
You have an identity layer. You have declared what your software is -- its constraints, its contracts, its compliance obligations. The reconciliation engine has compared those declarations against the actual codebase. The result is a list of divergences, places where the code doesn't match the identity. Some are single-file fixes. Some are multi-service refactors. Some carry regulatory deadlines. Some carry only aesthetic preferences.
The list is longer than you expected. It always is.
The natural question: what do I fix first? Handled poorly, this produces a backlog that looks like every other backlog, triaged by whoever shouts loudest. Handled well, it becomes a planning discipline that compounds over time.
Risk has a price tag. Use it.
Not all diffs are created equal. A payment service that violates its declared SLO has a different cost profile than an admin dashboard with inconsistent error handling. The first generates customer-facing incidents. The second generates engineer complaints.
Engineering teams default to fixing what they understand, not what matters most. Risk-weighted prioritization means attaching cost estimates to the consequences of inaction, not the effort of action. What happens if this diff stays open for six months? If the answer is "a compliance deadline passes," that is a quantifiable exposure. If the answer is "the code is ugly," that is a preference.
The EU AI Act's high-risk system requirements take effect August 2, 2026. Non-compliance penalties reach EUR 15 million or 3% of global annual turnover -- whichever is higher. For prohibited practices, penalties escalate to EUR 35 million or 7% of turnover, exceeding even GDPR's ceiling. GDPR enforcement itself has crossed EUR 7.1 billion in cumulative fines, with regulators increasingly penalizing structural control deficiencies (weak vendor management, missing encryption, inadequate logging) rather than waiting for a breach.
These are not theoretical numbers. They are the cost of leaving a compliance diff open past a deadline. When the identity layer flags that your ML pipeline lacks the audit trail required by the AI Act, that diff has a deadline and a penalty attached. It goes to the top of the list. No debate.
Customer-facing first, internal second
After regulatory risk, the next filter is blast radius. Diffs on critical-path services get reconciled before diffs on internal tooling.
This sounds obvious. In practice, teams gravitate toward fixing internal tools because the owner and the fixer are the same person. The context switch is minimal. The PR is merged by lunch. Meanwhile, a payment service diff requiring coordination across three teams sits in a backlog because nobody wants to schedule the meeting.
The identity layer makes this visible. Every service has declared relationships: what depends on it, what it depends on, what contracts it exposes. A diff on a service with forty downstream consumers is structurally more important than a diff on a service with two. Rank by consumer count, weighted by consumer criticality. Triage, not politics.
Estimate the cost before you commit
Some diffs are cheap. A missing log statement. A configuration flag that needs toggling. A constraint annotation that was declared but not enforced. An agent reads the constraint, reads the code, generates the fix, and verifies it. Maybe 50K tokens round-trip, done in minutes.
Some diffs are expensive. A service that declared encryption-at-rest for PII but stores three data types in plaintext across two databases. The agent has to trace every data path, generate schema migrations, write backfill scripts, integrate key management, and verify downstream contracts. Millions of tokens across multiple agent sessions, potentially spanning days.
The identity layer can estimate reconciliation cost before you commit tokens, because it knows the scope: which files diverge, which contracts are involved, which downstream services need verification after the change.
The ratio of risk reduction to reconciliation cost is the number that matters. A cheap diff that closes a high-risk gap is the obvious first move. An expensive diff that closes a low-risk gap can wait. Teams that skip cost estimation end up starting expensive reconciliations they cannot finish, or cherry-picking cheap ones that don't move the risk needle. Either way, exposure stays constant.
Dependency ordering: what blocks what
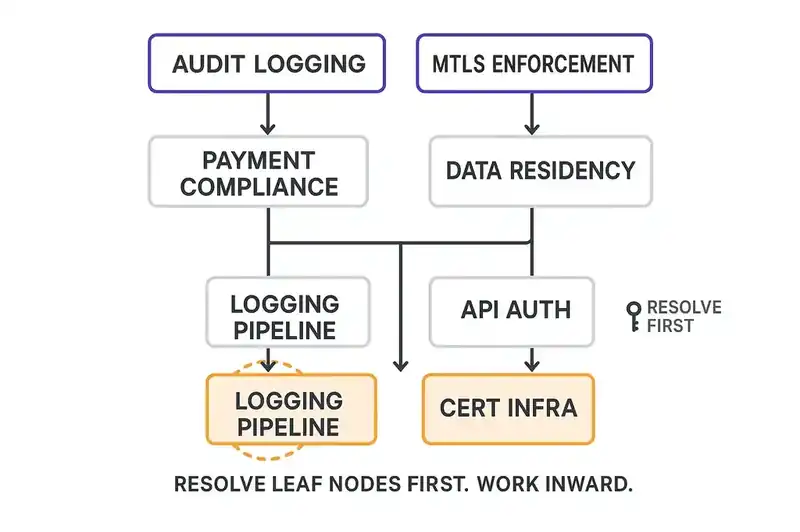
Some diffs cannot be resolved independently. You cannot add structured audit logging to a service that does not have logging infrastructure. You cannot enforce mTLS between services that have not provisioned certificates. You cannot validate data residency constraints on a service that has not implemented region-aware routing.
The identity layer's system relationships encode these dependencies. Service A declares a contract that requires capability X. Capability X depends on infrastructure component Y. If component Y has its own diff, that diff blocks A's reconciliation. This is a topological sort, and the identity layer has the graph.
Without dependency ordering, you get the most common waste pattern in reconciliation: an engineer spends three days adding audit logging, discovers the logging pipeline cannot handle the required throughput, files a ticket for the platform team, and the work sits half-merged for two sprints. That dependency was knowable in advance. Build a dependency graph before you schedule anything. Resolve leaf nodes first. Work inward.
The compounding effect
Some diffs are force multipliers. Closing them makes every subsequent reconciliation cheaper.
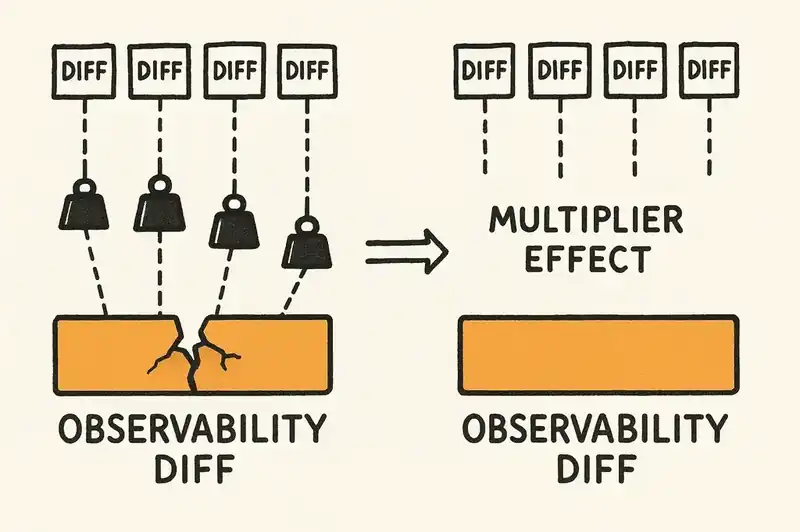
Consider a service mesh that lacks consistent observability. Every reconciliation on every service in that mesh requires manual verification because there is no automated way to confirm behavioral correctness post-change. If the identity layer declares that all services must emit structured traces, and the tracing infrastructure diff is open, then every other diff inherits additional verification cost.
That observability diff might not be the highest-risk item on the list. But it's a multiplier. Leaving it open taxes all future work.
A systematic literature review on technical debt prioritization explores this pattern: coupling and dependency analysis are consistent factors in predicting which debt items, when resolved, reduce the total cost of future remediation. The metric is not "what is the risk of this diff" but "what is the cumulative cost of every diff that gets harder while this one stays open."
Token budgets as a planning tool
In a reconciliation system, token spend maps directly to convergence velocity. A simple constraint enforcement might cost 50K tokens. A multi-service compliance remediation might cost 10 million. The identity layer can estimate these costs before execution, because it knows the shape of the divergence: how many files, how many services, how many contracts are affected.
You have a weekly token budget. You have a ranked list of identity-to-code divergences with estimated costs and risk scores. Allocation becomes arithmetic: fill the budget starting from the highest risk-to-cost ratio, respecting dependency ordering, and reserve a percentage for structural multipliers.
The difference from sprint-based planning is the feedback loop. A sprint takes two weeks. A reconciliation cycle takes hours. You re-prioritize daily based on what actually happened, not what you estimated two weeks ago. Diffs that turned out cheaper than expected free up budget for the next item. The mechanics are the same as engineering time allocation. The cycle time is compressed by an order of magnitude.
The system learns
Over time, the reconciliation engine accumulates history. Which types of identity mutations are expensive? Which services consistently take the longest to reconcile? Which constraint categories generate the most downstream breakage?
"Every time we add a data residency constraint, these three services take the longest to reconcile." That's not a complaint. It's an infrastructure investment signal. Those services have a structural problem (a missing abstraction, a hardcoded assumption) and the reconciliation cost data tells you exactly where to invest.
This is the difference between a backlog and a system. A backlog is a list you process. A system is a feedback loop that improves its own efficiency over time.
The prioritization matrix
Here's the framework, condensed for Monday morning.
Axis 1: Risk of inaction. What happens if this diff stays open? Regulatory penalty, customer-facing incident, internal friction, or cosmetic inconsistency. Score it.
Axis 2: Cost of reconciliation. How many tokens, how many dependencies, how much verification? The identity layer estimates this. Use the estimate.
Quadrant 1 -- High risk, low cost: Do now. A compliance gap that requires a configuration change. A security constraint that needs a single enforcement point. These are the highest-ROI items in your backlog. There is no reason to defer them.
Quadrant 2 -- High risk, high cost: Plan and schedule. A data residency violation that requires schema migration across three services. A missing audit trail that requires new infrastructure. These need dedicated time, dependency resolution, and possibly a phased approach. Start the dependency chain immediately even if the full reconciliation takes weeks.
Quadrant 3 -- Low risk, low cost: Batch and automate. Inconsistent error messages. Missing log fields. Style violations in generated code. Let the agent handle these in bulk during low-priority cycles. They are not urgent, but they are cheap, and closing them reduces noise in the diff list.
Quadrant 4 -- Low risk, high cost: Defer with review. An architectural preference that would require refactoring four services. An internal API that does not match its declared contract but has no external consumers. These go to the bottom of the list with a scheduled review date. If risk changes (a new consumer appears, a regulation shifts), they move up.
Override: Structural multipliers. Any diff that makes other diffs cheaper gets promoted one quadrant. A low-risk, high-cost infrastructure improvement that unblocks ten other reconciliations is not a Quadrant 4 item. It is a Quadrant 2 item, because its effective cost includes the savings it creates.
Putting it into practice
Start with three steps:
Step 1: Tag every open diff with a risk category and a cost estimate. The identity layer provides the cost estimate. Risk categories come from your compliance calendar, your SLO definitions, and your dependency graph. An afternoon for most teams; the identity layer automates most of it.
Step 2: Build the dependency graph. Which diffs block which? Which infrastructure gaps are multipliers? Sort topologically. This is mechanical -- the identity layer's system relationships give you the edges.
Step 3: Fill the first week's token budget. Start with Quadrant 1 items. Add dependency prerequisites for Quadrant 2 items. Batch Quadrant 3 items into automated runs. Review Quadrant 4 items monthly.
Then run the cycle. Reconcile, measure actual costs against estimates, update the model, re-prioritize. The estimates get better each time. The structural multipliers get resolved. The total cost of reconciliation drops.
The delta between your declared identity and your actual implementation is not a problem to solve once. It is a surface to manage continuously. The teams that manage it well will not be the ones with the smallest delta. They will be the ones with the best system for deciding what to close next.