitted support tickets containing hidden instructions, it followed them -- reading sensitive integration tokens from private tables and leaking them into the ticket thread. The attack worked because the agent had no way to distinguish between legitimate tool input and adversarial injection. It had access, but no identity -- no understanding of what it should and should not do with that access.
The Postmark MCP supply chain attack demonstrated a different failure mode. An attacker published a typosquatted npm package called "postmark-mcp," mimicking the legitimate Postmark MCP server. For fifteen versions it behaved normally. On version 1.0.16, a one-line backdoor was added: every outgoing email was blind-copied to an attacker-controlled address. The package was downloaded roughly 1,500 times in a week before it was discovered. The server looked legitimate. Its MCP interface was correct. But its behavior was not aligned with what the consuming application intended, because there was no declared intent for the server to be validated against.
Three chained vulnerabilities in Anthropic's own mcp-server-git (CVE-2025-68145, CVE-2025-68143, CVE-2025-68144) combined with the Filesystem MCP server to achieve full remote code execution via malicious .git/config files. The protocol itself functioned correctly. The security failure happened at the layer above the protocol -- the layer where identity and intent should live.
The OAuth problem
The MCP specification includes an authorization mechanism based on OAuth. On paper, this addresses authentication. In practice, it introduces its own problems.
Red Hat's analysis of MCP security found that the authorization specification "includes implementation details that conflict with modern enterprise practices." The specification places session identifiers in URLs, violating security best practices and exposing session tokens in logs, browser history, and referrer headers.
But even if the OAuth implementation were perfect, it would solve the wrong problem. OAuth answers "who is this user?" It does not answer "what should this agent do?" or "what are the constraints on this codebase?" or "does this action comply with the organization's security policy?"
Authentication is necessary but insufficient. An agent can be perfectly authenticated and still do the wrong thing, because it has no understanding of what the right thing is. Identity -- in the deeper sense of "what is this software, what are its boundaries, what constraints does it honor" -- is not part of the protocol.
The rules file fragmentation
The industry has tried to fill this gap with static rules files. The result is a fragmentation problem that would be comic if it were not so consequential.
Claude wants CLAUDE.md. Cursor wants .cursorrules or .cursor/rules/. GitHub Copilot wants .github/copilot-instructions.md. Windsurf wants .windsurf/rules. Google's Jules wants JULES.md. Cline wants .clinerules. There is AGENTS.md attempting to be a cross-platform standard. There is llms.txt. There are .mdc files with YAML frontmatter.
That is at least seven different formats for expressing the same fundamental information: what this software is, what standards it follows, and what an agent should and should not do with it.
Each format is static. Each is maintained manually. Each drifts from reality at its own pace. And none of them are exposed through MCP itself. The agent connects to a tool via MCP, but its understanding of the codebase it is operating on comes from a separate, unrelated, format-specific file that may or may not exist, may or may not be current, and may or may not agree with the rules files maintained by other teams using other tools.
This is not a standards problem that will be solved by picking a winner among the seven formats. Even if the entire industry converged on a single rules file format tomorrow, you would still have static files that drift from reality, no validation mechanism, no version history, and no way for the rules to be exposed as live context through the protocol that agents are actually using.
What the missing layer looks like
The gap is structural. MCP provides the transport. Rules files provide fragmentary, inconsistent, static intent. Nothing connects the two.
A persistent identity layer exposed via MCP would bridge this gap. Instead of static files that agents may or may not read, identity becomes a live service that agents query through the same protocol they use for everything else. The agent connects to MCP, discovers available tools, and also discovers the identity of the software it is operating on: its architecture, coding standards, security policies, compliance requirements, and relationships to other systems.
This changes the security model in concrete ways. The Supabase vulnerability succeeded because the agent had no concept of the software's boundaries. With a live identity layer, the agent would have context: this service handles authentication tokens, user-supplied input must be sanitized, SQL operations require parameterized queries. The identity does not replace the agent's judgment. It informs it with the intent of the people who built and maintain the system.
The Postmark backdoor worked because there was no declared specification for what the server should do. A live identity layer would declare the expected behavior of the email service -- what it sends, to whom, under what conditions -- and deviations from that declaration would be detectable.
The rules file fragmentation exists because seven tools need the same information and none get it from a shared source. A live identity layer, exposed via MCP, becomes that source. The format problem disappears because the format is MCP itself.
The authorization gap
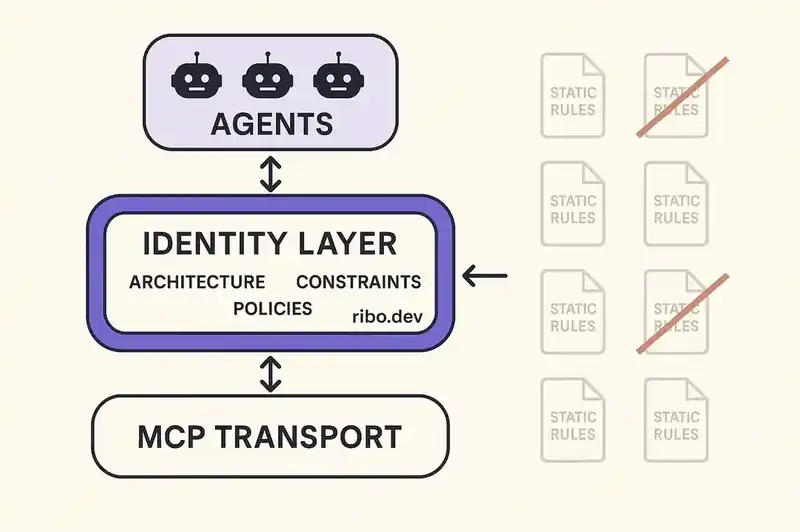
The deeper security problem is not authentication (who is making the request) but authorization (what should the agent be allowed to do in this specific context). Current MCP implementations handle authorization, to the extent they handle it at all, through coarse-grained mechanisms: this agent has access to this tool, or it does not.
But the interesting security questions are fine-grained. This agent has access to the database tool, but should it be writing to the production schema? This agent has access to the file system, but should it be modifying configuration files? This agent has access to the deployment pipeline, but should it be deploying to production without human approval?
These are not questions about the agent's credentials. They are questions about the software's identity -- its current state, its deployment policies, its change management requirements. Without a layer that encodes this identity, authorization decisions are either impossibly coarse (allow or deny the entire tool) or impossibly manual (a human reviews every action).
The Pillar Security research on MCP risks identified this pattern explicitly: agents chain tasks together sequentially, formulating new requests based on the output of previous actions. Each step in the chain is a new authorization decision. And each decision requires context that the protocol itself does not provide -- context about what the software is, what state it is in, and what operations are appropriate given that state.
A persistent identity layer does not replace traditional authorization. It informs it. The identity declares that this service is in production, handles PII, requires change approval above a certain risk threshold, and follows a specific deployment cadence. The authorization system consumes that declaration and makes fine-grained decisions that would be impossible without it.
The compliance dimension
The EU AI Act's requirements for high-risk AI systems become enforceable in August 2026. Among the requirements: organizations must demonstrate governance over AI systems, maintain documentation of system behavior, and provide audit trails. The European AI Office can request documentation, conduct evaluations, and demand source code access for general-purpose AI models.
MCP servers that interact with high-risk domains -- employment decisions, credit scoring, healthcare triage -- will need to demonstrate compliance. Without an identity layer, that demonstration requires manual documentation of every server's configuration, every tool's access scope, and every agent's behavioral constraints. With an identity layer, the compliance posture is encoded in the identity itself: this system processes data subject to GDPR, this tool operates within these boundaries, this agent follows these policies.
The Colorado AI Act, effective June 30, 2026, requires organizations to document AI systems that influence consequential decisions and demonstrate that those systems do not produce algorithmic discrimination. The documentation burden falls on whoever operates the system. When MCP servers are decentralized and ungoverned, the "whoever" is unclear, the documentation is nonexistent, and the compliance gap is invisible until an auditor makes it visible.
The path forward
MCP is the right protocol. The transport layer works, the ecosystem is thriving, and the adoption curve is steep. The problem is what MCP does not include -- and what the ecosystem has not yet built on top of it.
The path forward has three components.
Identity as a first-class MCP resource. The specification should support a mechanism for agents to discover the identity of the software they are operating on -- not as a static file, but as a live, queryable resource exposed through the protocol itself. The Agentic AI Foundation, which now stewards MCP, is the natural venue for this work.
Live context instead of static rules. The seven-plus rules file formats need to converge into a persistent layer that is version-controlled, continuously validated, and exposed via MCP. Not by picking a winner among existing formats, but by recognizing that static files are the wrong abstraction for information that changes as the software evolves.
Identity-informed authorization. MCP authorization needs to move beyond coarse-grained tool access to fine-grained, context-aware decisions informed by the software's declared identity. This does not require a new authorization protocol. It requires the context that makes existing protocols useful.
The MCP ecosystem has 97 million monthly SDK downloads and is growing. The security vulnerabilities cataloged in the first eighteen months are not flaws in the protocol. They are consequences of a missing layer -- the layer that tells agents not just what tools are available, but what the software is, what it should be, and what constraints it operates under.
That layer is identity. And until it exists as a first-class participant in the MCP ecosystem, the security gaps will continue to compound at the same pace as adoption.
The protocol that connects AI agents to everything needs to also connect them to the truth about what they are operating on.