
It's 3:14am. Your phone is screaming. The checkout service is down. Revenue is bleeding at a rate you can calculate in your head but wish you couldn't.
You open your laptop. You pull up the alert. You look at the service name and feel nothing -- no recognition, no muscle memory, no mental map of what this thing does or how it connects to everything else. The engineer who built it left six months ago. The engineer who maintained it after that transferred to another team in January. You are the on-call engineer tonight, and you have never seen this code.
You have about forty-five minutes before this becomes a headline.
Where do you start?
The knowledge that doesn't exist
You try the README. Last updated fourteen months ago. It references an environment variable that no longer exists and a deployment process that was replaced two migrations ago.
You try Confluence. You find a page titled "Checkout Service Architecture" with a last-modified date from Q3 of last year. The diagram shows four dependencies. The service now has nine. Three of the boxes in the diagram link to services that have been renamed. One links to a service that was decommissioned.
You try Slack. You search for the service name and get 2,400 results spanning two years. Somewhere in there, buried in a thread from last August, is the critical piece of context that would cut your resolution time in half. You will not find it tonight.
You start reading code.
This is the most expensive moment in software: someone who has never touched a system needs to understand it under pressure, in the dark, with the clock running.
The scale of what we don't write down

By most estimates, roughly 80% of the knowledge in an organization is tacit, held in people's heads, never written down, never structured, never made queryable. This isn't a technology industry problem. It's a human organization problem. But technology makes it worse because the systems we build are complex, interdependent, and changing constantly.
Avelino et al. studied the bus factor across 1,932 open source projects and found that 65% of them had a bus factor of two or fewer. Two people. If two people leave, the project's critical knowledge walks out the door with them. And that's open source, where the code is public and anyone can theoretically contribute. Inside companies, where code is private and context is even more closely held, the situation is worse.
We know this intuitively. Every engineering leader has felt the cold sweat of a key person giving notice. But we treat it as a people problem: retention, documentation, culture. We write better runbooks. We schedule knowledge-sharing sessions. We create onboarding documents that go stale within weeks.
The problem isn't effort. We're trying to solve a structural gap with process. You can't process your way out of a system that has no persistent, queryable identity.
The cost of searching for answers
The 3am incident is the dramatic version of a problem that happens every day at every scale.
Stripe's Developer Coefficient research found that the average developer spends more than 17 hours per week on maintenance tasks: debugging, refactoring, understanding existing systems. That's nearly half of a forty-hour week spent not building, but comprehending. Code that someone else wrote, or that they themselves wrote six months ago and no longer remember, or that an AI agent generated and nobody fully reviewed.
In customer support, the parallel is even more stark. Industry research consistently shows that support agents spend significant portions of every hour searching for information rather than solving problems. New agents take three to six weeks to reach competency, and during that ramp period, their handle times run 20-30% longer than veterans. The reason isn't capability. It's context. They don't know what they don't know, and the systems they need to query don't contain the answers.
Now multiply this across an engineering organization. Every new hire, every rotation, every on-call shift where the responder hasn't touched the service -- each one is a cold start. Each one requires the engineer to reconstruct context that someone else already built and never externalized.
The cost isn't just time. It's decision quality. An engineer who doesn't understand a system's boundaries makes changes that violate them. An engineer who doesn't know the downstream consumers of an API breaks them. An engineer who doesn't understand the compliance constraints on a data pipeline creates audit findings six months later.
The microservices multiplier
This problem would be manageable if we were still building monoliths. A monolith has one codebase. You can grep it. You can trace a request through it. The knowledge is at least co-located, even if it's not documented.
We don't build monoliths anymore. According to industry surveys, 85% of large organizations have adopted or are adopting microservices. The benefits are real: independent deployment, team autonomy, technology flexibility. But there's a cost that rarely appears in the architecture decision record: every service boundary is a knowledge boundary.
When you decompose a monolith into forty services, you don't just distribute the code. You distribute the context. Service A knows things about the domain that Service B needs to understand but has no structured way to access. The engineer who owns the payment service understands why the retry logic uses exponential backoff with a specific ceiling. The engineer who owns the checkout service, which calls the payment service, has no idea. When the checkout service starts timing out at 3am because someone changed the payment service's retry behavior, the on-call engineer is staring at two codebases with no map between them.
Sixty-two percent of organizations using microservices report that managing inter-service dependencies is a "significant challenge." In practice, that means: we have services that depend on each other in ways nobody has fully mapped, and when something breaks at the seam, we page someone who has to figure out the map in real time.
What the knowledge experiment proved
There's a research finding worth spending a moment on.
Google's Developer Relations team published work on what they call "agent skills," structured knowledge files that give AI coding agents access to current, accurate information about the APIs they're working with. They tested what happens when you give a coding agent a structured skill file for the Gemini API versus leaving it to work from training data alone.
On a 117-prompt evaluation harness, Gemini 3.1 Pro went from a 28.2% success rate without the skill file to 96.6% with it. Same model. Same tasks. The only variable was whether the agent had access to a structured, current description of the SDK it was supposed to use.
The test was narrow (it measured whether coding agents could generate correct Gemini SDK calls instead of deprecated ones) but the principle generalizes. 28.2% is an agent that mostly fails. 96.6% is an agent that mostly works. The difference wasn't a better model or more training data. The difference was structured, current knowledge.
Now apply that to your 3am engineer. They're the agent. The failing service is the task. Do they have access to a structured, current, queryable source of truth about the system, or are they working from stale docs, tribal knowledge, and code archaeology?
What the existing tools get wrong
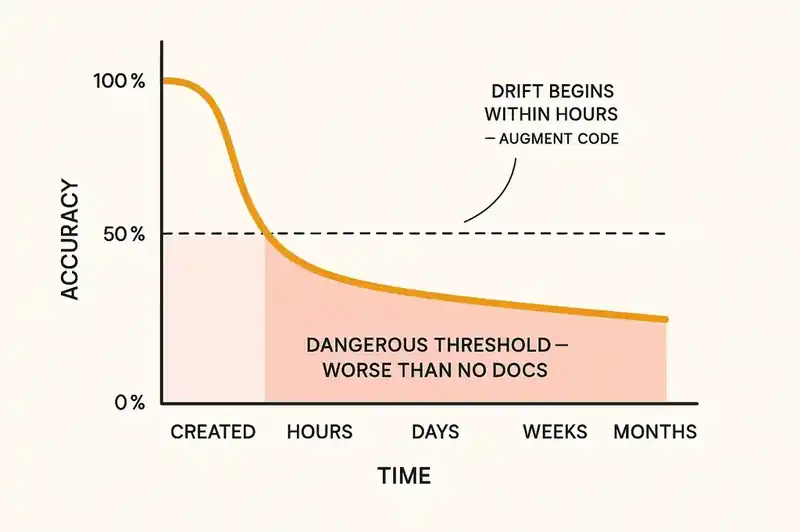
We've tried to solve this before. We have wikis, runbooks, architecture decision records, Confluence spaces, Notion databases, internal developer portals. Every engineering organization has at least three of these, and none of them work reliably at 3am.
The failure mode isn't initial creation. Engineers write documentation during onboarding when everything is fresh, during postmortems when the pain is sharp, or when a new VP mandates "documentation sprints."
The failure mode is maintenance. Documentation decays because there's no mechanism to detect that it has drifted from the system it describes. The checkout service gets a new dependency, nobody updates the architecture page. The retry logic changes, nobody updates the runbook. The compliance requirement changes, nobody updates the ADR.
As Augment Code has observed, most specification documents drift from implementation within hours. Not weeks. Not months. Hours. The half-life of accuracy for a static document in a fast-moving codebase is measured in hours.
This is why runbooks become dangerous, worse than no documentation, because they give false confidence. An engineer following an outdated runbook at 3am isn't just failing to solve the problem. They're actively making it worse, executing steps that no longer correspond to the system's actual behavior.
The problem isn't that engineers don't write documentation. Documents are inert. They don't know when they're wrong. They can't detect their own drift. They sit in a wiki, confidently incorrect, until someone discovers the hard way that the world has moved on.
What a queryable identity layer looks like at 3am
Now imagine a different 3am.
The page comes in. The checkout service is down. The on-call engineer has never touched this service. But instead of opening a stale README, they query the service's identity.
They ask: what is this service? The identity layer answers: it processes user checkout flows, manages cart-to-order conversion, and coordinates with three downstream services -- payment processing, inventory, and notification. It does not manage user authentication, product catalog, or pricing. It was last deployed four hours ago.
They ask: what changed? The identity layer answers: the last deployment modified the payment service integration. The behavioral contract with the payment service specifies a 200ms P99 latency guarantee with idempotent retries. The current payment service latency is 3,400ms.
They ask: what depends on this? The identity layer answers: the mobile app, the web frontend, and the merchant dashboard all consume this service. The merchant dashboard has a fallback to cached order state. The mobile app and web frontend do not.
They ask: who owns the payment service? The identity layer answers: the payments team. The current on-call is this person, reachable at this number.
In four queries, the engineer has the context that would have taken forty-five minutes of code reading, Slack searching, and Confluence spelunking. They know the blast radius. They know what changed. They know who to call. They know what the system is supposed to do, not just what it's doing right now.
This isn't a chatbot or a search engine over documentation. It's a structured, machine-readable, continuously reconciled declaration of what the software is: its purpose, contracts, constraints, and relationships. It stays current because it's part of the system's identity, not a side artifact someone maintains out of goodwill.
When the identity declaration says the payment service has a 200ms P99 guarantee and the actual latency is 3,400ms, that's not a documentation discrepancy. That's a detectable violation. The system knows it's broken before the engineer does.
The compounding cost of not having this
Every incident where an engineer spends forty-five minutes reconstructing context is a cost, but the real damage is cumulative.
An engineer makes a change without understanding the system's boundaries, introducing drift. The drift goes undetected. It compounds. The system becomes harder to understand, which makes the next incident longer, which makes the next change riskier.
This is how simple systems become incomprehensible. Not through any single decision, but through thousands of small changes made without a persistent reference for what the system is supposed to be. The identity erodes. Once nobody can authoritatively answer "what is this service, what does it guarantee, and what are its boundaries," you're not maintaining software anymore. You're doing archaeology.
The 3am engineer who can't find the answer isn't the problem. They're the symptom. The problem is that the answer was never externalized in a form that survives the departure of the people who knew it.
What this does and doesn't fix
Structured identity layers don't prevent incidents. Services will fail. Dependencies will break. Latency will spike at 3am on a holiday weekend.
The claim is narrower: the time between "something is broken" and "I understand what's broken and why" is the most compressible part of incident response. It's compressed by giving responders structured, current, queryable knowledge about the systems they're responsible for.
Google's DevRel team showed this with coding agents: a structured skill file took Gemini API task success rates from 28% to 96%. The same principle applies to human agents, the on-call engineers, the new hires, the people rotating onto a team they've never worked with.
The industry has spent two decades building better alerting, better monitoring, better dashboards. We can detect failures faster than ever. But detection without comprehension is just a faster page to an engineer who still has to spend forty-five minutes figuring out what they're looking at.
The missing layer isn't observability. It's identity. We have metrics and traces for "what is this service doing right now." What we don't have is a persistent, structured, queryable answer to "what is this service, what is it supposed to do, what are its boundaries, and how does it connect to everything else." Those are the questions every 3am engineer asks, and no monitoring tool can answer them.
That layer doesn't exist for most software today. Not because of a technology gap, but because of an assumption gap. We assumed someone on the team would always know. We assumed the README would stay current. We assumed tribal knowledge would transfer through osmosis and Slack threads.
Those assumptions held when teams were small, systems were simple, and people stayed in jobs for years. None of those conditions hold anymore. The systems are distributed, the teams rotate, the people leave, and the AI agents generating code never knew the intent in the first place.
The 3am engineer deserves better than a stale wiki page and a commit log. They deserve a system that knows what it is.