
Gartner recorded a 1,445% surge in multi-agent system inquiries from Q1 2024 to Q2 2025. Not a typo. Fourteen hundred percent. In a fifteen-month window, the question shifted from "should we use an AI agent?" to "how do we coordinate a fleet of them?"
We know the answer to the first question. The second one is going to break things.
The fleet is already here
GitHub launched Agent HQ at Universe 2025 -- a platform designed as mission control for an entire fleet of AI agents operating inside a single codebase. Not one assistant. A fleet. The architecture lets teams orchestrate agents from OpenAI, Anthropic, Google, or their own custom builds, all running in isolated environments with scoped permissions. GitHub's framing was explicit: the critical question for 2026 is not "how can an agent help me code?" but "how can our team use a fleet of agents to improve our entire workflow?"
Atlassian shipped Rovo Dev in October 2025. It reads your Jira tickets, understands your repo, generates code, runs checks, opens pull requests, and reviews the work of other agents. It connects to Confluence, Bitbucket, and Compass, pulling organizational context into every action. Rovo Dev doesn't assist a developer. It operates as a developer -- planning, building, and shipping with minimal human involvement.
Factory raised $50 million at a $300 million valuation, led by Sequoia, NEA, J.P. Morgan, and Nvidia. Their Droids reached number one on Terminal Bench, the most demanding general software development benchmark. Factory's thesis is agent-native development: not agents that help humans write code, but agents that own entire engineering workflows end to end.
Cursor acquired Graphite in December 2025 for well over Graphite's $290 million valuation. The deal was about code review -- the realization that when agents produce code at industrial volume, the review bottleneck becomes the binding constraint. Cursor had already crossed $1 billion in annualized revenue. It is assembling the full stack of agentic development: generation, review, and iteration.
This is not a trend piece about what might happen. These are transactions that already closed. Platforms that already shipped. Fleets that are already running.
One agent is a tool. Many agents is a distributed system.
The industry is about to learn a lesson that infrastructure engineers absorbed decades ago.
A single agent modifying a codebase is a tool. It takes instructions, produces output, and a human evaluates the result. The feedback loop is tight. The failure mode is local. If the agent does something wrong, you see it, you fix it, you move on.
Two agents modifying the same codebase is a coordination problem. Three agents is a distributed system. Ten agents is a distributed system with all the pathologies that distributed systems have always had -- split-brain scenarios, race conditions, conflicting writes, state divergence, and the impossibility of maintaining consistency without an explicit protocol for achieving it.
This is not a theoretical concern. The 2025 DORA report and complementary telemetry analysis from Faros AI (covering 10,000+ developers) found that high AI adoption correlated with a 9% increase in bug rates, a 91% increase in code review time, and a 154% increase in pull request size. That data comes from a world where most teams use one agent at a time. Scale that to fleets and the numbers compound.
Cogent's 2026 multi-agent failure playbook documents three primary collapse modes. Infinite loops: agents with conflicting directives bounce work endlessly, burning API budgets in minutes. Hallucinated consensus: agents converge on fabricated data because each treats the others' outputs as ground truth. Resource deadlock: agents compete for shared resources, creating circular dependencies where each waits on the other and neither proceeds.
All three failures have direct analogs in distributed systems literature. And distributed systems solved them the same way every time. With a consensus protocol. With a shared source of truth. With an explicit agreement about what the system IS before any node is allowed to act.
The consensus problem, restated
Leslie Lamport described the Paxos consensus algorithm in 1998. The problem it solves is deceptively simple: how do you get multiple independent nodes, operating concurrently with imperfect communication, to agree on a single value?
The answer is not "let each node do its best and reconcile later." That produces divergence. The answer is not "give every node the same instructions and hope for consistency." Identical instructions executed against different local states produce different results. The answer is a protocol -- a structured mechanism that guarantees all non-faulty nodes converge on the same value, even when messages are lost and timing is uncertain.
Raft, published in 2014, made the insight accessible: you need a leader that maintains the authoritative state. Followers replicate it. If the leader fails, a new one is elected. The system continues from the last agreed-upon state. Etcd uses Raft. Consul uses Raft. Every serious distributed database uses some variant. Not because it's elegant, but because without it, the system drifts. And inconsistency in a distributed system is not a bug you can patch. It's a structural failure that propagates.
Multi-agent development is a distributed system. The agents are the nodes. The codebase is the shared state. And right now, there is no consensus protocol.
What drift looks like in practice
Imagine a codebase with three agents operating concurrently. Agent A is assigned to refactor the authentication module for better testability. Agent B is building a new feature that depends on the authentication module's current interface. Agent C is migrating the database layer, which the authentication module reads from.
Each agent has its instructions. Each agent is competent. Each agent does exactly what it was told.
Agent A restructures the auth module's public API to make it more testable, breaking the interface that Agent B is coding against. Agent B writes integration tests that pass against the old interface, which no longer exists by the time its PR is merged. Agent C changes the database schema underneath the auth module, which Agent A's refactor assumed would remain stable.
Nobody made a mistake. Every agent followed its instructions. The system still broke, because no agent had access to a shared understanding of what the auth module IS -- its contracts, its constraints, its relationships to the rest of the system. Each agent had a local view. Local views diverge. Divergence is drift. Drift is the default state of any distributed system without consensus.
Git worktrees help with isolation. Branch-per-agent strategies prevent raw merge conflicts. But merge conflicts are the easy problem. The hard problem is semantic drift -- when changes are syntactically compatible but behaviorally contradictory. Two PRs that merge cleanly but break the system when combined. Git cannot detect this. No version control system can. The conflict isn't in the text. It's in the intent.
The reconciliation model
ArgoCD introduced a pattern that the software industry has not yet recognized as a general solution.
In ArgoCD's GitOps model, the desired state of a Kubernetes cluster is declared in a Git repository. The reconciliation loop runs continuously -- by default, every three minutes. It compares the live state of the cluster to the declared desired state. If they differ, ArgoCD corrects the drift, bringing the live state back into alignment with the declaration. The Git repository is the single source of truth. The cluster is the runtime. The reconciliation loop is the consensus mechanism.
This pattern has a name in control theory: a closed-loop control system. You declare the desired state. You observe the actual state. You compute the difference. You apply the correction. Repeat. The system converges on the declared state, not because any single actor is perfect, but because every actor is continuously reconciled against the same truth.
Now apply this pattern to multi-agent development.
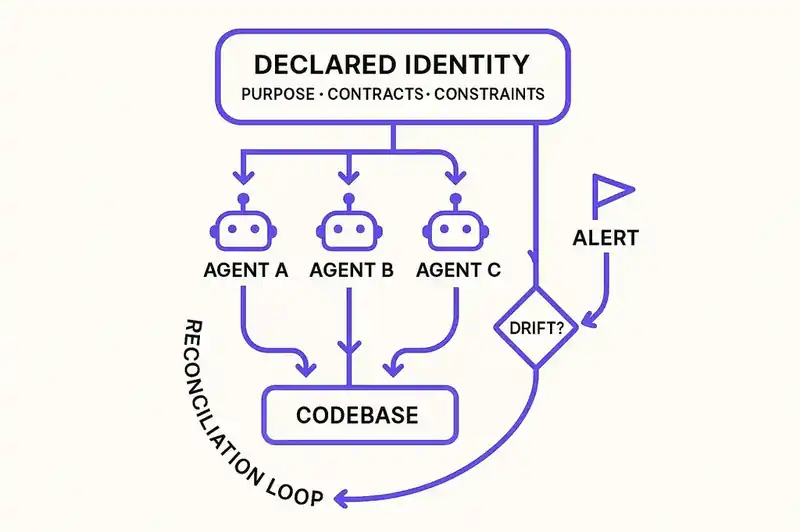
Instead of a Kubernetes manifest, imagine a declarative identity for a software system. Not just its architecture diagram. Not just its API spec. A complete declaration of what the system IS: its purpose, its behavioral contracts, its constraints, its module boundaries, its invariants, its relationships. A specification that is machine-readable, version-controlled, and precise enough for an agent to validate against.
Each agent, before it writes a line of code, reads the declaration. Each agent's output is validated against the declaration before it merges. If an agent's changes violate a declared contract -- if Agent A's refactor breaks an interface that the declaration says is stable, or if Agent C's migration changes a schema that the declaration says Agent A depends on -- the violation is caught. Not by another agent. Not by a human reviewer scrolling through a diff. By reconciliation against the declared identity.
The declaration is the leader in the Raft protocol. Every agent is a follower. The system converges because every participant agrees on what the system should be.
Why instructions are not identity
The obvious objection: "We already give agents instructions. We write detailed prompts. We provide context. Isn't that enough?"
No. And the reason is the same reason that distributed systems don't achieve consensus by giving every node the same instruction manual.
Instructions describe actions. Identity describes state. "Refactor the auth module for testability" is an instruction. "The auth module exposes the following public contracts, depends on the following schemas, and must honor the following invariants" is identity. The instruction tells the agent what to do. The identity tells the agent what the system IS -- which constrains what the agent is allowed to do.
The difference matters because instructions are interpreted locally. Each agent receives its own instructions, in its own context window, with its own understanding of the codebase. Two agents with different instructions can produce conflicting changes. But even two agents with the same instructions can produce conflicting changes, because they apply those instructions against different local snapshots of a changing system.
Identity is global. It is the shared state that all agents read from. It doesn't change because an agent is working on something. It changes deliberately, through a versioned update that all agents can observe. It is the equivalent of the replicated log in Raft -- the canonical sequence of states that every participant agrees on.
Anthropic's 2026 Agentic Coding Trends Report identifies multi-agent coordination as a top strategic priority, noting that "multi-agent systems replace single-agent workflows, enabling parallel reasoning across separate context windows, where an orchestrator delegates subtasks to specialized agents working simultaneously, then stitches everything together." That orchestrator needs something to stitch against. A set of instructions is not it. A declared identity is.
The scaling cliff
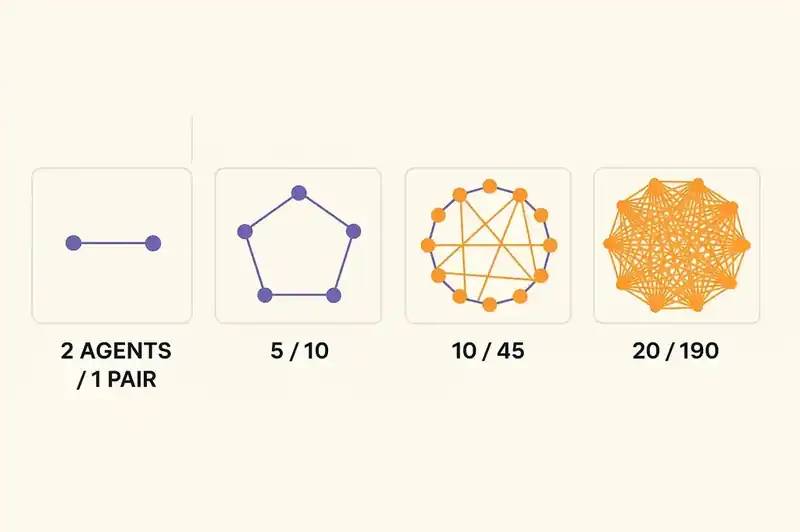
The problem gets worse with scale, not linearly but combinatorially.
With two agents, there is one pairwise interaction to worry about. With five agents, there are ten. With ten agents, there are forty-five. With twenty agents -- and GitHub's Agent HQ is explicitly designed to manage fleets -- there are one hundred and ninety pairwise interactions. Each interaction is a potential source of semantic drift.
Gartner predicts that by 2027, 70% of multi-agent systems will use narrowly specialized agents. Narrow specialization means each agent knows its domain deeply but knows the rest of the system shallowly or not at all. A database migration agent has no model of the frontend. A security hardening agent has no model of the performance requirements. A feature agent has no model of the compliance constraints.
This is the exact topology that produces drift. Specialists with deep local knowledge and no shared global context. The only thing that prevents divergence is an explicit, machine-readable declaration of the global context that every specialist can read and validate against.
Without it, coordination cost grows faster than productivity gains. You add more agents to move faster, and spend more time reconciling their conflicts than you saved by parallelizing the work. This is Amdahl's Law applied to multi-agent development: the speedup from parallelism is limited by the serial coordination overhead. The only way to reduce that overhead is a shared frame of reference that doesn't require synchronous communication to maintain.
What the identity layer looks like
Not a README. Not a Confluence page. Not a collection of markdown files that agents may or may not read.
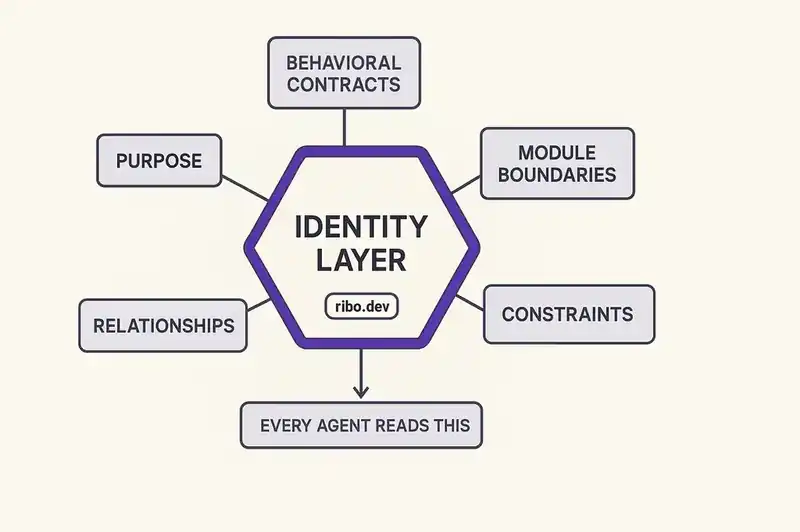
The identity layer is a declarative, machine-readable, version-controlled specification of what the software system IS. It includes:
Behavioral contracts. What the system guarantees to its consumers. The auth module returns a session token within 200ms. The payment service is idempotent. The API never returns partial results. Invariants that no agent is allowed to violate, regardless of what work it's doing.
Module boundaries. What each component owns, what it exposes, what it depends on. When Agent A refactors the auth module, it knows which interfaces are stable because the declaration says so. When Agent B builds against it, it knows which interfaces it can rely on.
Constraints. The non-negotiable requirements that cut across the entire system -- compliance, performance budgets, security policies. These are not features to be built but constraints to be honored. Every agent needs to know them before it writes a line of code.
Relationships. The dependency graph that tells you, before anyone changes anything, what will break if something moves. When Agent C migrates the database schema, the identity layer tells every agent which modules depend on that schema and which contracts those modules guarantee.
Purpose. What the system is for, stated as a specific constraint rather than vague aspiration. The purpose determines what changes are in scope and what changes are drift.
This is the manifest. This is what the reconciliation loop runs against. Every agent reads it. Every PR is validated against it. When the identity needs to change, the change happens in the declaration first, with a version bump that every agent can observe. The declaration leads. The code follows.
What happens without it
We already know. The distributed systems community documented it exhaustively.
Without consensus, agents cannot distinguish between an intentional architectural decision and an accidental artifact of another agent's work. Was that interface change deliberate, or did the other agent just need a different signature? Without a declared identity, there is no way to tell. So agents guess. And guessing is how drift starts.
Without a shared log, you get eventual inconsistency. Each agent's local changes accumulate small deviations from the intended system state. Individually, each deviation is trivial. Collectively, they compound into a system that no one designed and no one understands. This is technical debt at machine speed.
Without a leader, you get split-brain. Two agents make conflicting decisions about the same module, each believing it has authority. Both changes merge. The system contradicts itself. A human discovers this days later, in production.
Every one of these failure modes has a known mitigation. The mitigation is always the same: a shared, authoritative source of truth that all participants defer to.
The convergence
The pieces are converging, but they are converging around a hole.
GitHub is building the orchestration layer. Atlassian is building the project context layer. Factory and Cursor are building the execution layer.
What none of them have built is the identity layer. The declarative specification of what the software IS that sits between organizational intent and agent execution. The manifest that the reconciliation loop runs against.
This is not a gap in tooling. It is a gap in architecture. You can orchestrate a fleet. You can connect agents to project context. You can make agents faster and more capable. But without a shared identity, every improvement in agent capability is also an improvement in the system's ability to drift. Faster agents drift faster. More capable agents drift more creatively. The fleet scales, and so does the incoherence.
The identity layer is the consensus protocol for multi-agent development. The ArgoCD manifest for your codebase. The Raft log for your fleet of coding agents. The thing that makes the answer to "what is this system?" the same for every agent, every human, and every validation step, at every point in time.
One truth. Many agents. Zero drift.
The industry is building everything around it. The center is still missing.