
The full system rewrite is back. Not as an act of desperation, but as a routine operation.
Google studied 39 code migrations over twelve months and reported that developers perceived a 50% reduction in total migration time, with 69% of all code edits generated by LLMs. Airbnb had an Enzyme-to-React-Testing-Library migration estimated at 1.5 years. An LLM-powered pipeline completed 75% of the 3,500 files in four hours. The full migration took six weeks. These are production results at Google and Airbnb, not pilot programs.
The economics have shifted. Migrations that consumed quarters now consume sprints. Rewrites that required dedicated teams now require dedicated prompts. The cost of changing code has dropped so fast that the question is no longer whether to rewrite, but what to preserve when you do.
And that question is where most rewrites still die.
The graveyard of rewrites
The Standish Group's CHAOS reports have tracked IT project outcomes for decades. The consistent finding: more than 70% of large projects fail to meet their targets on time, on budget, and with satisfactory results. Large projects fail at even higher rates -- the 2015 report put the failure rate for large projects at 94%. Rewrites, which are large projects by definition, sit squarely in the blast radius.
The usual explanations are organizational: scope creep, political infighting, insufficient resources, bad estimates. These are real, but they obscure a more technical failure mode that explains why rewrites specifically go wrong.
Rewrites fail because they lose behavioral correctness during transition. The implicit contracts that the old system honored (the edge cases, the silent assumptions, the undocumented guarantees that users and downstream systems depend on) get dropped somewhere between the old implementation and the new one. Nobody notices immediately. The new system passes its tests, because the tests were written against the new specification, not the old behavior. Then production traffic hits, and the delta between what the old system actually did and what the new system thinks it should do starts generating incidents.
This is the pattern. It repeats with remarkable consistency.
What Twitter learned by not dying
In 2009, Twitter's backend ran on Ruby on Rails. It handled 200-300 requests per second per host. By 2014, the team had migrated the critical path to Scala and Java on the JVM. Throughput jumped to 10,000-20,000 requests per second per host. The Ruby code that powered every tweet, every follow, every direct message was gone.
The migration succeeded, but not because the Scala code was better than the Ruby code (though it was faster). It succeeded because the team understood what Twitter was before they rewrote it. The behavioral contracts (real-time message delivery, eventual consistency of the social graph, the specific semantics of retweets and replies and threading) survived the transition intact. Users didn't notice because the identity of the system persisted even as the implementation changed completely.
Twitter's engineering team could have produced a Scala system that was architecturally clean, performant, and wrong. Wrong in the sense that it violated contracts the Ruby system had been silently honoring for years. That they didn't tells us something important: the actual work of a rewrite is not writing new code. It's understanding what the old code does, all of it, including the parts nobody documented.
The monolith tax
Airbnb's Ruby on Rails monolith, affectionately called Monorail, was a case study in why rewrites become necessary in the first place.
By 2015, over 200 engineers were committing to Monorail, pushing roughly 200 commits per day. The tight coupling meant that an average of 15 hours per week were lost to blocked deployments caused by reverts and rollbacks. One engineer's change could break another engineer's feature in ways that weren't visible until production. The monolith wasn't just slow to run; it was slow to change. And in a company growing as fast as Airbnb, slow to change meant slow to survive.
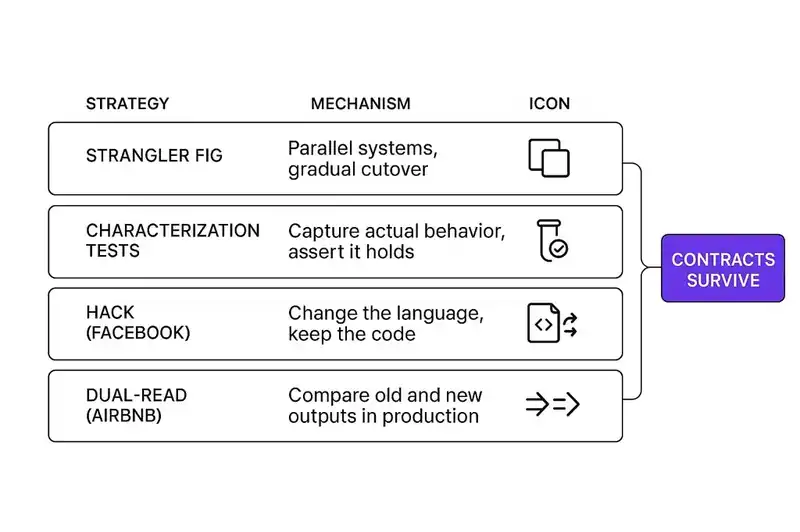
The migration to a service-oriented architecture on AWS took years. It involved a hybrid phase where Monorail coexisted with the new services, handling routing and the view layer while forwarding API traffic to new services responsible for business logic and data access. For reads, they ran dual paths -- the old Monorail path and the new service path simultaneously -- comparing responses to verify behavioral equivalence before cutting over.
That dual-read strategy is worth pausing on. Airbnb didn't trust the new system to be correct. They verified it against the old system's actual behavior, not against a specification document, because no specification document existed. The old system's behavior was the specification. The migration succeeded because they treated the running system as the source of truth and validated the new implementation against it.
Then, years later, when Airbnb needed to migrate 3,500 test files from Enzyme to React Testing Library, they used LLMs to compress an estimated 1.5 years of work into six weeks. The test migration moved fast because the behavioral contracts were already externalized in the tests themselves. The LLM had something to work against. That's the difference between a migration that succeeds and one that doesn't: not speed, but clarity about what the system is supposed to do.
Half-life
Uber operates roughly 4,500 stateless microservices, deployed over 100,000 times per week by 4,000 engineers. The measured half-life of an Uber microservice is 1.5 years. Every 18 months, half the codebase is replaced.
Uber's engineering leadership coined a term for the operational consequence: "migration hell." Ever-changing microservices constantly require upstream migrations. Service A depends on Service B. Service B gets rewritten. Service A has to adapt. Multiply that by 4,500 services and you get a system in permanent transition.
This isn't a failure of architecture. It's Lehman's Law of Continuing Change in action: a system used in the real world must be continuously adapted, or it becomes progressively less satisfactory. Uber's half-life isn't a bug. It's the natural consequence of a system adapting as fast as Uber's business requires. The problem isn't that services are being rewritten. The problem is that every rewrite risks losing the behavioral contracts other services depend on.
Gateways help. Uber adopted API gateways that decouple upstream consumers from downstream service implementations, so a service can be rewritten without forcing every consumer to migrate. But gateways only protect the explicit contracts (the API shapes, the request-response patterns). The implicit contracts, like timing assumptions, error handling semantics, and behavioral quirks that downstream services have learned to depend on, still get lost in translation.
The strangler and the scalpel
The software industry has known about this problem for decades. We've developed strategies for it, and they all circle the same idea.
Martin Fowler named the strangler fig pattern in 2004, inspired by the strangler figs he saw in Queensland's rainforests. The pattern: instead of replacing a legacy system all at once, you grow a new system around it. A facade intercepts requests and routes them to either the old system or the new one. Over time, the new system handles more and more traffic until the old system can be removed entirely. The host tree dies, and the strangler fig stands on its own.
The pattern works because it preserves behavioral correctness during transition. At every point in the migration, the system's external behavior is unchanged. Consumers don't know whether their request was handled by old code or new code. The contracts hold.
Michael Feathers, in Working Effectively with Legacy Code (2004), introduced characterization tests -- tests that you write not to verify intended behavior, but to capture actual behavior. You run the existing system, observe what it does for a given set of inputs, and write a test that asserts that output. The test doesn't tell you whether the behavior is correct. It tells you whether the behavior changed. When you're rewriting a system, that's often more valuable than knowing whether the behavior was right in the first place. You need to know what users depend on, not what the original developer intended.
Characterization tests are a recognition that in any sufficiently complex system, the specification is the running code. Not the documentation, not the design documents, not the ticket that prompted the feature. The code itself, in all its messy, undocumented, accidentally correct glory, is the authoritative statement of what the software does.
The choice Facebook refused to make
Facebook's response to the rewrite question is instructive precisely because they didn't rewrite.
By the early 2010s, Facebook's PHP codebase was enormous and PHP's limitations were real. The language lacked static typing, had inconsistent standard library naming, and was ill-suited for the scale Facebook operated at. The obvious move was to rewrite in a "better" language. Java. Python. Something.
Instead, Facebook created Hack, a new language derived from PHP that interoperated with existing PHP code. Hack added gradual static typing, generics, async/await, and modern collections. But the critical feature was compatibility. PHP and Hack code could coexist in the same project. Engineers could migrate file by file, function by function, at their own pace.
Facebook chose this path because they understood that the cost of a rewrite wasn't the new code. It was the risk of losing what the old code knew. Billions of lines of PHP encoded years of behavioral contracts -- business rules, edge cases, platform-specific workarounds, performance optimizations. Rewriting in a different language would have required re-deriving all of that knowledge from scratch. Hack let them keep the knowledge and fix the language around it.
This might be the smartest response to the rewrite question anyone has tried. Don't rewrite the code. Rewrite the substrate. Let the behavioral contracts survive intact while upgrading the medium they're expressed in.
Not every organization can create a new programming language. But the principle applies at every scale: the goal of a migration is not new code. The goal is the same behavior in a better medium.
Software DNA and the rewrite problem
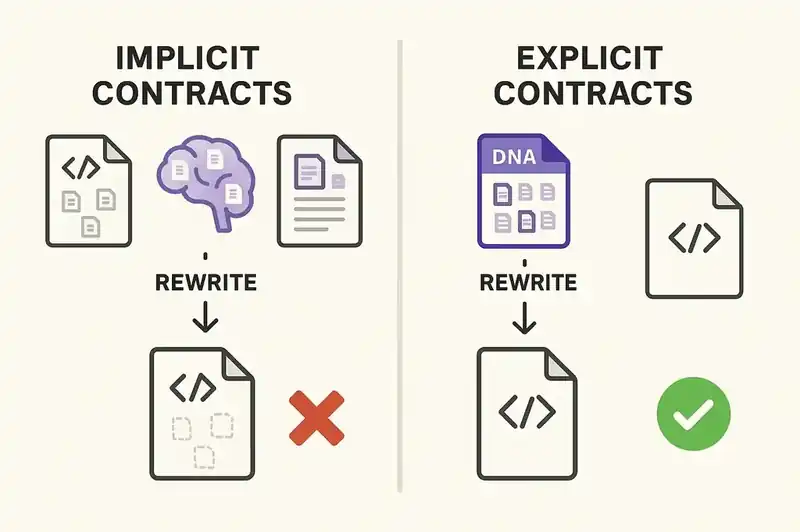
The reason rewrites fail is structural, not tactical. The behavioral contracts that define what a system actually does aren't externalized. They live in the code, in the tests (if tests exist), in the heads of senior engineers, and in the muscle memory of operations teams. When you rewrite, you have to somehow transfer all of that implicit knowledge into the new implementation. The transfer is lossy by default.
Every successful rewrite strategy discussed above is a technique for reducing that loss.
The strangler fig pattern preserves contracts by running old and new systems in parallel. Characterization tests capture contracts by observing actual behavior. Facebook's Hack preserved contracts by keeping the existing code and changing the language around it. Airbnb's dual-read validation preserved contracts by comparing old and new outputs in production. Google's LLM-assisted migrations preserved contracts by automating the mechanical translation while keeping human review for semantic correctness.
Each of these is a different angle on the same problem: the behavioral identity of the software is trapped inside the implementation, and extracting it is the hard part of any migration.
What if it weren't trapped?
If the behavioral contracts of a system were declared explicitly -- in a version-controlled, machine-readable form that existed independently of the code -- then a rewrite wouldn't require re-deriving the contracts from the implementation. The contracts would already be externalized. The new implementation could be validated against them directly. An AI agent generating the new code could read the contracts before writing anything, and a validation loop could verify compliance continuously.
This is what we mean by software DNA: a persistent identity layer that defines what a system is, what it guarantees, what it must honor, and how it relates to other systems. When that layer exists, a rewrite is a material change (new code implementing the same identity). When it doesn't exist, a rewrite is an identity crisis.
The AI rewrite loop
This is already happening, whether organizations are ready for it or not.
Google's study showed that LLMs can handle the mechanical work of code migration. The 69% of edits that were LLM-generated were largely routine transformations -- the kind of work that's tedious for humans and trivial for machines. The remaining 31% required human judgment. That split is telling. The mechanical transformation of code is becoming automated. The semantic validation of whether the transformation preserved the right behavior is still a human problem.
But it's a human problem that gets dramatically easier when the behavioral contracts are explicit.
Consider two scenarios. In the first, a team rewrites a payment service from Python to Go. The service's behavioral contracts are implicit, distributed across thousands of lines of Python, dozens of test files, a handful of Confluence pages that may or may not be current, and the institutional memory of three senior engineers. The rewrite takes six months. Half that time is spent understanding what the old system actually does. The other half is spent building the new system and discovering, in production, the contracts they missed.
In the second scenario, the same team rewrites the same service, but the service has a declared identity: purpose, behavioral contracts, constraints, system relationships. The LLM reads the identity declaration, generates the Go implementation, and a validation loop checks the new code against the declared contracts. Humans review the semantic correctness. The mechanical work is automated. The six-month rewrite takes six weeks, not because the code is written faster, but because the understanding is already externalized.
The gap between these scenarios is narrowing. Not because AI is getting smarter about inferring contracts (though it is). But because the cost of not externalizing contracts is rising in direct proportion to the speed at which code can be rewritten. When rewrites were rare and expensive, you could afford to keep the contracts implicit. When rewrites are routine, you can't.
The identity test for your next rewrite
If you're considering a rewrite -- or if one is being imposed on you by a framework deprecation, a language sunset, or a platform migration -- here's the diagnostic question:
Can you describe what your system does, what it guarantees, and what it must honor, without referencing the current implementation?
If the answer is yes, you're ready to rewrite. The implementation is the disposable part. The identity survives.
If the answer is no -- if the only way to understand the system's behavior is to read the code -- then you're not ready to rewrite. You're ready to characterize. Write the characterization tests. Document the contracts. Declare the boundaries. Do the work of externalizing the identity before you start the work of replacing the implementation.
This ordering matters. The organizations that rewrite first and discover contracts later pay for the discovery in production incidents. The organizations that characterize first and rewrite second pay for the discovery in preparation time. The second cost is always lower.
What changes, what persists
The pattern across every case study is the same, though the tactics differ.
Twitter rewrote Ruby to Scala and went from hundreds to tens of thousands of requests per second. Users didn't notice because the behavioral contracts survived. Airbnb decomposed Monorail into services and eliminated fifteen hours per week of blocked deployments while keeping the product behavior identical. Uber's microservices turn over every 18 months, with API gateways and service contracts protecting behavioral continuity across the churn. Facebook didn't even rewrite their code; they changed the language around it, the most conservative migration strategy possible. Google's LLM-assisted migrations automate the mechanical transformation while human reviewers validate behavioral correctness against the original.
In every case, the code turned out to be temporary. What survived was the behavioral identity: the contracts, the constraints, the guarantees.
AI is making rewrites cheap. That's the headline. The less obvious story is that cheap rewrites make behavioral identity more valuable, not less. When you can regenerate the code in hours, the code is obviously not the asset. The asset is the thing that tells you what to generate.
Right now, for most systems, the identity is as fragile as the code, because it was never separated from the code in the first place. The organizations that separate them will rewrite everything and lose nothing. The ones that don't will join the 70% that rewrite everything and lose the thread.
If you're navigating a migration and want to compare notes on preserving behavioral identity through the transition, we'd like to hear from you.