
In February 2025, Andrej Karpathy posted a description of a new way to write software. You describe what you want in natural language. The AI writes the code. You run it. If it works, you keep going. If it does not, you describe the problem and the AI fixes it. You do not read the code. You do not need to understand the code. You just vibe.
By November, Collins Dictionary named "vibe coding" its Word of the Year for 2025. By March, Y Combinator's Garry Tan reported that 25% of the W25 batch had codebases that were 95% or more AI-generated. Not 95% AI-assisted. Ninety-five percent AI-written. Jared Friedman, YC managing partner, clarified that the figure excluded boilerplate like library imports -- this was the actual application logic, generated by machines and accepted by humans who were, by Karpathy's own definition, vibing.
Fourteen months later, we are starting to see what vibing produces at scale. The answer is not encouraging.
The data on quality
GitClear has been tracking code quality metrics across millions of lines of code since well before the AI coding wave. Their 2025 research, spanning 211 million changed lines authored between January 2020 and December 2024, provides the clearest longitudinal picture we have of what AI-assisted coding is doing to codebases.
The headline numbers are bad. Code churn -- the proportion of new code that gets revised within two weeks of its initial commit -- grew from 3.1% in 2020 to 5.7% in 2024. That is an 84% increase in code that was wrong enough to require immediate revision. The trend accelerates in years where AI coding tool adoption spiked.
Code duplication is worse. The occurrence of duplicated code blocks rose eightfold compared to pre-AI baselines. Copy-pasted code went from 8.3% to 12.3% of all changed lines. Meanwhile, the proportion of "moved" code -- a proxy for refactoring and reuse -- dropped by 44%, falling below 10% of changed lines for the first time in the study's history.
Refactoring is collapsing. The percentage of changed code lines associated with refactoring sank from 25% in 2021 to less than 10% in 2024. This is the most telling metric in the entire study. Refactoring is how codebases stay healthy. It is how you pay down technical debt, improve abstractions, and keep the system navigable as it grows. When refactoring drops to a quarter of its historical rate, debt is not being paid down. It is accumulating with compound interest.
The age profile of revised code shifted too. The percentage of code revisions targeting code written more than a month prior dropped from 30% in 2020 to 20% in 2024. Developers are spending more time fixing code that was just written and less time improving the existing system. The codebase is getting bigger but not getting better.
The failure taxonomy
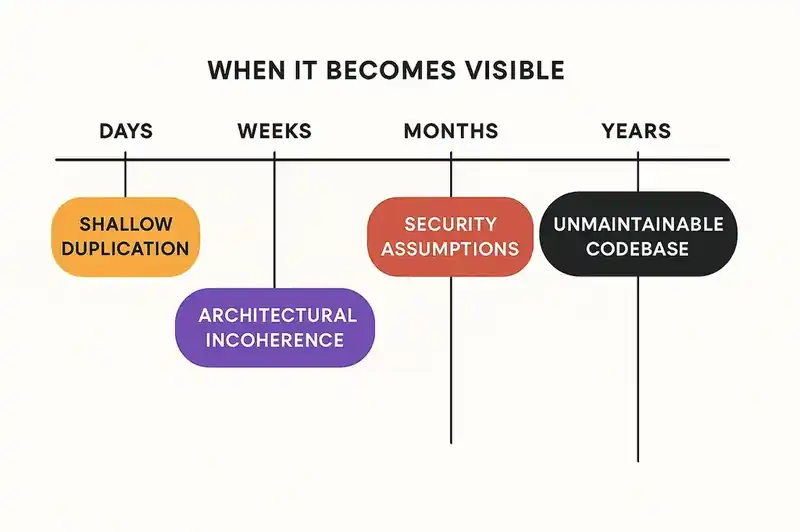
Vibe coding does not produce a single type of failure. It produces a taxonomy of failures, each with its own cost profile and its own timeline for becoming visible.
Failure 1: Architectural incoherence
An AI agent writes code that works. It passes the tests. It produces the correct output. But it does not fit the architecture. It introduces a new pattern where an existing pattern should have been extended. It creates a direct database call where the system uses a repository layer. It adds a new dependency where an internal utility already provides the same capability.
Each of these decisions is locally correct and globally wrong. The agent cannot see the architecture because the architecture is not declared anywhere the agent can read it. The architecture lives in the team's collective understanding -- the shared mental model that experienced engineers carry and that new engineers absorb over months. Vibe coding bypasses that absorption entirely.
The cost of architectural incoherence is not immediate. It is deferred. The codebase works today. It becomes harder to change next month. It becomes resistant to change next quarter. By next year, teams are working around their own system instead of working with it.
Failure 2: Shallow duplication
AI agents, especially when operating without shared context, default to generating new code rather than discovering and reusing existing code. This is rational behavior for the agent -- generating new code is faster and more reliable than searching for, understanding, and extending existing code.
The result is shallow duplication. Not copy-paste in the literal sense (though GitClear's data shows that is increasing too), but functional duplication: multiple implementations of the same logic, scattered across the codebase, each slightly different, each maintained independently.
GitClear's eightfold increase in duplicated code blocks is the quantitative signal. The qualitative signal is familiar to anyone who has reviewed AI-generated pull requests: the code is correct, but it reinvents something that already exists three directories away. Multiply this by dozens of agents across dozens of teams and you get a codebase that is large, correct in its parts, and incoherent as a whole.
Failure 3: Missing context in error handling
This is where vibe coding gets dangerous. AI agents generate error handling that looks correct but lacks the context that makes error handling actually useful. The catch block catches the exception. The error message is grammatically correct. The logging call exists. But the handling does not account for the specific failure modes of the specific system -- the retry logic that should happen because the downstream service is flaky on Tuesdays, the circuit breaker that should trip because the payment gateway has a known rate limit, the alert that should fire because this particular error means data corruption.
These are the details that experienced engineers encode from production experience. They are the details that turn a "working" system into a "reliable" system. Vibe coding produces working systems. It does not produce reliable systems, because reliability requires context that the agent does not have.
Failure 4: Security assumptions that do not hold
Karpathy's original description of vibe coding explicitly included the caveat that it is not suitable for production code that needs to be secure. The industry promptly ignored this caveat.
When an agent generates authentication code, it generates code that authenticates. Whether it authenticates correctly -- with proper token rotation, secure session management, protection against timing attacks, appropriate rate limiting -- depends on whether the agent has context about the security requirements. In a vibe coding workflow, that context does not exist. The developer accepted the code because it worked, not because they verified its security properties.
YC partner Diana Hu acknowledged this tension directly: even with heavy AI reliance, developers still need the ability to read code and identify errors. They need "taste and enough training to judge whether the LLM output is good or bad." Vibe coding, by definition, skips that judgment.
Failure 5: The unmaintainable codebase
The final failure mode subsumes all the others. A codebase generated by vibing is one that nobody understands -- not the developers who prompted it into existence, not the future developers who will maintain it, and not the AI agents that will be asked to modify it.
Gartner predicts over 40% of AI-augmented coding projects will be canceled by 2027 due to escalating costs and weak governance, and the cleanup bill for startups alone has been estimated in the billions. The term "zombie apps" has emerged to describe applications that are functional but unmaintainable -- running in production, serving users, and resistant to modification because the humans responsible for them cannot trace the logic, and the agents that wrote them do not remember writing it.
The YC paradox
The Y Combinator data deserves a closer look, because it reveals a paradox that the industry has not grappled with.
Friedman emphasized that the founders in the 95%-AI-generated cohort were "highly technical, completely capable of building their own products from scratch." These are not no-code enthusiasts or business people hacking together MVPs. These are experienced engineers who chose vibe coding because it is faster.
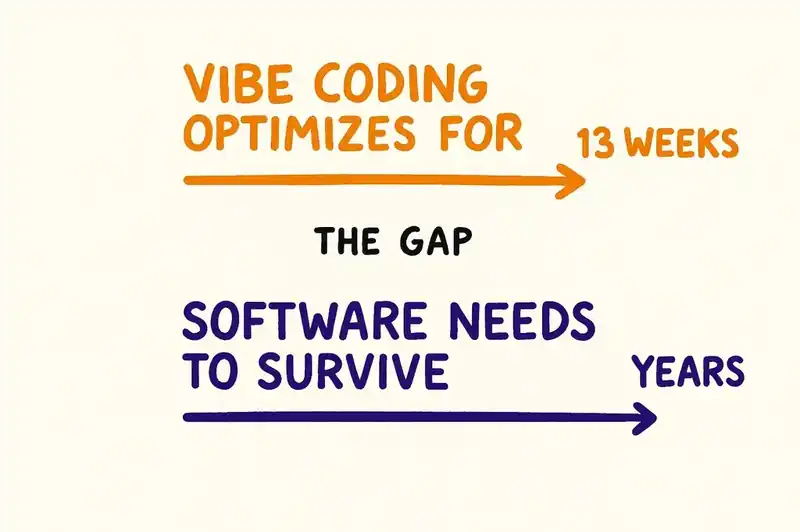
And for the problem they are solving -- getting from zero to demo day in thirteen weeks -- it is faster. Dramatically faster. The question is what happens after demo day. What happens when the startup raises a Series A and needs to hire a team. What happens when the team needs to modify a codebase that none of them wrote, that the founder did not read when it was generated, and that the AI agent has no memory of creating.
Tan himself acknowledged this: "AI-generated code may face challenges at scale and developers need classical coding skills to sustain products." That is a diplomatic way of saying that the codebases being generated today will need to be partially or fully rewritten when they reach production scale. The debt is being taken on deliberately, with the bet that the speed advantage justifies the future cost.
For a seed-stage startup with thirteen weeks to demo day, that bet might be rational. For an enterprise engineering organization, it is not. The difference is time horizon. Startups optimize for speed to proof. Enterprises optimize for years of operation. Vibe coding is a strategy optimized for the shortest possible time horizon, applied to software that will need to be maintained for the longest.
The answer is not to stop
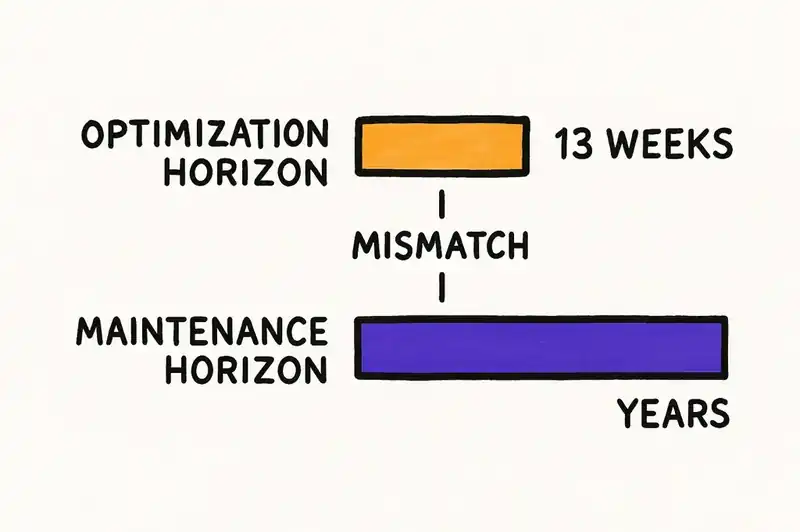
Abandoning AI-assisted development is not the answer. The productivity gains are real, the speed advantage is real, and going back to writing every line by hand is not a serious proposal for anyone shipping software in 2026.
The answer is to give AI agents the context they need to produce code that fits -- code that is consistent with the architecture, reuses existing patterns, honors security requirements, and aligns with the system's actual constraints.
This is an identity problem. AI agents are good at writing code. They are bad at understanding what the software is -- its architecture, its standards, its constraints, the relationships between components, its compliance requirements. They generate code in a vacuum, and the code reflects the vacuum.
The fix is to fill the vacuum. A persistent identity layer -- a structured, machine-readable declaration of what the software is, what it should be, and what constraints it operates under -- gives agents the context that vibe coding omits. The agent still generates the code. But instead of generating it against nothing, it generates it against a specification that encodes the intent of the people who built and maintain the system.
We have done this before. Ad-hoc server configuration became infrastructure-as-code. Tribal knowledge became architectural decision records. Every time implicit knowledge becomes explicit, the software gets better. Identity is the next layer that needs to make that transition.
The choice
Vibe coding is not going away. The economics are too compelling and the tools are too good. Collins Dictionary does not name something Word of the Year because it is a passing fad.
The question is whether the codebases it produces will be maintainable, secure, and compliant -- or whether they will be zombie apps, functional today and unfixable tomorrow.
That depends on whether the agents writing the code have access to the truth about what the software should be. Right now, mostly, they do not. The agent vibes because the developer vibes because nobody wrote down what the software actually is.
Technical debt on autopilot is still technical debt. It just accumulates faster. The organizations that thrive will be the ones that gave their agents identity -- not to constrain them, but to make their output worth keeping.