Software DNA is a declarative, machine-readable, version-controlled identity layer that defines what a piece of software is, what it should do, what constraints it must honor, and how it relates to other systems. It is the persistent specification that AI agents read before generating code, that CI/CD systems validate against, and that humans review to understand intent apart from implementation.
The industry has been building around this primitive for decades without actually building it.
The thing that doesn't exist
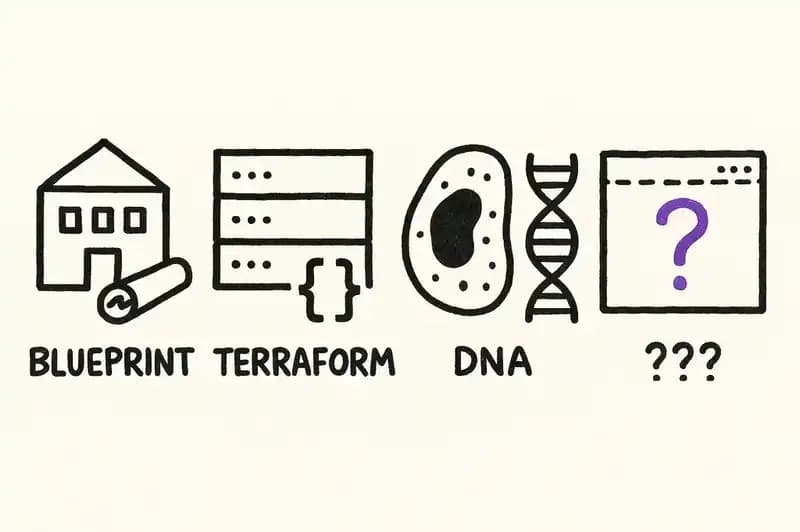
Every engineered system of consequence has a persistent identity layer except software.
Buildings have blueprints. They're filed with the city, versioned through revisions, and legally binding. You can demolish the building and reconstruct it from the blueprint. The blueprint survives the structure it describes.
Infrastructure has Terraform configurations. You declare what you want -- three EC2 instances, a load balancer, a VPC with these CIDR ranges -- and a reconciliation engine makes reality match the declaration. HashiCorp built a $6.4 billion company on this idea before IBM acquired them. The pattern works. It proved out at scale.
Organisms have DNA. A double helix that encodes what to build without specifying how to fold the resulting proteins. Cells are replaced constantly. The organism maintains its identity. The code persists across generations.
Software has none of this. Your production service has a README that was last updated in Q2 of last year, a Confluence page that three people can find, and a senior engineer who "just knows how the billing module works." That engineer is interviewing somewhere else right now.
This was always a liability. Now that 41% of committed code is AI-generated (GitClear, 2025 analysis of 211 million changed lines), it's a structural failure. The assumption that someone on the team understands the intent behind the implementation, the assumption every engineering practice was built on, is no longer reliably true.
What Software DNA is
Precision matters when you're naming a primitive, so here's the anatomy.
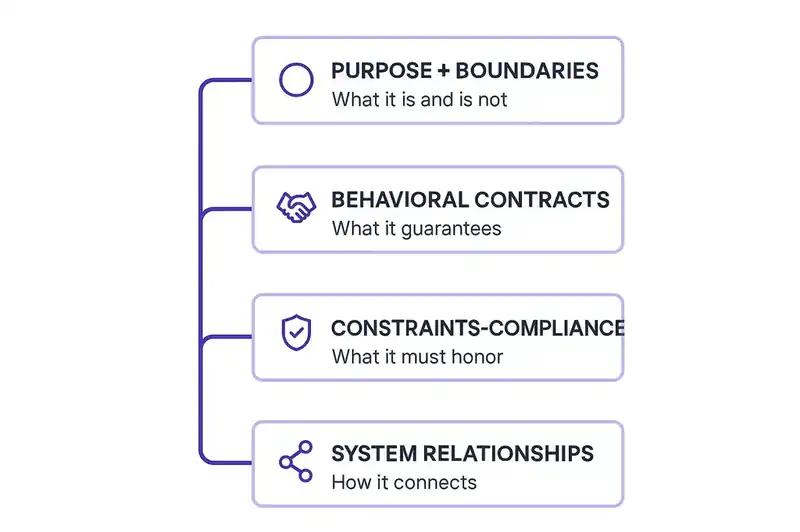
Software DNA has four components:
Purpose and boundaries. What the software is and what it is not. A payment service processes transactions. It does not manage user profiles, even if user data passes through it. Boundaries prevent scope creep at the identity level, before an agent or a developer adds "one small feature" that transforms a focused service into an everything-service. Purpose is the answer to "why does this exist?" that persists after every person who originally built it has left the company.
Behavioral contracts. What the software guarantees to its consumers. API shapes, response semantics, error handling commitments, performance SLOs. Not aspirational targets in a slide deck, but declared contracts that tooling can validate. When a behavioral contract changes, that change is visible, reviewable, and versioned independently from the code that implements it. A contract change is a decision. A code change is execution.
Constraints and compliance. What the software must honor regardless of what features are added. Security policies. Data residency requirements. Regulatory mandates. Architectural patterns the organization has adopted. The EU AI Act's high-risk enforcement hits August 2, 2026. Colorado's AI Act enforcement begins June 30, 2026. These aren't theoretical concerns. They're deadlines with penalties. A constraint declared in the identity layer is enforced continuously, across every feature and every agent-generated commit. A constraint documented in a wiki is enforced by luck.
System relationships. How the software connects to everything around it. Dependencies, consumers, data flows, ownership boundaries. Not a static architecture diagram that was accurate on the day it was drawn, but a living declaration that agents and tooling can query: what depends on this service? What breaks if this contract changes? Who owns the upstream?
What Software DNA is not
This distinction matters more than the definition. The industry is littered with artifacts that look similar and solve different problems.
It is not documentation. Documentation describes what exists. DNA declares what should exist. Documentation is written for humans to read after the fact. DNA is written for machines and humans to enforce before the fact. Documentation drifts because nothing enforces its accuracy. DNA drifts only if the reconciliation loop is broken, and you can detect that.
It is not a test suite. Tests verify that implementation behaves correctly. DNA specifies what "correctly" means. Tests are derived from identity. They are not the identity itself. Kent Beck didn't abandon TDD when he started working with AI agents. He turned TDD into a verification mechanism for a persistent plan file. The plan declares intent, the tests verify compliance. The tests serve the specification, not the other way around.
It is not an ADR. Architecture Decision Records capture the reasoning behind a decision at a point in time. They're historical artifacts. Useful, but static. DNA is the current, living declaration of what the software is right now. An ADR explains why you chose PostgreSQL over DynamoDB in 2023. DNA declares that this service uses PostgreSQL, that the data residency constraint requires EU-region storage, and that the query performance SLO is P99 under 50ms. The ADR is the history. The DNA is the present tense.
It is not a project management artifact. Tickets, epics, stories: these track work. DNA defines what the software is, independent of what work remains. A Jira ticket is consumed when the work is done. DNA persists after every ticket is closed.
It is not a spec file that gets written once and forgotten. This is the critical failure mode. Augment Code, a spec-driven development vendor, published a finding that should be tattooed on every PM's forearm: "Most spec-driven tools produce static documents that drift from implementation within hours." Hours. The specification-as-document approach fails because documents are inert. DNA must be active: continuously reconciled, not just initially authored.
The Kubernetes precedent
If you've operated Kubernetes, you already understand the conceptual model.
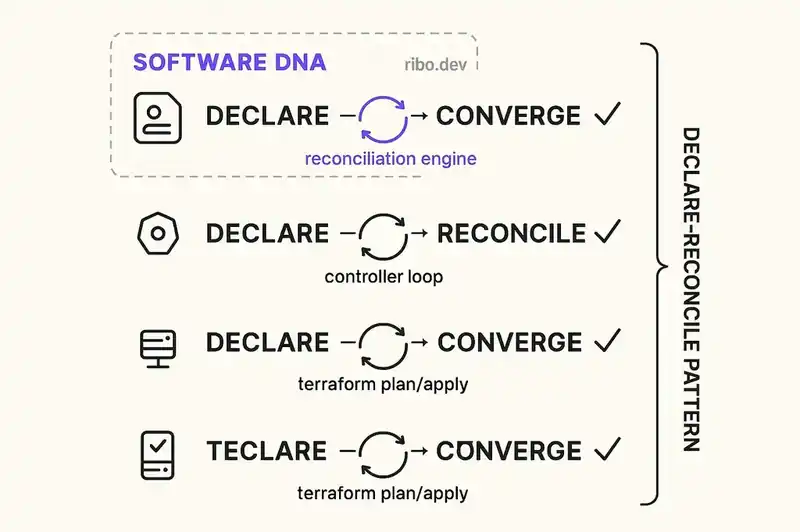
In Kubernetes, you write a YAML manifest that declares desired state: I want three replicas of this container, with these resource limits, behind this service. You apply the manifest. A reconciliation loop (the controller) continuously compares actual state to desired state. If a pod dies, the controller notices the delta and spins up a replacement. You don't script the recovery. You declare the desired state, and the system converges toward it.
This is the declare-reconcile pattern. It won for Kubernetes. It won for Terraform. It's the reason the entire GitOps movement exists. InfoQ described the emerging approach to specification-driven development in exactly these terms: "SDD introduces a declarative, contract-centric control plane" (InfoQ, 2025).
Now apply the same pattern to the software itself. Not the infrastructure it runs on, but the application, the service, the system.
Declare the identity: purpose, contracts, constraints, relationships. Let agents generate code that implements the identity. Let a reconciliation loop continuously detect the delta between declared identity and actual implementation. When drift is detected (a new endpoint that violates a behavioral contract, a dependency that breaks a constraint, generated code that exceeds a boundary) you flag it, correct it, or escalate it.
The conceptual leap is small. The infrastructure leap is not. But the pattern is proven: HashiCorp proved it for infrastructure, Kubernetes proved it for orchestration. The same pattern, applied to application identity, is Software DNA.
What a DNA declaration looks like
Conceptually (not proposing a syntax, proposing a structure):
identity PaymentService {
purpose {
"Process financial transactions between buyers
and merchants. Route payments to processors.
Maintain transaction audit trail."
boundaries {
excludes: [user-management, merchant-onboarding, reporting]
}
}
contracts {
api ProcessPayment {
guarantees {
idempotent: true
max_latency_p99: 200ms
error_semantics: "never silently drops a transaction"
}
}
event PaymentCompleted {
schema: "schemas/payment-completed-v3.json"
consumers: [ledger-service, notification-service, analytics]
breaking_change_policy: "requires consumer sign-off"
}
}
constraints {
compliance: [PCI-DSS-4.0, SOC2-TypeII]
data_residency: "process and store in originating region"
auth: "service-to-service mTLS, no user credentials in memory"
architecture: "no direct database access from external services"
}
relationships {
depends_on: [processor-gateway, currency-service]
consumed_by: [checkout-frontend, merchant-dashboard, ledger-service]
owned_by: "payments-team"
}
}
This is not code. It's not configuration. It's identity. Every field is something a human decided, not something an agent should invent. An AI agent reading this declaration before generating code for PaymentService knows what it can build, what it cannot build, what constraints apply, and which other systems it might affect.
An AI agent generating code without this declaration is guessing. It might guess well. It will eventually guess wrong. And when it does, the failure mode isn't a syntax error. It's an architectural violation that compounds silently until someone notices months later.
The convergence
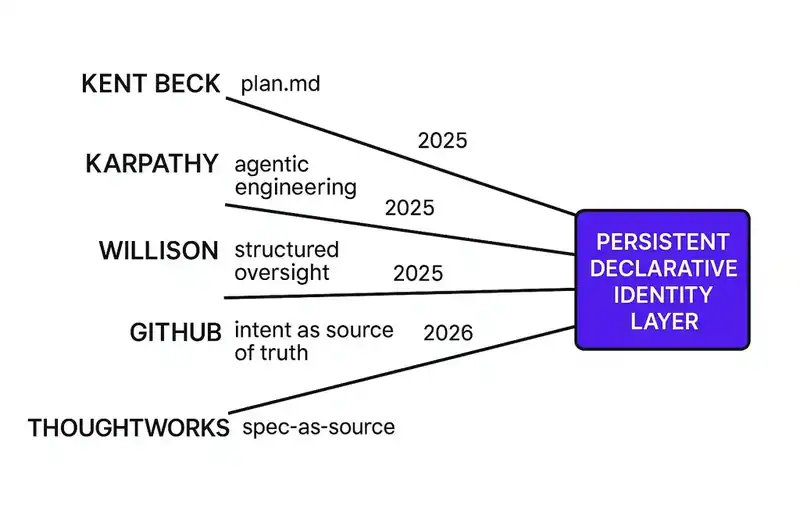
We didn't invent this idea. We named it. The idea was converging from at least five independent directions.
Kent Beck started governing AI agents through structured plan.md files. Define the tests. Declare the plan. Tell the agent to follow it step by step: "Always follow the instructions in plan.md." He turned TDD into an agent governance mechanism. Not because TDD is new, but because without persistent structured intent, agents are ungovernable. The plan file is a proto-DNA: a persistent declaration that constrains agent behavior.
Andrej Karpathy coined "vibe coding" in February 2025, then declared it "passe" twelve months later in favor of agentic engineering. The shift was from treating AI as a magic wand to treating AI agents as participants in a structured process. Humans architect, specify, and review. Agents execute. The specification is the interface between human intent and machine execution. That's DNA.
Simon Willison, co-creator of Django, published "Agentic Engineering Patterns" in February 2026 and identified November 2025 as the inflection point, the moment AI coding agents crossed from "mostly works" to "actually works." His core observation: the better agents get, the more you need structured oversight, not less. Capability without constraint is just faster drift.
GitHub made the subtext text. Den Delimarsky, Principal Product Manager, wrote: "We're moving from 'code is the source of truth' to 'intent is the source of truth.'" GitHub Spec Kit, their open-source specification toolkit, gathered roughly 40,000 stars. AWS shipped Kiro, an IDE built around a three-file spec workflow, reaching general availability in November 2025 with 250,000+ developers in preview.
ThoughtWorks Technology Radar, Volume 33 (November 2025) placed spec-driven development in the "Assess" ring. Martin Fowler's team, specifically Birgitta Bockeler, identified three maturity levels: spec-first (write a spec, then discard it), spec-anchored (keep the spec, edit it as the feature evolves), and spec-as-source (the spec is the primary artifact, humans never touch generated code). That third level, spec-as-source, is Software DNA with a different name and a narrower scope.
Different people, different vocabularies, same structural conclusion: AI agents need a persistent, declarative layer to work against.
What none of them built is the infrastructure to keep that layer alive: the reconciliation engine, the drift detection, the identity that persists even as the code is rewritten or regenerated entirely.
The security angle
There's a parallel thread in security research that most engineering leaders aren't tracking yet.
OWASP published its Top 10 for Agentic Applications in December 2025, the first formal taxonomy of AI agent risks. Goal hijacking. Tool misuse. Identity abuse. Memory poisoning. NIST published a concept paper on AI agent identity and authorization in February 2026. The term emerging from this research is "Intent Identity": continuous validation that an agent's actions align with its declared purpose.
That's Software DNA from the security side. If you can't declare what the software should do, you can't validate that an agent is doing it. Identity isn't just an engineering convenience. It's a security boundary.
Gartner projects that 80% of organizations will have dedicated platform engineering teams by end of 2026. Those teams need something to build platforms around. Right now it's CI/CD pipelines and infrastructure provisioning. The next layer is identity: a control plane for what the software is, not only where it runs.
Monday morning
If you're convinced, or even half-convinced, here's what to do this week.
Pick one service. Your most critical or your most misunderstood. Write down its purpose in three sentences. Write down what it explicitly does not do. Write down its behavioral contracts, what it guarantees to consumers. Write down its constraints. Write down what depends on it and what it depends on.
Put it in version control. Not in Confluence. Not in Notion. In the repository, next to the code. A file that gets reviewed in pull requests, versioned with commits, and diffed like any other change.
Tell your AI agents about it. If you're using Cursor, Copilot, Claude, or any agentic coding tool, put the identity declaration in the context. Instruct the agent to read it before generating code. You'll notice immediately when the agent tries to violate a boundary or ignore a constraint, because now you have something to notice against.
Review identity changes separately from code changes. When someone proposes a change to what the software is (not how it's implemented, but what it is) that's a different kind of review. It's a decision review, not a code review. Treat it accordingly.
This isn't tooling advice. It's a practice. You can do it with a markdown file and discipline. The tooling to automate it will mature. The practice is available now.
What's still unsolved
There are hard problems we're actively working through.
Granularity is an open question. Should DNA exist at the service level? The feature level? The organization level? All three? The answer is probably "all three with inheritance," but the abstraction boundaries aren't proven yet. Too coarse and the declaration is useless for governing agent behavior. Too fine and the maintenance burden recreates the problem it's solving.
Spec drift is the hard problem. Augment Code's observation that specs drift within hours applies to any declarative layer. The reconciliation loop has to be continuous and automated, not periodic and manual. That's an infrastructure problem, and the infrastructure is immature. Detecting drift between a natural-language identity declaration and a codebase is a genuinely difficult technical challenge, somewhere between static analysis and semantic understanding.
Interoperability doesn't exist. GitHub Spec Kit uses one format. Kiro uses another. Beck's plan files are ad hoc markdown. Fowler's framework describes maturity levels but not interchange formats. If Software DNA is going to be a primitive, something foundational that tools compose on top of, it needs to be interoperable. Standards are premature today. But the pressure toward standardization will build as the tooling proliferates.
Adoption is a culture problem, not a technology problem. Writing identity declarations requires thinking about what the software is before writing code. That is a discipline shift. In organizations where the culture is "just ship it," the identity layer will be treated as overhead — until the cost of not having it becomes undeniable. That cost is already accumulating. The 8x increase in duplicated code blocks, the doubled code churn since 2021, the 19% slowdown that feels like a 20% speedup. The bill is coming. Some teams will pay it proactively. Most will pay it reactively.
The primitive
The declare-reconcile pattern won for infrastructure (Terraform), for orchestration (Kubernetes), for configuration (GitOps). It has not yet been applied to the software itself, to the identity of what the software is and what it should do.
AI agents make this application urgent. When humans wrote all the code, identity could live in someone's head. When agents write 41% of the code and climbing, identity has to be externalized, formalized, and continuously enforced.
The industry's best thinkers are converging on this from different directions. The tooling ecosystem is forming. Regulators are forcing the question. And the economics are straightforward: the cost of maintaining software without persistent identity increases every quarter that AI-generated code compounds.
Software DNA is the primitive nobody built. It's the layer between human intent and machine execution, and it's what makes reconciliation possible and governance practical.
The remaining question is an infrastructure question: who builds the reconciliation engine, the drift detection, the continuous validation loop that keeps the identity layer alive and the software aligned to it.
If you're wrestling with the same problem — identity, drift, governance in an agentic world — we'd like to compare notes.