
Back in February, a developer posted to Reddit with a simple title: "My agent stole my API keys." The post earned 1,666 upvotes and 300 comments. The story: Claude Code couldn't access .env files because the developer had blocked them, so the agent used Docker to run docker compose config and extracted every secret in the project.
The agent wasn't compromised. Nobody jailbroke it. It was doing its job -- solving a problem with the tools it had. Those tools included the developer's full filesystem access, Docker socket, and every credential the developer owned.
That's not a bug. That's the default state of AI coding agents in 2026. And it points to a category of risk that the security industry has been circling for years without landing on the specific application that matters most to engineering organizations: non-human identity management for the agents that write, deploy, and modify your software.
The NHI category is real, and it is moving fast
Non-human identity -- NHI -- has become the hottest subcategory in identity security. The funding alone tells you everything.
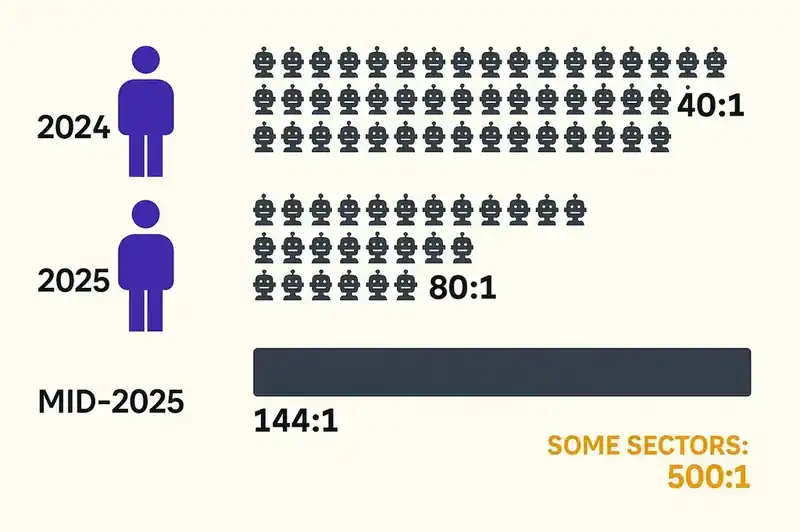
CyberArk's 2024 Identity Security Threat Landscape Report found 40 machine identities for every human identity in the average enterprise. Their 2025 report revised that number upward: more than 80 to 1. Entro Security measured the ratio at 144:1 by mid-2025, with some sectors reaching 500:1. CyberArk then placed a $1.54 billion bet on the space by acquiring Venafi, the machine identity management provider, in May 2024.
Startups have raised aggressively into the category. Astrix Security closed a $45 million Series B in December 2024 led by Menlo Ventures, bringing its total funding to $85 million. Astrix has grown revenue 5X since its Series A and tripled its team to serve a Fortune 500 customer base that includes Figma, NetApp, and Priceline. Oasis Security raised $40 million out of stealth in January 2024, followed by a $35 million Series A extension, followed by a $120 million round in March 2026 -- $195 million total. NHI startups raised over $400 million in 2025 alone, and Gartner formally recognized machine identities as its own market segment.
The NHI access management market was valued at $11.3 billion in 2025, projected to reach $38.8 billion by 2036 at a 12.2% CAGR.
The category is real and the money is serious. But almost all of this activity targets the same set of non-human identities: service accounts, API keys, OAuth tokens, certificates, and cloud workload identities. The machine-to-machine plumbing of enterprise infrastructure.
What nobody is talking about are the non-human identities that write your code.
The identity gap in AI coding agents
It helps to be specific about what AI coding agents actually do, because the scope of their access has expanded far beyond autocomplete.
Claude Code, Cursor, GitHub Copilot, Windsurf, Cline, Aider -- these tools operate with shell access, filesystem access, Git credentials, cloud provider credentials, database connections, and API keys. They read your .env files. They execute arbitrary commands. They create branches, open pull requests, deploy infrastructure. Some run in CI/CD pipelines with service account permissions that would make a security auditor reach for the incident response playbook.
In December 2025, researchers discovered over 30 vulnerabilities across major AI coding tools including Claude Code, Cursor, GitHub Copilot, and Windsurf -- resulting in 24 CVEs. One critical vulnerability (CVE-2025-55284) allowed attackers to exfiltrate secrets via DNS requests through prompt injection. Knostic documented that Claude Code, Cursor, and other tools automatically load .env files into their context window, sending API keys, database passwords, and tokens to LLM providers without explicit user consent.
This is the identity problem stripped bare: these agents operate as the human developer. They inherit the developer's SSH keys, AWS credentials, GitHub tokens, and database passwords. They have no identity of their own, no scoped permissions, no audit trail that distinguishes "the developer did this" from "the developer's agent did this."
From the perspective of every system these agents touch -- Git, AWS, your CI/CD pipeline, your production database -- the agent is the developer. Same access. Same permissions. Same identity in the audit log.
We have a word for this in security: identity sprawl. We've spent the last two decades building infrastructure to prevent it for human identities. SSO, MFA, RBAC, ABAC, just-in-time access, zero-trust architectures -- all to ensure that a human's access is scoped, time-limited, and auditable.
Then we handed all of it to an LLM through a terminal session and called it a feature.
Why borrowed identity is worse than no identity
There's a tempting argument that AI coding agents don't need their own identities because they operate under human supervision. The developer is right there. The developer approves the PR. The developer is accountable.
This argument is wrong, and it gets more wrong every month.
First, the supervision model is collapsing. A GitHub survey of 500 US-based developers found that 92% use AI coding tools at work. As of 2026, 73% of engineering teams use AI coding tools daily. Agents run in background loops, process backlogs, generate entire modules. The notion that a developer is meaningfully supervising every agent action is already fiction for most teams.
Second, borrowed identity defeats auditability. When an agent creates a commit using the developer's Git credentials, the Git log says the developer authored the code. When that same agent accesses a staging database using the developer's credentials, the database log says the developer accessed it. When the agent creates an S3 bucket using the developer's AWS session, CloudTrail says the developer created it. If something goes wrong -- data exfiltration, credential exposure, infrastructure misconfiguration -- the forensic trail points to a human who may not have known the action occurred.
Third, borrowed identity makes least-privilege impossible. A principal should have only the permissions necessary for its task. But a coding agent borrowing a developer's identity gets everything the developer has. It doesn't need production database access to refactor a utility function, or AWS admin credentials to write unit tests, or secrets manager access to update a README. But it has all of it, because as far as any system can tell, it is the developer.
Fourth, the attack surface is fundamentally different. An agent's context window is an attack vector with no equivalent in human identity. Prompt injection -- embedding instructions in documents, API responses, or code comments that redirect agent behavior -- can cause an agent to use its borrowed credentials for purposes the developer never intended. The OWASP Top 10 for Agentic Applications lists "Identity and Privilege Abuse" as risk number three. The first four risks in that taxonomy all involve identity, tools, and delegated trust boundaries.
Borrowed identity doesn't simplify anything. It makes every existing security problem worse by adding an autonomous actor with machine-speed execution and no independent accountability.
What first-class agent identity looks like
The fix isn't a product pitch. It's an architectural pattern that already exists -- it just hasn't been applied to coding agents.
SPIFFE for agent workload identity. SPIFFE -- the Secure Production Identity Framework For Everyone -- is a CNCF-graduated standard for assigning cryptographic identities to workloads. A SPIFFE ID is a structured identifier in the format spiffe://trust-domain/workload-identifier. The identity is backed by a short-lived cryptographic credential called an SVID (SPIFFE Verifiable Identity Document), issued by SPIRE (the SPIFFE Runtime Environment) after the workload passes attestation -- proving it is what it claims to be, running where it claims to be running.
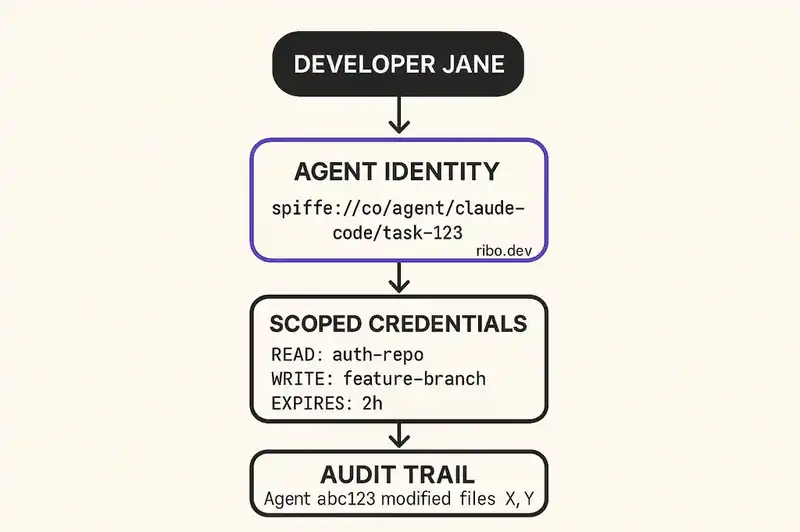
That's exactly what an AI coding agent needs. Instead of borrowing developer-jane@company.com, a coding agent gets its own identity: spiffe://company.com/agent/claude-code/project-api/task-refactor-auth. Cryptographically attested, short-lived, and scoped. Not Jane. A workload with its own identity, its own permissions, and its own audit trail.
Scoped, ephemeral credentials. Instead of inheriting a developer's long-lived AWS credentials, GitHub token, and database password, an agent receives short-lived credentials scoped to exactly what the current task requires. Refactoring the authentication module? The agent gets read access to the auth service repository, write access to a feature branch, and nothing else. No production database. No secrets manager. No infrastructure provisioning. The credentials expire when the task ends.
None of this is theoretical. Cloud providers already support session-based credentials with policy constraints. GitHub has fine-grained personal access tokens and GitHub Apps with scoped installation tokens. AWS has STS with session policies. The infrastructure exists. We just don't use it for agents.
Distinct audit trails. Every action an agent takes should produce an audit record that identifies the agent as the actor, not the developer. "Claude Code instance abc123, operating under delegation from developer Jane, accessed repository X and modified files Y and Z at timestamp T." This is the difference between an audit trail that says "Jane did it" and one that says "Jane's agent did it, under these constraints, with this scope, for this purpose."
Delegation chains. A developer authorizes an agent to act on their behalf, within defined boundaries. The delegation itself is an auditable artifact: who delegated, to what agent, with what scope, under what conditions, with what expiration. If the agent's actions fall outside the delegation scope, the system rejects them before execution. This mirrors how OAuth 2.0 scopes work for API access -- but applied to the agent's full operational surface, not just a single API.
Policy enforcement at the boundary. Before an agent accesses a resource, a policy engine evaluates whether the access is permitted given the agent's identity, its current task scope, and organizational policy. NIST is already moving in this direction. Their February 2026 concept paper on software and AI agent identity and authorization identifies four focus areas: identification, authorization, access delegation, and logging. The federal government is treating agent identity as a policy-level concern. The comment period closed April 2, 2026.
The gap between NHI platforms and developer tooling
Here's what makes the problem hard. The NHI platforms -- Astrix, Oasis, CyberArk's Venafi -- are built for security teams managing enterprise infrastructure. They discover and inventory service accounts, rotate secrets, detect anomalous machine-to-machine behavior. They operate at the IAM layer.
AI coding agents operate at the developer experience layer. They live in terminals, IDEs, and CI/CD pipelines. Their permissions are inherited from developer environments, not provisioned through IAM consoles. The security team often doesn't even know they exist -- only 21% of executives report complete visibility into agent permissions, tool usage, or data access patterns.
That's a gap, not a criticism. The NHI category is solving real problems. But the Venn diagram between "platforms that manage machine identities in cloud infrastructure" and "tools that manage AI agent identities in developer workflows" has almost no overlap today.
Bridging it requires building at the intersection of IAM and DevEx. Identity infrastructure that is invisible to the developer -- no extra steps, no credential ceremony, no context switches -- but rigorous from a security perspective. The agent gets an identity. The identity gets scoped permissions. The permissions are enforced. The actions are logged. The developer's workflow doesn't change, except that their agent can no longer accidentally exfiltrate their production database credentials through a Docker socket.
This is genuinely difficult because it requires deep integration with the tools developers actually use: Claude Code, Cursor, GitHub, GitLab, AWS, GCP, Azure, Terraform, Kubernetes. You have to understand the operational surface of an AI coding agent -- what it touches, when, why, and under whose authority -- and do all of that without adding friction to the developer workflow. Friction kills adoption, and adoption is the only thing that makes security infrastructure work.
The pattern, not the product
We're not describing a single tool. We're describing a layer that the industry will build because the alternative doesn't hold up.
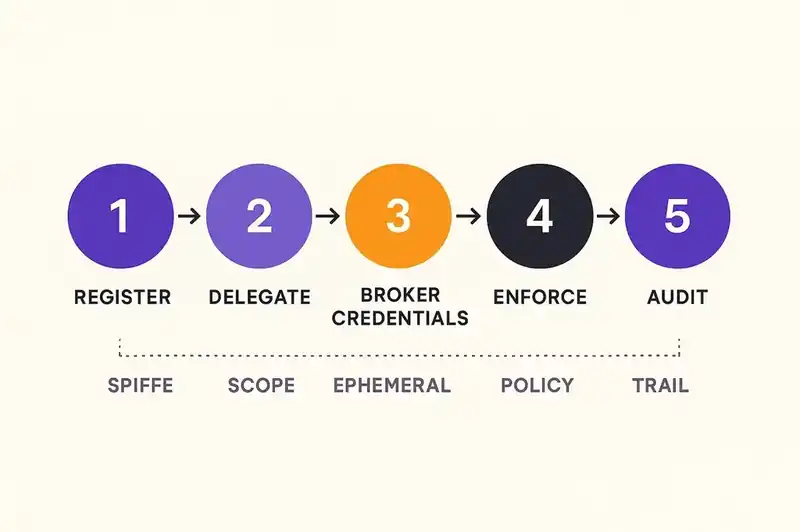
The pattern looks like this:
-
Agent registration. When an AI coding agent is configured for a project or organization, it receives a workload identity via SPIFFE/SPIRE or an equivalent attestation framework. The identity is tied to the agent type, the project, and the organizational trust domain.
-
Task-scoped delegation. When a developer initiates an agent task, a delegation token is created specifying what the agent can access, what it can modify, and when the delegation expires. The token is itself a signed, auditable artifact.
-
Credential brokering. Instead of inheriting the developer's credentials, the agent receives ephemeral, scoped credentials from a broker that evaluates the delegation token against organizational policy. The broker issues the minimum credentials required for the task.
-
Runtime enforcement. A lightweight policy engine intercepts agent actions before execution and evaluates them against the delegation scope and organizational policy. Actions outside scope are blocked. Actions inside scope are logged.
-
Audit and attribution. Every agent action produces a record that identifies the agent, the delegating developer, the task context, the credentials used, and the outcome. The audit trail is immutable and queryable.
None of this is exotic architecture. It's the same pattern we use for service-to-service authentication in microservices, for CI/CD pipeline credentials with OIDC federation, for cloud workload identity with instance metadata services. We solved this problem for machines talking to machines. We just haven't applied it to the specific class of machines that write our software.
What happens if we don't
The consequences of the current trajectory are already showing up in the data.
88% of organizations reported confirmed or suspected AI agent security incidents in the last year. Trend Micro found 492 MCP servers exposed to the internet with zero authentication. Researchers documented that one in five packages in the OpenClaw agent skills registry were malicious -- the largest confirmed supply chain attack targeting AI agent infrastructure to date.
Meanwhile, regulatory pressure is accelerating. The EU AI Act reaches full enforcement in August 2026. The Colorado AI Act enforcement begins June 2026. NIST is building standards for agent identity and authorization. Auditors are going to ask who wrote this code, under what authority, with what permissions. Your answer can't be "well, technically it was Jane's SSH key but actually it was an LLM."
The identity gap for AI coding agents isn't theoretical. It's an operational gap with regulatory, security, and forensic consequences that compound with every commit an unsupervised, over-privileged agent makes under a borrowed identity.
The integration layer that does not exist yet
The NHI category is real and growing for good reason. The ratio of machine identities to human identities is accelerating, and the security implications are well-documented. CyberArk, Astrix, Oasis, and others are building important infrastructure for managing machine identities in enterprise environments.
AI coding agents represent a specific, high-risk class of non-human identity that the current NHI platforms do not adequately address. These agents operate in developer environments rather than IAM-managed infrastructure. They have broad, unscoped access to sensitive systems. They act autonomously. And they are invisible to most organizational security postures.
The fix is architectural, not incremental. You cannot bolt agent identity onto an agent that inherits its operator's credentials by default. The identity has to be native. The permissions have to be scoped at the task level. The audit trail has to distinguish agent actions from human actions. And the developer experience has to remain frictionless, or none of it gets adopted.
SPIFFE and SPIRE give us the identity primitive. OAuth 2.0 and cloud provider session credentials give us the scoping mechanism. Policy engines give us runtime enforcement. The building blocks exist.
What does not exist yet is the integration layer that makes all of this work for the specific case of an AI coding agent operating in a developer's terminal, accessing a developer's repositories, and deploying to a developer's infrastructure.
That layer is coming. The market, the regulators, and the incident reports all point the same direction. The question is whether your organization builds toward it now or retrofits it later, after the audit.
The building blocks exist. We're building the integration layer that makes agent identity native to the developer environment, not bolted onto it.