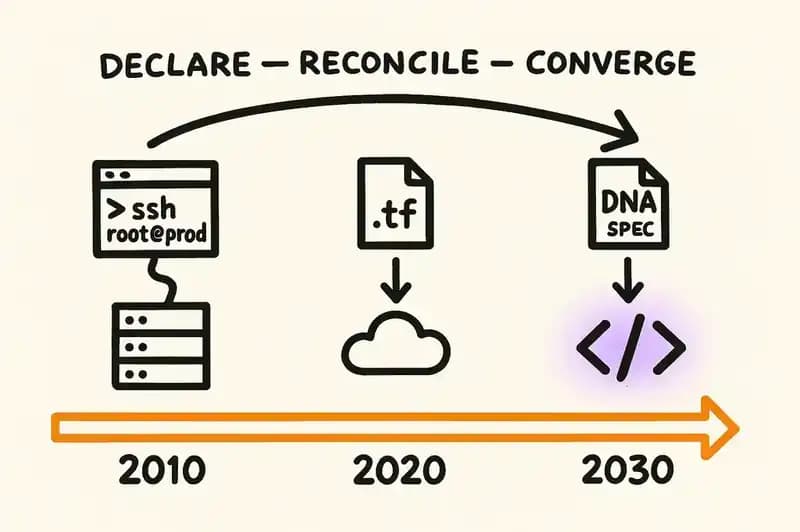
Remember SSH-ing into servers?
Not the nostalgic kind of remembering. The 2 AM kind. A load balancer misconfigured, traffic hitting a dead backend, and you're tunneled into a production box making changes by hand. You edit a config file. You restart a service. You pray. Maybe you document what you did in a wiki that nobody will read, including you, three months from now.
That was infrastructure management in 2010. Manual, imperative, stateful only in the sense that the state lived in someone's head and on a server that could vanish.
Then HashiCorp built Terraform. The premise: don't describe the steps to reach the desired state. Describe the desired state. Let the machine figure out how to get there.
resource "aws_instance" "web" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t3.micro"
tags = {
Name = "web-server"
Environment = "production"
}
}
Nine lines. You declare what should exist, run terraform apply, and the reconciliation engine handles the rest. If the actual state drifts from the declared state, the next apply corrects it. No SSH, no imperative scripts, no manual steps to document and forget.
IBM acquired HashiCorp for $6.4 billion in February 2025. That price tag wasn't for the tooling. It was for the pattern -- declare, reconcile, converge -- applied across every cloud and every team.
The pattern won. Nobody serious is SSH-ing into production servers to hand-configure infrastructure anymore.
Now look at how we build application software in 2026.
The thing we haven't stopped doing
We're still SSH-ing into the code.
Not literally. But the workflow is structurally the same. A developer (or increasingly an AI agent) opens a file, makes imperative changes, and commits them. The intent behind the change lives in a Jira ticket written by a PM who left six months ago, a Slack thread that's been archived, or a pull request description that says "fix billing bug" without specifying which billing behavior was wrong and which was correct.
The code is the only artifact that persists. And the code tells you what it does, not what it should do. It's the configured server, not the Terraform file.
This was always a problem. Every senior engineer has a story about a function that does something inexplicable because nobody at the company knows why it was written that way, and everyone is afraid to change it because the tests are thin and the specification never existed.
Now multiply that by AI. GitClear's analysis of 211 million changed lines of code found that 41% of committed code was AI-generated by mid-2025. Code churn (the rate at which code is rewritten shortly after being written) doubled compared to 2021. Duplicated code blocks increased 8x. We're generating more code, faster, with less understanding of what it's supposed to do or why.
That's the infrastructure equivalent of SSH-ing into 10,000 servers simultaneously and making changes to all of them without a configuration management system. The speed doesn't make this less reckless. It makes it worse.
The Terraform parallel
Terraform didn't succeed because HCL is elegant. It succeeded because it separated two things that were previously tangled: the declaration of desired state and the implementation of that state.
Before Terraform, the configuration was the implementation. You wrote shell scripts, ran Ansible playbooks, used Chef recipes. The steps to reach the desired state were the only record of what the desired state was. If you wanted to know what your infrastructure should look like, you had to read the scripts and mentally execute them. Or look at the running servers and hope they matched.
Terraform decoupled the what from the how. You declare the what in .tf files. Providers handle the how. The .tf files become the source of truth. You can delete every server and recreate the entire infrastructure from the declarations alone.
The same decoupling is starting to happen with application software. The industry is calling it Specification-Driven Development. ThoughtWorks Technology Radar Volume 33 (November 2025) placed it in the "Assess" ring. Martin Fowler and Birgitta Bockeler published an analysis on martinfowler.com examining the pattern across multiple tools. InfoQ called it "a declarative, contract-centric control plane" where "the specification serves as the system's primary executable artifact" and "implementation code becomes a secondary, generated representation of architectural intent."
That last sentence is the Terraform move applied to application code. The spec is the .tf file. The code is the running server.
Three levels of separation
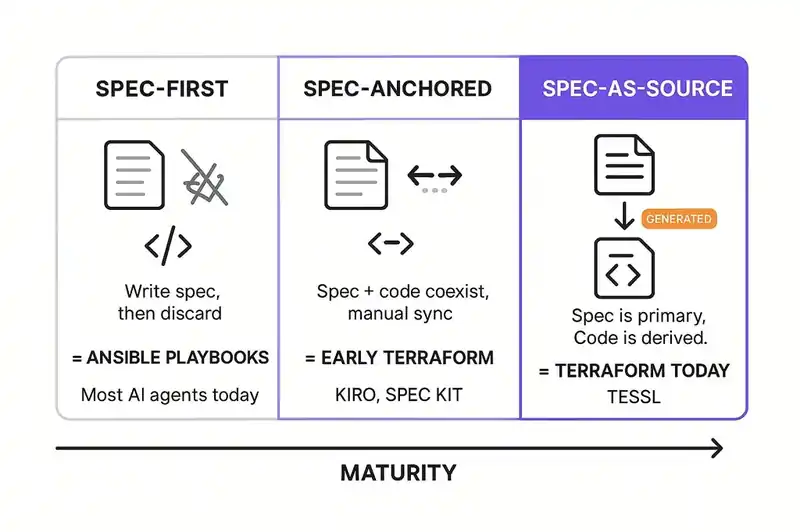
Fowler and Bockeler identify three maturity levels for spec-driven development. The progression maps closely onto the history of infrastructure automation.
Spec-first. You write a specification before coding, then throw it away. The spec is a planning document. It informs the implementation but doesn't govern it. This is the Ansible equivalent: you write a runbook, execute it manually, and the runbook drifts from reality immediately because nothing enforces the connection.
Most teams using AI agents today are at this level, whether they know it or not. They write prompts. The prompts contain implicit specifications. The agent generates code. The prompts are discarded or buried in chat history. The implementation is the only surviving artifact.
Spec-anchored. You write a specification and keep it. As the implementation evolves, you update the spec. The spec and the code coexist as co-authoritative artifacts. This is the early Terraform stage: you have .tf files and you have running infrastructure, and you try to keep them in sync, but the sync is manual and drift happens.
This is where the current generation of spec-driven tools operates. GitHub Spec Kit, AWS Kiro, and Tessl all live in this space, though they approach it differently and Tessl is pushing toward the next level.
Spec-as-source. The specification is the primary artifact. Code is generated from it. Humans edit the spec, not the code. Generated code carries markers -- Tessl uses // GENERATED FROM SPEC - DO NOT EDIT -- that formalize the relationship. The spec isn't just authoritative. It's the only thing that's maintained. The code is a build artifact, like a compiled binary.
This is the Terraform endgame. Nobody edits the running EC2 instance's configuration by hand anymore. You edit the .tf file. You apply. The infrastructure converges. Applied to application code, the same pattern means you edit the spec, you generate, and the code converges.
We're not there yet. But the trajectory is the same one infrastructure followed over the past decade.
What the tools look like today
The tooling is real and shipping, though fragmented -- each tool solves a different slice of the problem in its own way.
AWS Kiro
Kiro, which reached general availability in November 2025 after a preview with over 250,000 developers, organizes development around three files:
<!-- requirements.md -->
# User Authentication
## User Stories
- As a user, when I submit valid credentials,
the system shall create an authenticated session
and return a session token.
- As a user, when I submit invalid credentials,
the system shall return an authentication error
without revealing whether the email or password was incorrect.
## Acceptance Criteria
- [ ] Session tokens expire after 24 hours
- [ ] Failed login attempts are rate-limited to 5 per minute
- [ ] All authentication events are logged for audit
<!-- design.md -->
# Authentication Service Design
## Architecture

- Stateless token validation using JWT
- Password hashing with bcrypt (cost factor 12)
- Rate limiting via sliding window counter in Redis
## Component Interfaces
- AuthController: HTTP endpoints for login/logout/refresh
- TokenService: JWT creation, validation, refresh
- RateLimiter: Per-IP sliding window enforcement
## Data Model
- users: id, email, password_hash, created_at
- sessions: id, user_id, token_hash, expires_at
- login_attempts: id, ip_address, timestamp, success
<!-- tasks.md -->
# Implementation Tasks
- [x] Set up project structure and dependencies
- [x] Implement User model with bcrypt password hashing
- [ ] Implement TokenService with JWT creation/validation
- [ ] Implement RateLimiter with Redis sliding window
- [ ] Implement AuthController endpoints
- [ ] Add audit logging middleware
- [ ] Write integration tests against acceptance criteria
Three files: requirements, design, tasks. The agent works through the tasks. The requirements and design persist as governing documents. It works well for greenfield features.
The limitation is that the specifications don't actively govern the generated code after initial creation. Kiro uses EARS notation (Easy Approach to Requirements Syntax) to structure requirements into testable statements, but they're reference documents, not a control plane. That's spec-anchored, not spec-as-source.
GitHub Spec Kit
Spec Kit, which has attracted over 70,000 stars since its September 2025 launch, takes a different approach. It's an open-source CLI that integrates with Copilot, Claude Code, Gemini CLI, and over a dozen other agent platforms. The core idea: a "constitutional foundation" of project-level constraints that agents must obey.
# .spec/config.yaml
project:
name: "payment-service"
language: "typescript"
framework: "fastify"
constraints:
- "All monetary values use integer cents, never floating point"
- "Every public endpoint requires authentication middleware"
- "Database queries must use parameterized statements"
- "No direct console.log in production code paths"
architecture:
pattern: "hexagonal"
layers:
- domain # Business logic, no framework dependencies
- ports # Interface definitions
- adapters # Framework and infrastructure implementations
Spec Kit doesn't generate code directly. It provides the specification scaffolding that agents work against, closer to a linter for intent: here are the rules, here are the boundaries, now generate code that respects them.
The limitation is that the specifications are static. They constrain initial generation but don't detect when later changes violate them. Catching drift is still a manual job.
Tessl
Tessl is the most ambitious of the three. Founded by Guy Podjarny (previously founder of Snyk), Tessl explicitly targets the spec-as-source level. Their specs are .spec.md files with YAML frontmatter:
---
name: Payment Processing
description: Processes transactions between buyers and merchants
targets:
- ../src/payments/*.ts
---
# Payment Processing
Handles payment authorization, capture, and settlement
for card-present and card-not-present transactions.
## Capabilities
- **Authorize Payment** [@test](../tests/authorize.test.ts)
Validates card details, checks available balance,
and places a hold on the transaction amount.
Must be idempotent for the same transaction ID.
- **Capture Payment** [@test](../tests/capture.test.ts)
Converts an authorized hold into a completed charge.
Must fail gracefully if authorization has expired.
- **Refund Payment** [@test](../tests/refund.test.ts)
Reverses a captured payment. Partial refunds supported.
Refund amount must not exceed original capture amount.
## API
```typescript
interface PaymentService {
authorize(request: AuthorizeRequest): Promise<Authorization>;
capture(authId: string, amount?: number): Promise<Capture>;
refund(captureId: string, amount?: number): Promise<Refund>;
}
```
The targets field links the spec to the source files it governs. The @test links bind each capability to its verification. The generated code carries the // GENERATED FROM SPEC - DO NOT EDIT marker. When the spec changes, code is regenerated. When someone edits the code directly, the Tessl framework flags the divergence.
Tessl also ships a Spec Registry, a package-manager-like system for sharing and versioning specs across teams and organizations. The intent is to make specs composable and publishable, more like packages than documents.
Of the three tools, this comes closest to the Terraform model for application code. Spec declares intent, framework generates implementation, registry versions the whole thing. And when someone edits the generated code directly, you find out.
The unsolved problem
The Terraform parallel breaks down here, and the breakdown matters more than the places where the analogy is tidy.
Terraform's reconciliation works because infrastructure has a well-defined API surface. An EC2 instance either exists or it doesn't. It either has the declared instance type or it doesn't. The diff between declared state and actual state is computable. Terraform can look at the .tf file, query the AWS API, compare the two, and produce a plan that describes exactly what will change.
Application code doesn't have this property. The relationship between a natural-language specification and a codebase is semantic, not structural. You can't diff a spec file against source code the way you diff a .tf file against the AWS API. "Must be idempotent for the same transaction ID" is a behavioral property that might be implemented through database constraints, application-level checks, message deduplication, or some combination. Verifying that the implementation satisfies the spec requires something between static analysis and program understanding.
This is the drift problem, and it's severe. Augment Code (a company building spec-driven development tooling) published a finding that should make everyone in this space uncomfortable: specifications drift from implementation within hours.
The failure mode is predictable. A developer (or an agent) makes a change that's locally correct but violates a spec in a way that no existing tool detects. Another change builds on the first. A third change makes it worse. Within a day, the spec describes a system that no longer exists. Within a week, the spec is fiction.
This is the same failure mode that configuration management had before Terraform. Ansible playbooks describing infrastructure that had been manually modified. Chef cookbooks that were accurate on the day they were written and wrong by Thursday. The solution in infrastructure was the reconciliation loop: continuous, automated comparison of declared state against actual state, with corrective action when they diverge.
The equivalent reconciliation loop for application code doesn't exist yet -- not at the infrastructure level, not as a primitive that every tool can compose on top of.
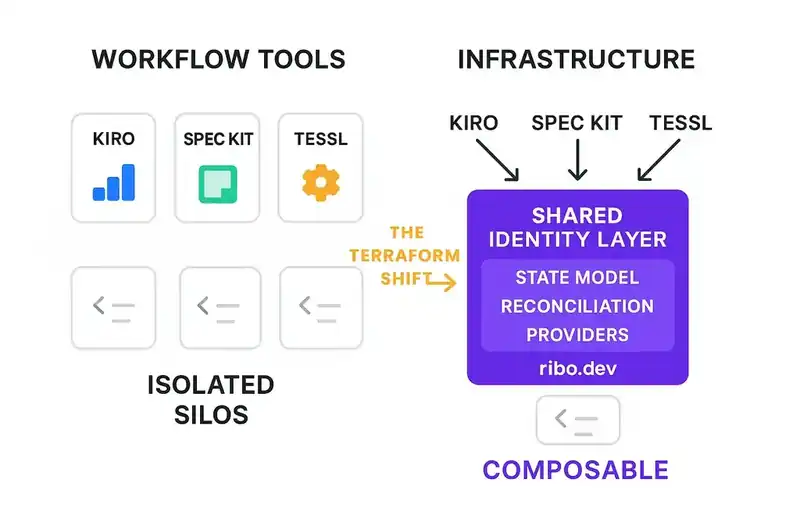
Workflow tools vs. infrastructure
Most of what the industry is building right now is workflow tools. Kiro structures the development process. Spec Kit constrains agent behavior during generation. Tessl links specs to code and detects divergence. All three are useful and all three beat the "prompt and pray" era of 2024.
But they're not infrastructure. They're not primitives.
Terraform isn't a workflow tool. It's an infrastructure layer: a state file, a reconciliation engine, a provider ecosystem, and a declarative language. Any tool can build on top of it. The workflow emerges from the infrastructure, not the other way around.
The spec-driven development ecosystem today is all workflow, no infrastructure. Every tool has its own spec format. Kiro uses three markdown files. Spec Kit uses YAML. Tessl uses .spec.md with YAML frontmatter. There's no interchange format, no shared state model, no common reconciliation protocol. One tool's specs can't feed into another tool's reconciliation engine.
Imagine if every cloud provider had its own incompatible infrastructure-as-code format with no abstraction layer between them. That was the world before Terraform. That's the spec-driven development world right now.
Infrastructure went through a clear progression: imperative scripts, then per-platform declarative tools, then a cross-platform declarative layer (Terraform), then a reconciliation ecosystem (providers, state management, drift detection). Application specifications are somewhere between stage one and stage two.
What reconciliation looks like
If we take the Terraform parallel seriously, the application equivalent of terraform plan would look something like this:
$ sdna plan
Analyzing spec drift for payment-service...
~ payment-service/authorize
spec: "Must be idempotent for the same transaction ID"
impl: No idempotency check found in authorize handler
file: src/payments/authorize.ts:47
action: DRIFT DETECTED - implementation missing spec guarantee
+ payment-service/webhook-handler
impl: src/payments/webhooks.ts (217 lines, 4 endpoints)
spec: No specification found
action: UNSPECIFIED CODE - implementation exists without spec
- payment-service/legacy-refund
spec: "Legacy refund endpoint for v1 API compatibility"
impl: No implementation found
file: (deleted in commit a3f2c1d)
action: SPEC WITHOUT IMPLEMENTATION - spec may be stale
Plan: 1 drift, 1 unspecified, 1 potentially stale.
Three types of drift, each requiring different action: a spec guarantee that the implementation doesn't satisfy, code that exists without a governing spec, and a spec that describes code that no longer exists.
Terraform solves all three for infrastructure. terraform plan shows you resources that have drifted, resources that exist outside Terraform's management, and resources that Terraform expects but can't find. Same categories, same detection, same corrective workflow, just applied to a domain where the diff is computable.
The hard part isn't the workflow. The hard part is the detection engine: computing the semantic diff between a natural-language specification and a codebase. That wasn't tractable five years ago. With current language models, it's feasible but not solved. The models catch obvious drift and miss subtle drift. So the reconciliation loop needs to be continuous, layered, and integrated with existing verification tools (tests, type systems, static analysis) rather than replacing them.
What 2030 looks like
If the Terraform trajectory holds, here's a plausible state of the world in four years.
Spec files live in version control alongside code, and they're the primary artifact reviewed in pull requests. Not a document that informs the code, but the thing the code is derived from. Changing a spec is a decision; changing code is execution. Pull request reviews focus on the spec diff. Code review becomes implementation review (does this code satisfy the spec?) rather than design review.
Agents generate and regenerate code from specs continuously. The // GENERATED FROM SPEC - DO NOT EDIT pattern is standard. Developers modify code by modifying specs. Direct code edits trigger the same kind of alarm that manually modifying a Terraform-managed resource triggers today: you can do it, but the system flags it and the next reconciliation pass either overwrites your change or requires you to update the spec.
Drift detection runs in CI. Every pull request includes a drift report. Every deployment requires a clean drift check. "The spec says X, the code does Y" is a build failure, not a code smell -- the way terraform plan output is reviewed before terraform apply.
Teams publish spec packages the way they publish library packages today. A team building against your payment service imports your payment spec, not your payment client library. The spec defines the contract. The client is generated from it. Breaking changes in the spec are detected at import time, not at runtime.
The format fragmentation of 2025-2026 has resolved. Not into one format (Terraform has HCL, Kubernetes has YAML, CloudFormation has JSON) but into a small number of well-understood formats with clear tooling ecosystems, the way infrastructure-as-code fragmentation resolved through competition and adoption.
New developers onboard by reading specs, not code. The same way new infrastructure engineers onboard by reading .tf files and helm charts, not by SSH-ing into servers and reading config files. The spec tells you what the system does and why. The code tells you how. For someone trying to understand intent, the how is secondary.
None of this is speculative in the abstract. It's what infrastructure already looks like. We're just projecting a pattern that has already played out once in an adjacent domain.
Where the analogy might break
Specifications might become the new Big Design Up Front. ThoughtWorks flagged this risk in their Radar assessment: a bias toward heavy upfront specification and big-bang releases. The whole point of agile was that we couldn't specify everything in advance. If spec-driven development recreates waterfall with markdown files instead of UML diagrams, it will fail for the same reasons waterfall failed. Terraform works because a resource block is four lines, not forty pages. The specification has to be that lightweight, or it won't survive contact with real teams.
The reconciliation problem might be harder than we think. Infrastructure reconciliation works because APIs are precise. Application behavior is fuzzy. "The system should respond quickly" isn't something a reconciliation engine can enforce. The gap between natural language and formal verification is real, and current language models narrow it without closing it. The reconciliation loop might require specifications to be more formal than most teams are willing to write, and there's no clean answer to that trade-off yet.
Adoption will be uneven and slow. Terraform was released in 2014. It took until roughly 2018-2019 for declarative infrastructure to become the default at well-run engineering organizations. Even now, plenty of teams run infrastructure manually. The application equivalent will take at least as long: some teams spec-first, some spec-anchored, most still spec-never, for years.
The tooling ecosystem might fragment permanently. Not every technology space converges. Build systems didn't. Package management didn't cleanly. If every agent platform ships its own incompatible spec format, the infrastructure layer never materializes and specs remain workflow-local rather than composable across tools and organizations.
Workflow problem or infrastructure problem
The Terraform parallel isn't just an analogy. It's a prediction about what kind of problem spec-driven development actually is.
If SDD is a workflow problem, the current tools are sufficient. Kiro, Spec Kit, and Tessl each provide a workflow that's better than "prompt and pray." Teams will adopt one, build habits around it, and get value. The ecosystem will be fragmented but functional, the way task management tools are fragmented but functional.
If SDD is an infrastructure problem -- if the industry needs a shared, composable, reconcilable identity layer for software -- then the current tools are scaffolding. Useful scaffolding, but not the end state. The end state looks more like Terraform: a declarative layer with a state model, a reconciliation engine, a provider ecosystem, and enough gravity to pull the rest of the toolchain toward it.
We think it's the latter. Not because workflow tools aren't useful, but because the problem they're solving (drift between intent and implementation) is a problem that workflow alone has never solved. Configuration management was a workflow before Terraform turned it into infrastructure. Deployment was a workflow before CI/CD pipelines did the same. Each time, the arc is the same: manual practice, then workflow tooling, then infrastructure. The workflow tools prove the need. The infrastructure makes it stick.
What we actually believe
We won't pretend to know exactly what the next decade looks like. The specific tools, formats, and vendors that dominate are unpredictable.
What we're confident about is the direction.
Infrastructure moved from imperative to declarative because imperative management doesn't scale. Application development is hitting the same wall, accelerated by AI-generated code that makes the scaling problem 10x worse 10x faster.
Somewhere in the next two to five years, someone will build the reconciliation engine that makes declared application intent as enforceable as declared infrastructure state. The spec won't just inform the code. It will govern it, the way a .tf file governs an EC2 instance.
When that happens, writing application code by hand will feel the way SSH-ing into servers feels now. It worked. It worked for a long time. But eventually you wonder why you spent all those years doing it the hard way.
We think about this problem constantly. If you're building in this space or adopting these patterns, we'd like to hear where the analogy holds and where it breaks.