
The strongest technical objection to identity engineering goes like this: you can't formally verify that code satisfies a natural-language constraint. Semantic equivalence between a specification written in English and an implementation written in Python is undecidable. Rice's theorem says so. Any system that claims to reconcile code against intent is, at best, a heuristic. At worst, it's theater.
The objection is correct on the theory. It also completely misses the point.
The formal limitation is real
Rice's theorem says that any non-trivial semantic property of a program is undecidable. You cannot write a program that takes arbitrary code and a specification as input and determines, for all cases, whether the code satisfies the specification. This isn't a tooling gap. It's a mathematical boundary, proven in 1953, as fundamental as the halting problem Turing established in 1936.
If you have a natural-language constraint ("all API endpoints must log access events before returning a response") and you want to prove that a given codebase satisfies it in every possible execution path, you are asking for something that is formally impossible in the general case.
SMT solvers like Z3 can verify bounded properties of bounded programs. They work well on narrow domains: cryptographic primitives, protocol state machines, hardware circuits. They struggle with quantifiers, nonlinear arithmetic, and deeply nested data structures. As program complexity grows, the search space grows exponentially. Microsoft Research's own documentation acknowledges that minor syntactic changes to a formula can shift solving time from seconds to hours. Formal verification works beautifully where it works. That is a vanishingly small fraction of real-world application code.
If your standard for reconciliation is formal proof, you will never reconcile anything at the application layer. The math forbids it.
The standard nobody actually holds
Nobody holds this standard for anything else in software engineering.
Code review is probabilistic. A human reviewer reads a diff, holds some mental model of the system, and makes a judgment call about whether the change is correct. They miss things. Studies show that code review catches somewhere between 20% and 60% of defects, depending on the codebase, the reviewer, and the phase of the moon. We don't reject code review because it's not formal verification. We accept it because it's better than no review.
Linting is heuristic. ESLint doesn't prove your JavaScript is correct. It pattern-matches against known anti-patterns and flags probable issues. It has false positives. It has blind spots. Nobody argues that linting is pointless because it can't prove correctness.
Test suites are incomplete. Dijkstra told us in 1970 that testing can show the presence of bugs but never their absence. Every test suite is a finite sample from an infinite input space. We don't reject testing because it can't cover every path. We accept it because catching some bugs is better than catching none.
Type systems are approximations. TypeScript's type system is unsound by design; it has known escape hatches that allow type errors at runtime. Haskell's is more rigorous, but even Haskell programmers reach for unsafePerformIO when the type system gets in the way.
Every quality mechanism in professional software development is probabilistic. Every single one. The formal-verification objection applies a standard to reconciliation that we don't apply to any other practice we rely on daily. If you're going to reject LLM-based reconciliation because it's not a proof, you also need to fire your code reviewers, delete your linters, and throw away your test suites. They aren't proofs either.
What LLM-based reconciliation actually does
An LLM reading code against a constraint is not attempting to prove a theorem. It's doing something closer to what a senior engineer does during code review: reading code with intent.
Consider a concrete constraint: "All HTTP endpoints in the payments service must validate the caller's authentication token before processing the request." An LLM can read the source code of a payments endpoint and determine, with high accuracy, whether that endpoint checks for an auth token. It's parsing the code. It's understanding the control flow. It's matching the semantic content of the code against the semantic content of the constraint.
This is pattern matching at the semantic level. Not syntactic grep. Not regex against import statements. The LLM reads what the code does and checks it against what the constraint says it should do.
Recent benchmarks bear this out. On code generation tasks, leading models score above 80% on benchmarks like LiveCodeBench. An empirical evaluation of LLM-assisted compliance checking found 81% accuracy on generating correct compliance requirements from regulatory text. Meta's Automated Compliance Hardening system combines LLMs with test generation to catch policy violations that traditional static analysis misses entirely.
Is 81% perfect? No. Is it useful? Ask yourself: if you had a tool that caught 81% of compliance violations automatically, on every commit, before any human looked at the code -- would you turn it off because it wasn't 100%?
The anatomy of failure
Probabilistic reconciliation fails in specific ways that are worth understanding.
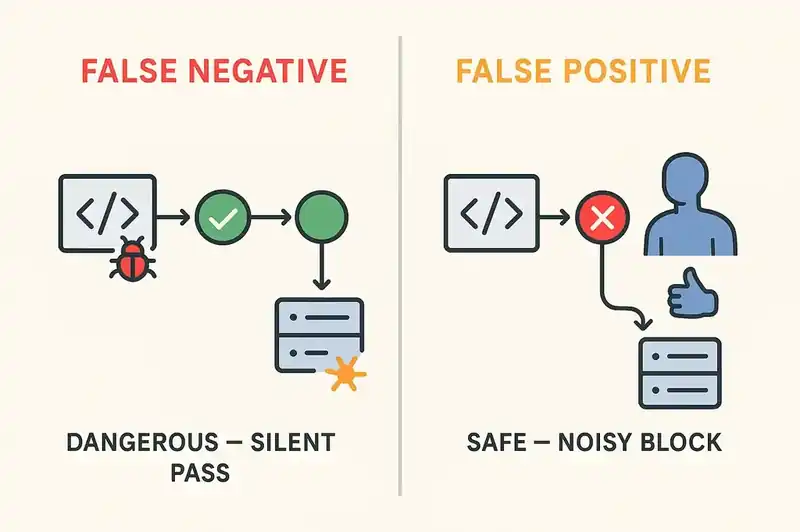
False negatives (the system says the code complies when it doesn't) are the dangerous failure mode. They look like passing builds that silently violate constraints. A payment endpoint that technically has auth middleware registered in a routing table three files away, but the LLM doesn't trace the indirection and reports it as compliant when the middleware is actually misconfigured. This happens.
False positives (the system flags compliant code as non-compliant) are annoying but safe. They look like a CI check that blocks a merge until a human reviews it. The developer looks at the flag, confirms the code is fine, overrides the check, and moves on. Same workflow as flaky tests and overzealous lint rules.
Both failure modes are manageable, and the system improves over time. Every false positive that a human overrides is a training signal. Every false negative caught in production is a constraint that gets refined. The feedback loop tightens. This is how every quality tool works: not by being perfect on day one, but by being useful enough to survive and good enough to improve.
The 80% argument
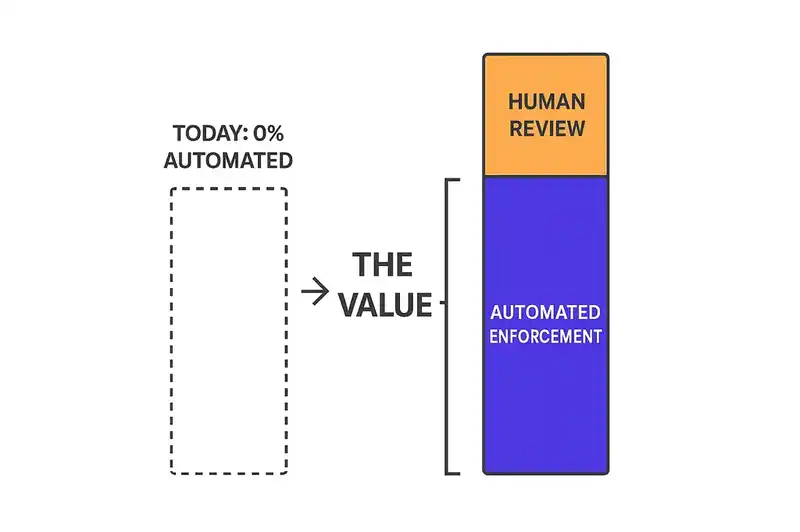
The number that matters is the delta between probabilistic reconciliation and no reconciliation.
In most engineering organizations right now, the number of architectural constraints that are automatically validated on every commit is zero. The authentication requirement lives in a wiki page. The logging standard lives in an onboarding doc. The data residency constraint lives in a Slack thread from 2023. None of them are checked. None of them block a build. They're enforced by human memory and code review, which catches somewhere between 20% and 60% of issues when reviewers are paying attention. They frequently aren't, because they're reviewing 30 PRs a day.
If LLM-based reconciliation catches 80% of constraint violations, that's not 80% of a theoretical maximum. That's an improvement from 0% automated enforcement to 80% automated enforcement. The gap between 0% and 80% is where the value lives. The gap between 80% and 100% is what human review is for.
This is the same argument that justified every quality tool in the history of software. Unit testing didn't replace QA engineers. It caught the obvious bugs so QA could focus on the subtle ones. Linting didn't replace code review. It caught the formatting and pattern issues so reviewers could focus on logic and design. Probabilistic reconciliation doesn't replace human judgment. It catches structural drift so humans can focus on the architectural decisions that actually require judgment.
Infrastructure already proves this works
We already rely on probabilistic reconciliation at scale. We just don't call it that.
Terraform compares declared state to actual state and computes a plan to converge them. It is not formally verified. It has known failure modes. State files go stale when someone modifies infrastructure out of band. Provider plugins have bugs that cause incorrect diffs. Complex resources with dynamic attributes produce plans that don't match the applied result. The kubernetes_manifest resource, to pick one notorious example, fails with "Provider produced inconsistent result after apply" when managing CRDs with flexible schema fields. This affects Istio, cert-manager, KubeVirt, and Karpenter resources.
Kubernetes itself is a reconciliation engine, and it drifts constantly. Controllers, operators, admission webhooks, and the scheduler all mutate resources. Autoscalers change replica counts. Network policies get updated by service meshes. The system is designed around the assumption that drift will happen and that continuous reconciliation -- not one-time correctness proofs -- is the mechanism for convergence.
Nobody rejects Terraform because its state file can go stale. Nobody rejects Kubernetes because controllers create drift that the reconciliation loop has to clean up. These tools work because they're dramatically better than SSH-ing into servers and making changes by hand, or configuration spreadsheets, or manual checklists.
The alternative to LLM-based reconciliation of software constraints is also nothing. That's the bar.
The actual choice
The formal-verification objection is a category error. It evaluates reconciliation against a standard that nothing in software engineering meets, and uses the gap to argue for inaction. The choice was never between probabilistic reconciliation and formal proof. The choice is between probabilistic reconciliation and the current state, which is no reconciliation at all.
Rice's theorem tells us that perfect, general-purpose semantic verification is impossible. It does not tell us that imperfect, domain-specific semantic checking is useless. The distance between "impossible in the general case" and "useless in practice" is vast. The entire field of software quality lives in that distance.
Reconciliation is probabilistic. So is code review. So is testing. So is linting. Every mechanism we use to maintain software quality operates under uncertainty, makes mistakes, and improves over time. The question was never "is it perfect?" It was "is it better than what we have?"
What we have is nothing. So yes.