
Your agent just burned 55,000 tokens initializing. It loaded tool definitions for three MCP servers, injected system prompts, parsed JSON schemas for every available endpoint, and allocated context for enums, field descriptions, and parameter constraints. It hasn't read a single line of your code yet. It hasn't seen your prompt. Over a quarter of Claude's 200K context window is gone, and the meter is running.
This is the state of the art.
The context obsession
The prevailing theory in AI-assisted development goes like this: if the agent had more context, it would make better decisions. Bigger context windows. More files indexed. Retrieval-augmented everything. The assumption is that the limiting factor is information volume -- that the agent fails because it doesn't know enough, and the fix is to tell it more.
This theory has driven the entire architecture of AI coding tools for the past two years. Cursor indexes aggressively across your repo. Claude Code traverses the full project. Copilot reads open tabs, imports, and type definitions. MCP servers expose entire API surfaces as tool catalogs. RAG pipelines fetch documentation, commit history, issue trackers, and Slack threads.
The Model Context Protocol hit 97 million monthly SDK downloads in March 2026, up from 2 million at launch in November 2024 -- a 4,750% increase in 16 months. Thousands of active MCP servers span databases, CRMs, cloud providers, productivity tools, and developer infrastructure. OpenAI, Google, Microsoft, Anthropic, Cursor, and VS Code all ship native MCP support. The protocol won. The ecosystem is enormous.
And the ecosystem has a token problem.
The cost of knowing everything
Each MCP tool definition costs 550 to 1,400 tokens for its name, description, JSON schema, field descriptions, enums, and system instructions. Connect three services with 40 tools total and you're looking at 55,000 tokens of tool definitions sitting in the context window before the agent processes a single user message. One team reported three MCP servers consuming 143,000 of 200,000 available tokens -- 72% of the context window burned on tool definitions, leaving 57,000 tokens for the actual conversation, retrieved documents, reasoning, and response.
A simple task -- checking a repository's language breakdown -- consumed 1,365 tokens via CLI but 44,026 via MCP. A 32x difference, because 43 tool definitions got injected into every conversation whether the agent needed them or not.
Cursor enforces a hard cap of 40 MCP tools total, regardless of how many servers you connect. Past that limit, the agent can't even see the remaining tools. This isn't arbitrary conservatism. It's an engineering acknowledgment that tool definitions crowd out the context the agent actually needs to do its job.
The industry's response has been to optimize the pipe. Dynamic toolsets that load definitions on demand. Code execution patterns that process data locally and return summaries. Progressive disclosure that starts with 80 tokens of guidance instead of 55,000 tokens of schemas. These are real improvements. Speakeasy reported 96% input token reductions with dynamic toolsets. But they're optimizations within a flawed frame.
The frame says: give the agent access to everything, then figure out how to make "everything" fit.
The ETH Zurich finding
In February 2026, researchers at ETH Zurich published a study that should have reframed the entire conversation. The paper, "Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?", tested 138 repository instances across 5,694 pull requests using Claude Code with Sonnet-4.5, Codex with GPT-5.2 and GPT-5.1 mini, and Qwen Code with Qwen3-30B.
The headline finding: LLM-generated context files -- the AGENTS.md files that teams auto-generate to "help" their agents -- reduced task success rates by an average of 3% compared to providing no context file at all. On SWE-bench Lite, a 0.5% reduction. On the researchers' own AGENTbench, a 2% reduction.
That's not marginal improvement falling short. That's negative value. The context files made the agents worse.
And they made everything more expensive. LLM-generated files increased inference costs by 20% on SWE-bench Lite and 23% on AGENTbench, adding 2.45 and 3.92 extra steps per task respectively. On some configurations, cost increases hit 159%.
Human-written context files did better -- a 4% average improvement. But the gap between "carefully written by a developer who understands the codebase" and "auto-generated by the same model that will consume it" tells you something important about the nature of the problem.
When the researchers stripped all documentation from the repos -- READMEs, docs folders, markdown files -- and then tested with LLM-generated context files, those files suddenly improved performance by 2.7%. The auto-generated content wasn't useless. It was redundant. The agent could find all of it by reading the repo directly. Hand it the same information twice and you've added noise.
The core conclusion from the paper: "Context files tend to reduce task success rates compared to providing no repository context" while simultaneously increasing inference costs.
Why more context fails
Three mechanisms explain the degradation.
Token costs compound across turns. Context files aren't loaded once. They're injected into every API call in a multi-step agent workflow. An AGENTS.md file that adds 2,000 tokens to the system prompt adds 2,000 tokens to every step the agent takes. Over a 15-step task, that's 30,000 extra tokens of the same static instructions repeated verbatim, each time paying the same inference cost, each time consuming the same fraction of the attention budget.
Attention dilution is real. Language models have finite attention. The more tokens in the context window, the less weight any individual token receives during the self-attention computation. Critical information -- the specific function signature the agent needs, the error message it's debugging, the constraint it should honor -- competes for attention with 55,000 tokens of tool schemas and 2,000 tokens of generic coding guidelines. The model doesn't forget the important stuff in any literal sense. It just gives it less relative weight as the context fills up.
Irrelevant context creates false relevance. When you dump a comprehensive description of your project's architecture, testing philosophy, deployment pipeline, and coding conventions into every prompt, the model treats it all as potentially relevant to the current task. A request to fix a null pointer in a utility function arrives alongside instructions about your microservice boundaries, your preferred ORM patterns, and your stance on dependency injection. The model has no way to know which instructions matter for this specific task. So it hedges. It over-constrains. It second-guesses itself against rules that have nothing to do with the work at hand.
This is the haystack problem. Not that the needle isn't in there. It probably is. But the more hay you add, the harder the needle is to find -- and unlike a human, the model can't just skip the irrelevant parts. It processes everything.
Context vs. identity
The distinction that matters is simpler than you'd expect.
Context changes per request. It's the open file, the error message, the stack trace, the user's prompt, the relevant type definitions. Context is situational. It answers: what is the agent looking at right now?
Identity persists across sessions, tools, and team members. It's the architectural constraints, the module boundaries, the integration contracts, the quality standards, the evolution rules. Identity is structural. It answers: what is this software supposed to be?
The industry has been treating identity as a context problem. We stuff project identity into context files -- AGENTS.md, CLAUDE.md, .cursorrules -- and inject them into every request as if they were just another piece of situational information. But identity isn't situational. It doesn't change between prompts. It changes when someone makes a deliberate architectural decision.
We're paying query-level prices for schema-level work.
Think about how a database works. You define the schema once. It persists. Every query runs against the schema, but the schema isn't loaded fresh with every query. It's the structural foundation that the query engine already knows about. You don't attach a copy of your table definitions to every SELECT statement.
Now look at how AI coding agents work. Every request loads the full project identity from scratch. Every API call includes the same static instructions. Every turn in a multi-step task re-reads the same AGENTS.md file, re-processes the same conventions, re-parses the same architectural constraints. The schema gets re-transmitted with every query.
This is architecturally wrong. It confuses what should be durable, queryable state with what should be ephemeral, per-request input.
The fragmentation tax
The structural problem gets worse when you look at how identity is currently expressed.
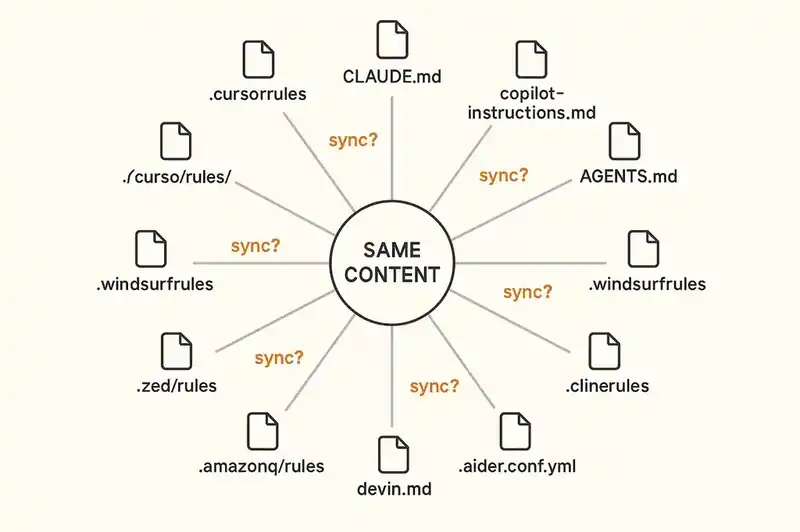
As of early 2026, we count at least a dozen incompatible formats for telling AI agents about your project:
.cursorrules(legacy) and.cursor/rules/*.mdc(current) for CursorCLAUDE.mdfor Claude Code.github/copilot-instructions.mdand.github/instructions/*.instructions.mdfor GitHub CopilotAGENTS.mdas the emerging cross-tool standardGEMINI.mdfor Gemini CLI.windsurf/rules/and legacy.windsurfrulesfor Windsurf.clinerules/for Cline.aider.conf.ymlfor Aiderdevin.mdfor Devin.amazonq/rulesfor Amazon Q.zed/rulesfor Zed
Same content. Different files. Different syntax. Different activation mechanisms. Cursor's .mdc format supports YAML frontmatter with activation modes -- Always, Auto Attached, Agent Requested, Manual -- that don't exist in AGENTS.md or CLAUDE.md. Copilot supports glob-based scoping that Cursor doesn't. None of them validate their contents. None of them enforce anything. They're suggestions in markdown, not contracts with teeth.
Tools like rule-porter and rulesync exist specifically to copy-paste instructions between formats. That these tools need to exist tells you everything about the state of the architecture. We don't have an identity layer. We have a content duplication problem with a dozen endpoints.
What a persistent identity layer looks like
Compare the static rules file approach with a queryable identity layer.
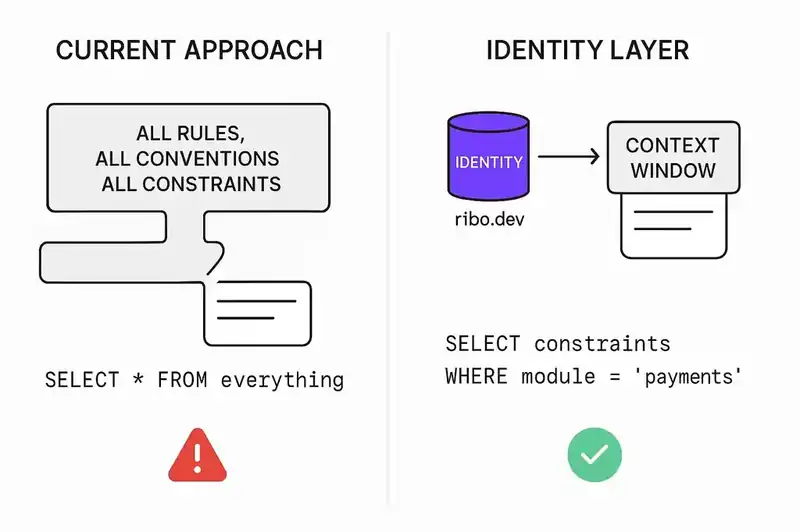
A static rules file is a markdown document. It gets injected wholesale into every prompt. It has no mechanism for scoping -- the agent gets all of it, all the time, regardless of the task. It can't be queried. It can't filter itself based on what the agent is doing. It doesn't know whether the current task involves the payment module or the notification service. It just dumps everything and hopes the model figures out what's relevant.
A persistent identity layer is a structured, queryable store. The agent doesn't receive the full identity on every request. It queries the layer for the specific constraints, boundaries, and contracts relevant to the current task. Working on the payment module? The layer returns the payment module's architectural constraints, its integration contracts with downstream services, its test coverage requirements. It doesn't return the notification service's deployment pipeline or the frontend's component naming conventions.
The difference is the difference between SELECT * FROM everything and SELECT constraints FROM modules WHERE name = 'payments'.
This is why MCP is interesting as a transport layer, even if current MCP implementations have the token bloat problem described above. An MCP server can expose identity as a queryable resource rather than a static dump. The agent connects to the identity server, describes what it's working on, and receives the relevant subset. The full identity persists on the server side. Only the relevant fragment enters the context window.
This already works for other kinds of state. Database MCP servers don't dump every table's contents into the context window. They expose query tools. The agent describes what it needs, and the server returns the relevant data. An identity layer works the same way.
The practical path
None of this requires waiting for a new protocol or a new standard. The pieces exist.
Start by separating identity from context. Take your AGENTS.md or CLAUDE.md file and ask: which of these instructions are situational, and which are structural? Situational instructions belong in context -- attached to specific tasks, specific files, specific workflows. Structural declarations -- your module boundaries, your architectural constraints, your integration contracts -- belong in a persistent layer that the agent queries rather than receives wholesale.
Scope aggressively. The ETH Zurich finding is clear: comprehensive context files hurt more than they help. If you keep a static rules file, strip it to the minimum the agent needs for the most common tasks. The researchers found that removing documentation from repos made auto-generated context files useful again -- because the files were no longer redundant with information the agent could already find. Apply the same principle. Don't tell the agent what it can discover on its own.
Treat tool definitions as on-demand resources. If you run MCP servers, evaluate whether you need every tool definition loaded at initialization. Dynamic toolsets, progressive disclosure, and on-demand loading can reduce input tokens by 90% or more. The 40-tool limit in Cursor isn't a bug to work around. It's a signal about how many tool definitions a model can usefully hold in context.
Version your identity declarations. If your project identity lives in a queryable store rather than a flat file, it becomes versionable, diffable, and auditable. You can see when an architectural constraint was added, who changed it, and why. You can diff the identity declaration the same way you diff code. This matters for compliance, for onboarding, and for understanding why the system is the way it is.
Stop duplicating across formats. If you're maintaining .cursorrules, CLAUDE.md, copilot-instructions.md, and AGENTS.md with substantially similar content, you have a synchronization problem that will only get worse. Either converge on one format or -- better -- move the source of truth to a layer that all tools can query, and generate tool-specific files from it.
The pipe is big enough
The context window is not the bottleneck. It has not been for a while. Claude supports 200K tokens. Gemini supports a million. GPT-5 is in the same range. The bottleneck is what is in the window — how much of it is signal, how much is noise, and how much is the same static identity declaration being re-read for the hundredth time in the same session.
The ETH Zurich study measured what a lot of practitioners already suspected: more context can make agents worse. Not theoretically worse. Measurably worse. Three percent worse at the task and twenty percent more expensive doing it.
The fix is not less context. It is the right context at the right time. Identity that persists rather than re-transmits. Constraints that the agent queries rather than receives in bulk. A schema, not a haystack.
We have spent two years scaling the pipe. Bigger windows. More tokens. Faster retrieval. The pipe is big enough. The question now is what we put through it.
The pipe is big enough. We're building the identity layer that makes what goes through it queryable, not dumped.