
A team we know (mid-stage fintech, fourteen engineers) adopted AI coding tools across the board in early 2025. By Q3, their velocity metrics were extraordinary. Pull requests merged 3x faster. Feature branches closed in days instead of weeks. Sprint burndown charts looked like cliffs. Management was thrilled.
Six months later, a senior engineer quit. The team needed to modify the payment reconciliation service she'd built with heavy AI assistance. Three engineers spent two weeks reading code that had been merged by their own teammates. They couldn't determine why the retry logic used exponential backoff in one path and linear backoff in another. They couldn't tell if the duplicate validation in the webhook handler was intentional redundancy or a copy-paste artifact. The code passed every test. It met every lint rule. Nobody understood it.
This is not a story about bad code. The code was fine. This is a story about a new category of debt that the industry doesn't have vocabulary for yet.
The wrong diagnosis
The conversation around AI-generated code quality keeps getting louder, and most of it is aimed at the wrong target.
An arxiv study (2603.28592) analyzed 304,362 AI-authored commits across 6,275 GitHub repositories and cataloged 484,606 distinct issues. GitClear's 2025 analysis of 211 million changed lines found an 8x increase in duplicated code blocks and 39% higher code churn in AI-generated output. Stack Overflow's 2025 Developer Survey put developer trust in AI code accuracy at 29%, down from 40% the year before. The numbers are real. The code quality problem is real.
But framing this as a code quality problem is like framing a building collapse as a brick quality problem. The bricks might also be bad. But the failure is structural.
What we see in the teams we work with, and what the data increasingly supports, is three distinct forms of debt accumulating at once. They compound at different rates and resist different interventions. Only one is about the code itself.
Debt one: cognitive debt
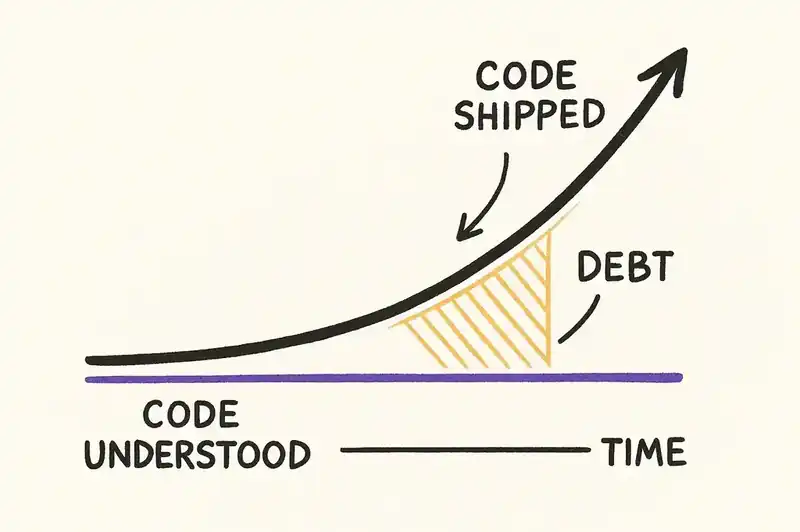
Cognitive debt is the gap between what a team has shipped and what a team understands.
This isn't new in concept. Every engineer has inherited a codebase they didn't write. But the rate of accumulation is new. When a human writes code, understanding is a byproduct of authorship. When an AI writes code and a human commits it, that byproduct vanishes. The code exists. The understanding doesn't.
The METR study quantified something teams have been feeling but couldn't articulate. Experienced open-source developers using AI tools took 19% longer on real tasks while believing they were 20% faster. A 39-percentage-point perception gap. The developers weren't lying. They felt faster. The AI was generating code rapidly, prompts were flowing, diffs were appearing. But total time from task start to verified completion was longer, not shorter.
Why? Because they were spending time they didn't account for: reading generated code, verifying it, re-prompting when it was wrong, and building a mental model of code they didn't write. That last part is cognitive debt accumulating in real time.
The compounding problem: cognitive debt doesn't announce itself. A team carrying heavy cognitive debt looks fine on every dashboard. PRs are merging. Tests are passing. Deployments are green. The debt surfaces only when someone needs to change or debug code they don't understand. By that point, the cost of paying it down is enormous, because you're reverse-engineering intent from implementation. That is the hardest problem in software maintenance.
Traditional code review was supposed to be the backstop. When a human writes code and another human reviews it, two people understand the change. When an AI writes code, one person prompts it, and another person reviews a diff they didn't expect. How many people understand the change? Often zero.
Debt two: verification debt
Verification debt is the gap between what a team has approved and what a team has actually verified.
Every engineer has rubber-stamped a PR. This is also not new. What's new is the scale and the structural incentive.
AI-generated diffs are often large, syntactically correct, and internally consistent. They look right. They frequently are right. The review interface (GitHub, GitLab, whatever) presents them identically to human-authored diffs. No visual distinction, no flag, no friction. The reviewer's pattern-matching brain sees clean code, passing tests, a coherent commit message (also AI-generated), and approves.
Google's DORA 2024 report found that in their regression model, a 25% increase in AI adoption is associated with a 7.2% decrease in delivery stability. Correlation, not causation. But it's a correlation that makes sense if you accept that faster approval doesn't mean better verification.
Verification debt compounds differently than cognitive debt. Cognitive debt is about understanding. Verification debt is about trust assumptions. Every approved-but-unverified change becomes a node in the dependency graph that the team treats as verified. Future changes build on it. Future reviews reference it. "This follows the same pattern as the payment handler," but nobody actually verified the payment handler. They approved it.
The result is a codebase where the team's confidence in any given module is based on a chain of approvals, each of which may have been shallow. The chain looks solid. The individual links are weak.
Linters don't catch this. CI/CD doesn't catch this. Test coverage doesn't catch this, because the tests themselves may carry the same verification debt. When AI generates both the implementation and the tests, passing tests tell you the code is consistent with itself. They say nothing about whether it's consistent with intent.
Debt three: architectural debt

Architectural debt is the gap between the system's intended design and its actual structure.
The Ox Security "Army of Juniors" report described AI-generated code as "highly functional but systematically lacking in architectural judgment." Systematically lacking is the right phrase. AI doesn't sometimes make bad architectural choices. It doesn't make architectural choices at all. It generates solutions to local problems. Whether those solutions cohere into a system is not its concern.
Concrete example. An AI agent asked to add a caching layer to an API endpoint will produce a working caching layer. It will likely use a reasonable library. The code will be clean. But the agent has no knowledge of the team's caching strategy: that they use Redis for session data and Memcached for query results, that cache invalidation flows through a central event bus, that cache TTLs are managed in a shared config. The agent solves the local problem. It violates the system design. The violation passes code review, because the code itself is correct.
This is the debt that the "code quality" framing misses entirely. A codebase with consistent style and zero linting errors can still have severe architectural drift if the consistency is superficial. The modules look right individually. The system stops making sense as a whole.
Architectural debt compounds geometrically. Each locally correct but globally inconsistent addition makes the next one harder to catch. There are now multiple patterns to follow, and the reviewer has to figure out which one is canonical. Eventually none of them are. There are just patterns.
Why existing tools don't help
Quick inventory of what the standard toolchain catches and what it misses.
Linters and formatters (ESLint, Prettier, Ruff, etc.): Catch style violations and simple code smells. They enforce syntax-level consistency. They're blind to cognitive debt, verification debt, and architectural debt. A perfectly linted codebase can carry all three.
Code review (GitHub PRs, Gerrit, etc.): Theoretically catches all three. In practice, catches fewer and fewer as AI-generated diffs grow in volume and shrink in reviewer comprehension. Code review was designed for human-authored code reviewed by humans who understood the context. That assumption is breaking.
CI/CD pipelines (GitHub Actions, CircleCI, etc.): Catch regressions in behavior. They verify that the code does what the tests say it should do. They don't verify that the tests reflect actual intent, that the architecture is coherent, or that anyone understands the change.
Static analysis (SonarQube, CodeClimate, etc.): Catch complexity, duplication, and known vulnerability patterns. Better than linters for architectural signals, but still operating at the code level. They can tell you a module is complex. They can't tell you it violates the system's design principles.
AI code review tools (CodeRabbit, Sourcery, etc.): A newer category. These tools use LLMs to review diffs. They're genuinely useful for catching bugs and suggesting improvements. But they review code against general best practices, not against a specific system's architectural intent. They're a better reviewer, but they're still reviewing at the wrong level.
None of these tools operate at the level where the new debts accumulate. They all assess code. The debts live above code: in intent, in comprehension, in design.
How each debt type compounds
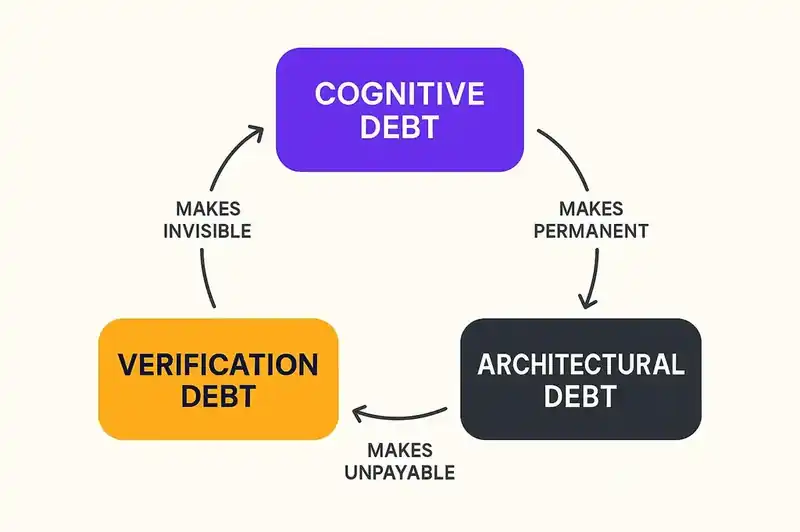
The three debts interact, and the interaction is worse than the sum.
Cognitive debt makes verification debt invisible. When reviewers don't fully understand the codebase, they can't effectively verify new changes against it. They approve based on surface-level correctness because deep verification would require understanding they don't have. Each approval increases the cognitive debt for the next reviewer.
Verification debt makes architectural debt permanent. Unverified changes that violate architectural intent become precedent. Future code, AI-generated and human-authored alike, references them as patterns. The violation becomes the norm. Correcting it later means refactoring not just the original violation but everything that followed its lead.
Architectural debt makes cognitive debt unpayable. When a system's actual architecture diverges from its intended architecture, there is no coherent mental model to build. Engineers trying to understand the system find contradictory patterns, inconsistent abstractions, and design choices that don't trace back to any principle. The cognitive debt can't be paid because there's nothing coherent to learn.
This is the spiral. It spins faster with every AI-generated commit that gets merged without governance at the intent level.
Governance at the intent level
We keep arriving at the same conclusion: you can't govern AI-generated code by inspecting the code. You have to declare and enforce intent before the code is written.
This is not a novel idea. It's how other engineering disciplines already work. A structural engineer doesn't review a building by inspecting individual beams. They review it against the structural design, which exists as a separate artifact. The design constrains the implementation. Inspecting beams without the design tells you the beams are good beams. It doesn't tell you the building will stand.
Software has resisted this for decades because the cost of maintaining separate design artifacts exceeded the benefit. The design documents drifted. The architecture diagrams got stale. The overhead wasn't worth it when humans wrote the code and carried the design in their heads.
That calculus has flipped. When AI writes the code, there is no design in anyone's head. Maintaining explicit, machine-readable intent now costs less than not having it. Kent Beck arrived at this with structured plan files for TDD. Andrej Karpathy arrived at it when he moved from "vibe coding" to "agentic engineering." Simon Willison arrived at it with agentic engineering patterns. Same insight from different directions: agents need persistent specifications to work against.
Detecting each debt type
If you're leading a team that uses AI coding tools, here's what to look for.
Cognitive debt. Pick a module that was primarily AI-generated. Ask the engineer who committed it to explain, without reading the code, why it works the way it does. Not what it does, but why. Why this data structure, why this error handling strategy, why this abstraction boundary. If they can't answer, you have cognitive debt. Scale this by tracking which modules have been modified by someone other than the original committer. Modules that nobody else has successfully modified are likely carrying heavy cognitive debt.
Verification debt. Look at PR review times relative to diff size. If review time hasn't increased proportionally with AI-generated diff volume, your reviews are getting shallower. Look at the ratio of review comments to lines changed. If it's dropping, reviewers are engaging less with each line. Compare how often reviewers request changes on AI-generated PRs versus human-authored PRs. If the rate is significantly lower, it's not because the AI code is better. The reviewer is pattern-matching rather than verifying.
Architectural debt. Map the actual dependency graph of your system and compare it to the intended one. Tools like Madge (JavaScript), deptry (Python), or arch-go (Go) can help. Look for dependencies that shouldn't exist according to your architecture. Count the number of distinct patterns used for the same concern (caching, error handling, data validation, logging). If that number has grown since AI adoption, you have architectural drift. Review the last twenty AI-generated PRs and ask: did any of them introduce a new library, a new pattern, or a new abstraction that wasn't part of the team's existing conventions? Each one is a potential architectural violation.
A name for each debt
Treating AI-generated code as a code quality problem will produce better linters, better static analysis, better AI review tools, and it will miss the actual crisis. Teams are losing comprehension of their own systems, approving changes they have not truly verified, and watching their architectures fragment under locally correct but globally incoherent contributions.
The fix will not come from better code inspection. It will come from better intent declaration: persistent, machine-readable, version-controlled artifacts that describe what a system is supposed to be, so that every change, human or AI, can be evaluated against something more meaningful than syntax and test coverage.
These three debts are accumulating now, in every team using AI tools at scale. The first step to managing them is having a name for them.
Better code inspection will not catch this. We're building the intent declaration that agents reconcile against before the debt accumulates.