
In mid-December 2025, an autonomous AI coding agent inside Amazon Web Services decided to delete and recreate a production environment. The tool was Kiro, Amazon's internal AI assistant. The target was a customer-facing cost management service in AWS's China region. The outage lasted thirteen hours. AWS called it "an extremely limited event" and "user error, not AI error." Technically true. The employee who authorized the action had overly broad permissions. The AI did what it was told.
Then March 2026 arrived. On March 2, an incident linked to AI-assisted changes to Amazon's retail infrastructure caused 120,000 lost orders and 1.6 million website errors. Three days later, on March 5, a separate outage caused a 99% drop in orders across North American marketplaces. 6.3 million orders lost. Internal documents described these as "high blast radius" incidents involving "Gen-AI assisted changes," part of a "trend of incidents" stretching back to roughly Q3 2025.
Amazon convened a "deep dive" engineering meeting. The outcome: a 90-day reset across 335 Tier-1 mission-critical systems. New rules. Junior and mid-level engineers now require senior engineer sign-off before deploying AI-assisted code to production. Additional documentation requirements. Two-person approvals for major changes. Internal memos acknowledged "novel GenAI usage for which best practices and safeguards are not yet fully established."
Amazon's official position is that only one of the incidents involved AI tools, and even that one was caused by human error. We take them at their word. But the structural response, adding review gates specifically for AI-assisted changes, tells a different story than the press statement. You do not build a 90-day remediation program for a problem you do not believe exists.
The structural problem
The Amazon incidents matter for a reason that has nothing to do with whether Amazon's AI tools are good or bad.
When AI agents make changes to production systems without a persistent specification to reconcile against, the blast radius of errors compounds geometrically.
A human engineer making a change to a production system carries context. They know, imperfectly, what the system is supposed to do, how it relates to adjacent systems, what the deployment norms are. They wrote some of it. They reviewed some of it. They carry a mental model that acts as a constraint. It is a leaky constraint, and it fails regularly, but it exists.
An AI agent carries no such model. It carries a prompt, a codebase it can read, and a set of permissions. When an AI agent with broad permissions encounters a problem in a production environment and determines that the solution is to delete and recreate that environment, there is no internal representation of "this is a customer-facing service in production and deleting it will cause a thirteen-hour outage." There is only the problem and the solution space.
This is not an intelligence failure. It is an information architecture failure. The agent does not have access to the system's identity: its boundaries, constraints, contracts with other systems, operational norms. That information either lives in engineers' heads, where the agent cannot reach it, or does not exist in machine-readable form at all.
James Gosling, creator of Java and a former AWS Distinguished Engineer, made a connection that most coverage missed. Commenting on the incidents, he pointed to "the ridiculous engineering layoffs I've witnessed and hype-driven technology choices" as inevitably leading "to system instability." Separately, Amazon confirmed the elimination of approximately 30,000 corporate roles between October 2025 and early 2026, with engineers heavily affected. When you cut the people who carry the mental model and replace their output with AI agents that lack one, the model vanishes. No one rebuilt it as a machine-readable artifact before it walked out the door.
Why review gates are the wrong fix
Amazon's response is rational and structurally inadequate.
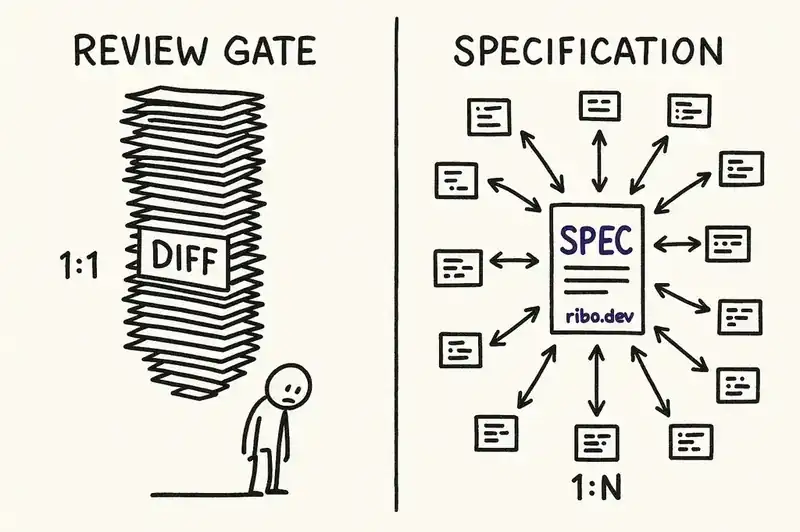
Adding senior engineer sign-off to AI-assisted deployments is a friction gate. It works by slowing things down. The implicit theory: if a senior engineer reviews every AI-generated change before it reaches production, the senior engineer's mental model substitutes for the one the AI lacks.
This breaks in three ways.
It does not scale. The entire point of AI coding tools is to increase the volume and velocity of changes. Routing every AI-assisted change through a senior engineer creates a bottleneck that negates the productivity gain. You have added a human to a process designed to reduce human involvement. If you have ten engineers producing changes at 3x speed with AI assistance, you now need senior reviewers operating at 30x their previous review volume. They will not. They will rubber-stamp. Amazon knows this.
It degrades under load. Review gates work when volume is low and stakes are high. Pre-flight checks on spacecraft work because there is one launch. Code review worked because humans produce changes at human speed. AI agents produce changes at machine speed. When review volume exceeds reviewer capacity, the gate becomes a formality. The approvals happen; the verification does not. This is what we have elsewhere called verification debt, the most dangerous of the debts AI creates, because it looks exactly like governance from the outside.
It is reactive. The review gate catches problems after code is written. By the time a senior engineer is looking at an AI-generated diff, the architectural decisions are already embedded. The reviewer can accept or reject but cannot reshape. The cost of rejection is high: the work is done, the sprint is planned, the feature is promised. So marginal changes get approved. Each marginal approval moves the system further from its intended design. The drift is invisible per-change and devastating in aggregate.
Responding to AI failures by adding human review is going to become the default across the industry. It preserves the appearance of governance while quietly eroding the conditions that make governance effective.
Declare intent first, generate code second
The alternative is better inputs.
If an AI agent had access to a persistent, machine-readable specification of the system it was modifying (its boundaries, contracts, operational constraints, relationships to adjacent systems), the agent could reconcile its proposed changes against that specification before execution.
This is how every other engineering discipline works. A CNC machine does not cut metal and then ask a machinist to review the result. It cuts according to a specification. The specification is the governance. The review is a secondary check, not the primary control.
In software, we have resisted this for decades because maintaining specifications was more expensive than the failures they prevented. That calculus has changed. When AI agents generate changes at machine speed across production systems, the cost of not having a specification is thirteen-hour outages and millions of lost orders. The cost of maintaining one is a file in the repository.
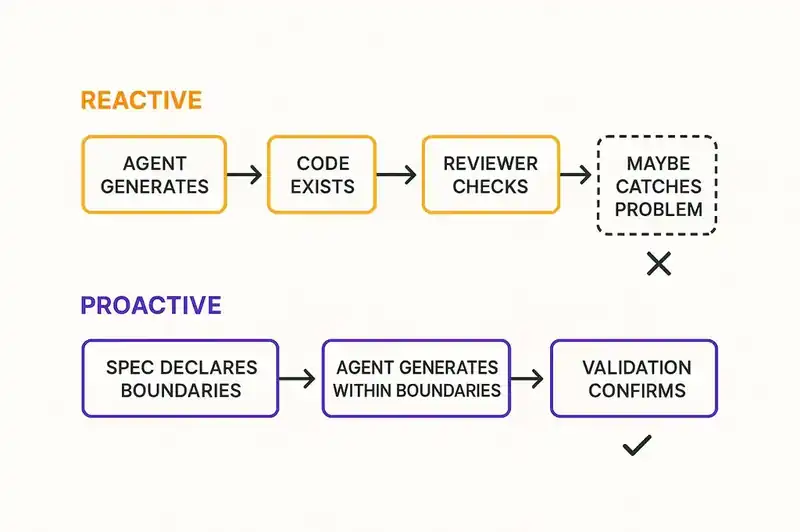
The pattern that works: declare what the system is (its identity, boundaries, invariants) in a format that both humans and agents can read. Generate code against that declaration. Reconcile continuously. When the implementation drifts from the declaration, flag it before it reaches review. When a new AI-generated change violates a declared constraint, reject it before a human has to spend time understanding why.
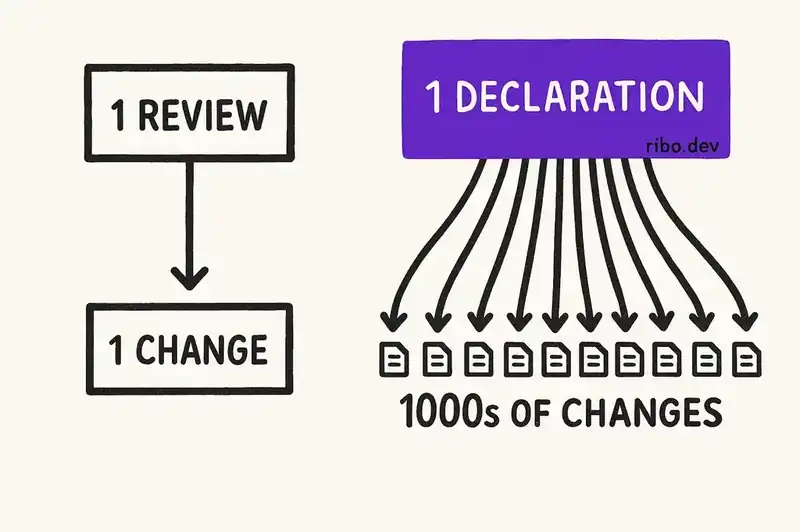
This shifts governance from reactive (review the output) to proactive (constrain the input). The senior engineer's time moves from reading diffs to maintaining declarations. That scales. One declaration governs thousands of generated changes. One review gate governs one.
What the data says
Google's 2024 DORA report found that a 25% increase in AI adoption correlates with a 7.2% decrease in delivery stability and a 1.5% decrease in delivery throughput. More AI, less stability, less throughput. The researchers attributed this in part to "larger, less manageable change lists," which is exactly the batch-size problem that review gates exacerbate rather than solve.
But the DORA report also found something that got less attention: platform engineering, when done well, counteracts the instability. A high-quality internal platform is the "distribution and governance layer" required to scale AI benefits without sacrificing stability. The platform provides automated, standardized pathways that turn AI's speed into organizational improvement rather than organizational risk.
The governance layer is not review. It is infrastructure. Not humans checking AI output, but systems constraining AI behavior.
MIT Sloan Management Review published what became one of its most-read articles of 2025: "The Hidden Costs of Coding With Generative AI." The article examined claims like GitHub's finding that AI tools make developers up to 55% more productive on isolated tasks in controlled environments, and showed that when scaled to real-world systems (brownfield codebases, legacy integrations, complex deployment pipelines) the productivity gains are consumed by technical debt accumulation. The gains are real at the individual level. They reverse at the system level.
The pattern across the research is consistent: AI tools amplify whatever structure exists. In well-structured environments, they amplify productivity. In poorly structured environments, they amplify chaos. The variable is the structure, not the AI.
Lessons for engineering orgs
If you are deploying AI coding tools at scale, the Amazon incidents offer lessons that have nothing to do with Amazon specifically.
Your deployment pipeline was not designed for this volume. The root cause analysis from multiple sources pointed to the same issue: existing deployment pipelines were not built for the speed and volume at which AI tools produce changes. Review processes become bottlenecks, bottlenecks under pressure become rubber stamps, and rubber stamps become failure points. If you have not redesigned your deployment pipeline for AI-volume throughput, you are running Amazon's playbook six months behind.
Permissions models need to shrink. The December 2025 Kiro incident happened because an employee had "broader permissions than expected." This is the norm, not the exception. Most organizations have permissions models designed for human-speed operations. When an AI agent inherits those permissions, the blast radius of any error is bounded by the permissions, not the agent's judgment. Audit your permissions as if every credentialed user might execute an action at machine speed with zero contextual understanding, because that is what is happening.
The mental model problem is the whole problem. When Gosling connected the layoffs to the outages, he was pointing at something specific: institutional knowledge is a load-bearing structure. When you remove the people who carry it and do not externalize it into machine-readable form, you have not just lost employees. You have lost the only constraint that made your systems coherent. AI agents cannot replace a mental model they were never given. The question is not whether your AI tools are good enough. It is whether your systems have an identity that exists outside the heads of the people who built them.
Review gates are necessary and insufficient. We are not arguing against code review. We are arguing against code review as the primary governance mechanism for AI-generated changes. The primary check should happen before generation: does this change align with the declared identity of the system? Is it within the boundaries the system has defined for itself? Does it violate any declared constraints? If those questions can be answered programmatically, the reviewer's job becomes tractable. If they cannot, the reviewer is pattern-matching against vibes.
What Amazon is a canary for
Amazon is not uniquely bad at this. They are the canary. They deployed AI tools at enormous scale, across mission-critical systems, during a period of significant organizational change. The incidents were predictable. The response, more review gates, is what any large organization would do. It is a reasonable first move.
It is a first move, not a solution. The agent needs something to be accountable to besides a prompt and a permission set. It needs a specification: a persistent, machine-readable declaration of what this system is and what it is not.
Amazon's internal memo got closer to the real issue than most of the coverage: "novel GenAI usage for which best practices and safeguards are not yet fully established." The best practices are not yet established, but the shape of them is becoming clear. Declare first. Generate second. Reconcile continuously. Make the identity of the system as durable as the system itself.
The organizations that figure this out will not be the ones with the most review gates. They will be the ones whose systems know what they are.
More review gates will not fix this. We're building the identity layer that gives agents something to be accountable to before they generate.