
If you've been building software for more than fifteen years, you've already pattern-matched this.
Someone describes a layer that sits above the code. A declaration of what the system should be. Tooling that reads the declaration and produces implementation. You nod politely and think: "We tried this. It was called Model Driven Architecture. It didn't work."
You're right to be skeptical. MDA failed. CASE tools failed before it. Executable UML failed alongside it. The graveyard of "declare the system, generate the code" is large enough to have its own Wikipedia category. Anyone selling the next version of that idea owes you a direct explanation of why this time is different.
This is that explanation.
The graveyard, named
The Object Management Group launched Model Driven Architecture in 2001. The promise: define your system in a Platform-Independent Model using UML, then use automated transformations to generate Platform-Specific Models and, ultimately, running code. Write the model once, deploy to any platform. MDA Guide 1.0 shipped in 2003. A revised Guide 2.0 landed in 2014, thirteen years later, to a market that had largely stopped paying attention.
MDA wasn't the first attempt. CASE tools had made the same bet in the 1980s. The U.S. Department of Defense invested millions. The Government Accountability Office's 1993 assessment was blunt: "Little evidence yet exists that CASE tools can improve software quality or productivity." Market penetration peaked around 20%, then declined.
Executable UML, championed by Stephen Mellor, pushed the idea further: build models detailed enough to execute directly. Mellor debated Grady Booch at OOPSLA 1996 on "Translation: Myth or Reality?" The models were technically impressive. They never reached mainstream adoption.
Three decades. Same core idea. Same outcome.
What they actually got wrong
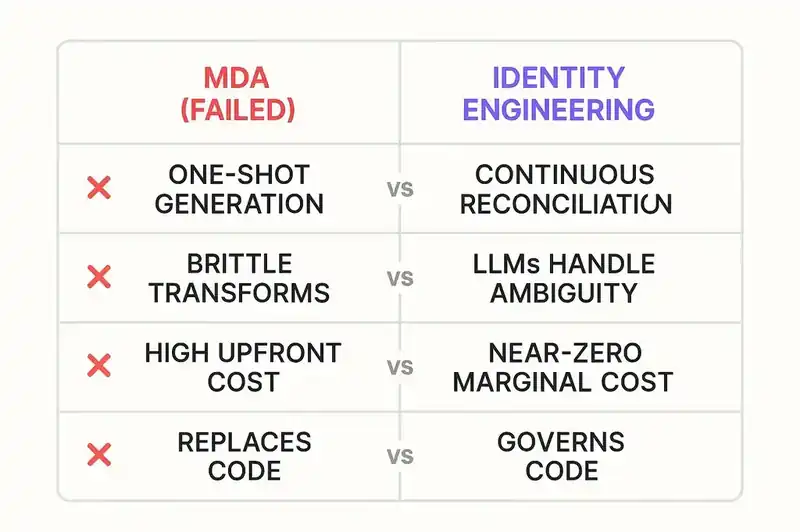
The standard explanation is that these tools were "ahead of their time." That's generous. They had structural problems that no amount of time would fix.
Brittle generation requires perfect specifications. MDA transformations were deterministic. If the Platform-Independent Model was incomplete or ambiguous, the generated code was wrong in precisely corresponding ways. Martin Fowler put it plainly: CASE tools "couldn't come up with a coherent programming environment that would allow people to build general enterprise applications more effectively than the alternatives." Every edge case required explicit specification. Real systems have more edge cases than happy paths.
The abstraction leaked in one direction. When generated code didn't do what you needed, you either tweaked the model until the generator produced the right output (fighting the tool) or edited the generated code directly (breaking the contract with the model). The round-trip engineering problem, keeping models and code synchronized after manual edits, was never solved. Fowler noted that MDA standards addressed schema standardization but "the equally important elements of editors and generators are utterly ignored."
Specialist practitioners, narrow applicability. MDA required fluency in UML metamodels, OCL constraints, and transformation specifications. InfoQ identified the problem directly: "current expert MDA practitioners are scarce relative to the availability of traditional developers." The tools didn't meet developers where they were.
Cost front-loaded, payback deferred. Building the models, configuring the transformations, training the team. All before a single line of useful code was generated. The maintenance savings rarely materialized because the models couldn't keep up with the rate of real-world change.
The platform assumptions became obsolete. CASE tools were architected for client/server computing. MDA assumed stable middleware platforms (EJB, CORBA, .NET) as transformation targets. REST, microservices, and cloud-native architectures moved faster than the modeling standards could follow. By MDA Guide 2.0 in 2014, the platforms it abstracted over had been replaced by platforms it couldn't model.
These aren't incidental failures. They're structural. Understanding them is what separates identity engineering from the pattern that didn't work.
Four structural differences
1. Continuous reconciliation, not one-shot generation
MDA was a one-shot pipeline. Model in, code out. The generated artifact was the end product. If the code drifted from the model, you had a synchronization problem with no automated solution.
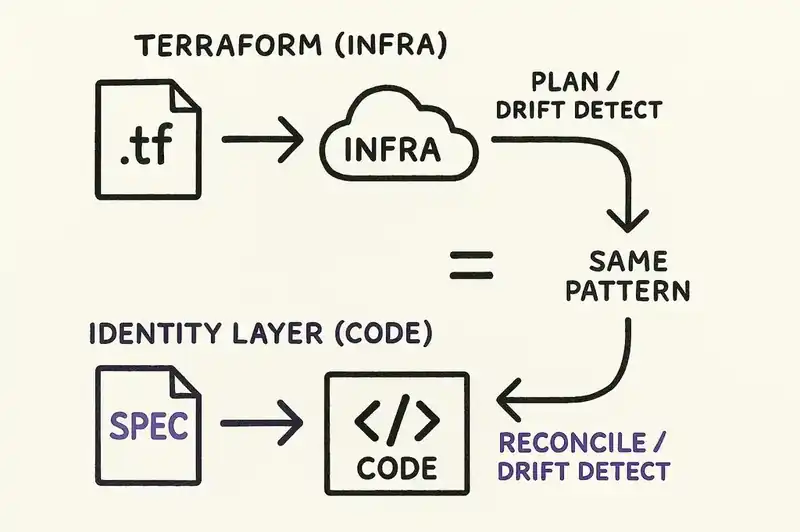
Identity engineering follows the Terraform/Kubernetes pattern: declare desired state, reconcile continuously. The declaration doesn't produce the code once. It governs the code persistently. When the implementation drifts from the declared identity, the reconciliation loop detects the divergence.
Nobody generates a Terraform config, produces infrastructure, and throws away the config. The .tf file is the durable artifact. terraform plan runs before every change. Drift detection runs in CI. The identity layer works the same way for application code. It doesn't generate and walk away. It watches, compares, and reports.
2. LLMs handle ambiguity; code generators couldn't
MDA transformations were deterministic functions mapping formal inputs to formal outputs. If the input was ambiguous, the transformation failed or produced garbage. The specification had to be perfect, with every constraint explicit and every edge case modeled. Writing a specification precise enough to survive deterministic transformation is harder than writing the code.
Large language models handle ambiguity. "Must be idempotent for the same transaction ID" is a natural-language constraint that an LLM can interpret across implementation strategies: database constraints, application-level deduplication, message queue semantics. A deterministic code generator requires you to specify which strategy. An LLM evaluates context and picks one.
LLMs aren't always right. But the failure mode is different in kind. A brittle generator fails catastrophically on ambiguity. An LLM produces a reasonable interpretation that can be validated against the declared intent. The validation loop is where the rigor lives. The generation itself can tolerate imprecision that would have been fatal to MDA.
3. Near-zero marginal cost changes the economics
MDA's economics required heavy upfront investment for deferred returns. Most projects didn't last long enough for the model to pay for itself. The economics killed MDA adoption as surely as the technical limitations did.
The economics of LLM-based generation are inverted. In a Google case study on code migrations, 69% of edits were LLM-generated. Airbnb compressed a 1.5-year test migration into six weeks. The marginal cost of generating code is approaching zero. The expensive part is knowing what to generate: the specification, the identity, the contracts.
This is the forcing function MDA never had. When code generation is expensive, you need a very good reason to add an abstraction layer on top of it. When code generation is nearly free, the abstraction layer is the only thing that matters. The identity declaration isn't overhead on top of cheap code. It's the asset that makes cheap code useful.
4. The identity layer governs code, it doesn't replace it
MDA tried to replace code with models. The vision was that you'd stop writing code entirely and work only at the model level. The model was the program. Code was a compilation artifact, like machine instructions, something humans shouldn't need to read or modify.
That vision was wrong for a reason Fowler identified: the models had to become as detailed as code to be useful, at which point you were just writing code in a worse language.
Identity engineering doesn't try to replace code. The identity layer (the declared purpose, contracts, constraints, and relationships of a system) sits above the code, not instead of it. Developers still write code. Agents still generate code. The code is real, readable, modifiable, testable. What the identity layer adds is governance: a persistent declaration of what the code should be, against which the actual code is continuously validated.
Terraform didn't replace infrastructure. It added a governance layer. You can still SSH into a server and change something by hand. Terraform just notices and tells you. The identity layer does the same for application software. Write code however you want. Generate it with whatever agent you prefer. The layer doesn't care how the code was produced. It cares whether the code satisfies the declared contracts, honors the declared constraints, and serves the declared purpose.
The lesson MDA actually taught us
There's one thing MDA got right, and identity engineering takes it seriously.
The declaration has to be the durable artifact.
MDA was correct that the specification should outlive the implementation. Survive rewrites, platform migrations, team turnover, technology shifts. On this point, MDA was ahead of the industry by twenty years. The current wave of specification-driven tools (AWS Kiro, GitHub Spec Kit, Tessl) all build on the insight MDA had in 2001: the specification is more valuable than the implementation.
Where MDA went wrong was the second half. It assumed the implementation should be auto-generated through deterministic transformation. That made the specification fragile because it had to be perfect, the tooling brittle because it couldn't handle ambiguity, and the economics punishing because the upfront cost was enormous.
The lesson: the declaration has to be the durable artifact, but the implementation can't be mechanically derived from it. It has to be reconciled against it. The declaration says what the system should be. The implementation exists independently, written by humans, generated by agents, evolved over time. The reconciliation loop continuously verifies that the implementation honors the declaration. When it doesn't, the divergence is surfaced, not silently papered over by regeneration.
This is closer to how infrastructure-as-code works, how Kubernetes works, how every successful declarative system works. The declaration is authoritative. The implementation is autonomous. The reconciliation engine connects the two.
What this means in practice
The practical questions are fair.
Does it reduce time to production? When AI agents generate code against declared contracts instead of Jira tickets and Slack threads, first-pass quality goes up. Review time drops because reviewers validate against the spec, not against their memory. Onboarding time drops because new engineers read identity declarations instead of reverse-engineering intent from implementation.
Does it reduce incident rates? Drift between intent and implementation causes a specific class of production incidents: the ones where the code works as written but not as intended. Continuous reconciliation catches that drift before deployment. Fewer surprises in production means fewer pages at 3 AM.
Does it survive the rewrite? When you migrate frameworks, replatform services, or let agents regenerate entire modules, the identity declarations persist unchanged. The new implementation is validated against the same contracts. You know whether the rewrite honors the identity before you ship.
MDA promised these outcomes and couldn't deliver. One-shot generation from perfect models, through brittle transformations, by specialist practitioners, with front-loaded costs. Every structural choice worked against the goal.
Identity engineering is a different architecture. Continuous reconciliation. Ambiguity-tolerant generation. Near-zero marginal cost. Governance, not replacement.
You've seen this movie before. The machinery is different this time.
If you've built systems that survived the MDA era and want to compare notes on what's actually changed, we'd like to hear from you.