
We have spent decades naming the ways software decays. Technical debt. Design debt. Infrastructure debt. Each label gave us a handle on something that was previously just a vague sense of dread -- the feeling that the codebase was getting worse, even though the feature count was going up.
Two new terms showed up within months of each other, coined by people who do not coin things lightly. Both describe something that did not exist three years ago: a growing gap between the code we ship and the code we understand.
Werner Vogels, the CTO of Amazon Web Services, stood on stage at re:Invent 2025 and introduced "verification debt." Addy Osmani, engineering director at Google and former Chrome team lead, published a piece in March 2026 defining "comprehension debt." Two of the most respected voices in software engineering independently decided this problem needed a name. That alone should tell you how serious it is.
It also tells you this is no longer a prediction. It is a measurement.
What verification debt actually means
Vogels was characteristically precise. "You will write less code, because generation is so fast," he said. "You will review more code because understanding it takes time. And when you write code yourself, comprehension comes with the act of creation. When the machine writes it, you have to rebuild that comprehension during review. That is verification debt."
The idea is straightforward. When you write code, you understand it because you built it. When an AI writes code, you have to reconstruct that understanding after the fact. That reconstruction takes time. And when you skip it -- because you are behind schedule, because the tests pass, because the code looks right -- you accumulate debt. Not technical debt. Verification debt: the gap between what you shipped and what you have actually demonstrated to be correct.
The ACM published an analysis in Communications of the ACM, describing verification debt as "unknown risk you are running right now." Not future risk. Current risk. Every line of AI-generated code that reached production without genuine human comprehension is a liability already sitting in your system -- accruing interest as bugs you cannot diagnose, security holes you cannot see, and architectural decisions you cannot explain.
This is not hypothetical. Veracode evaluated AI-generated code across more than 100 large language models and found that 45% of code samples failed security tests, introducing OWASP Top 10 vulnerabilities. Nearly half. Not edge cases -- the kinds of vulnerabilities that make the news when they get exploited.
Comprehension debt: the silent version
Osmani's framing is different but complementary. Where Vogels focuses on the verification step -- the moment you review the code -- Osmani focuses on the cumulative effect of skipping it.
Comprehension debt, as Osmani defines it, is the growing gap between how much code exists in your system and how much of it any human being genuinely understands. It is not about one bad PR. It is about the aggregate effect of hundreds of reviews where the code looked fine and the tests passed and there was another PR in the queue.
The insidious part, Osmani argues, is that comprehension debt breeds false confidence. "Nothing in your current measurement system captures it," he writes. "Velocity metrics look immaculate. DORA metrics hold steady. PR counts are up. Code coverage is green." Everything looks healthy. But the organizational understanding of what the system actually does is eroding, and no dashboard tracks that.
This is what separates comprehension debt from technical debt. Technical debt announces itself. Builds slow down. Dependencies tangle. Developers groan when they open certain files. You can feel it. Comprehension debt stays invisible until something goes wrong -- an incident that nobody can diagnose, an integration that breaks in ways nobody predicted, a refactor that introduces regressions nobody saw coming.
By then, the cost of repayment is enormous. You are not just fixing code. You are rebuilding understanding from scratch.
The numbers are already bad
Sonar's 2026 State of Code Developer Survey provides the empirical backbone for both concepts. They surveyed over 1,100 developers globally and found a trust gap that is hard to overstate.
96% of developers do not fully trust that AI-generated code is functionally correct. Near-universal skepticism.
But only 48% always verify AI-generated code before committing it. Fewer than half.
Put those two numbers together. Almost everyone doubts the output. Fewer than half check it. The gap between those numbers is verification debt, accumulating in real time across every organization that uses AI coding tools.
It gets worse. 38% of developers say that reviewing AI-generated code takes more effort than reviewing code written by their human colleagues. That is a structural disincentive to verify. When verification is harder than the work it is checking, people skip it -- not because they are lazy, but because they are rational actors under time pressure, working in a system that punishes thoroughness.
61% of respondents agreed that AI often produces code that "looks correct but is not reliable." Anyone responsible for production systems should read that twice. Code that looks correct but is not reliable is the worst kind of code. It passes the visual inspection that constitutes most code review. The bugs it contains are subtle, context-dependent, and often invisible until they reach production.
The productivity paradox
None of this would matter if the tools were not useful. But they are. Sonar's survey found that 72% of developers who have tried AI use it every day. AI accounts for 42% of all committed code, a number developers expect to rise to 65% by 2027.
The tools work. They generate code faster than any human can type it. The question is whether we can verify it fast enough to matter.
The ACM's analysis puts this bluntly. There is early evidence that the bottleneck is already shifting from writing to verifying. A randomized controlled trial on experienced open-source developers, conducted by METR and published in July 2025, found that allowing usage of AI tools increased completion time by 19% on average. Not decreased. Increased.
Experienced developers, working on their own repositories -- codebases they knew intimately -- were slower with AI than without it. The reason, as the researchers documented, was that developers accepted less than 44% of AI-generated code, spending significant time reviewing, testing, and modifying output only to reject it. The generation was fast. The verification consumed the savings and then some.
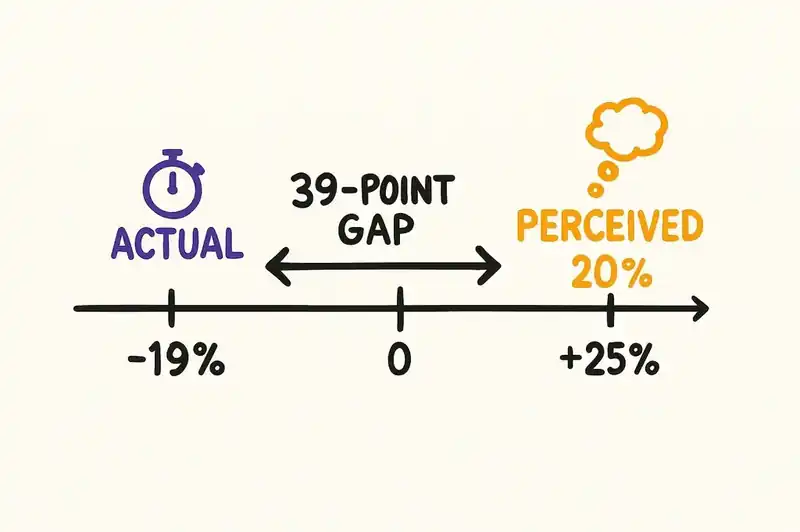
The most striking part of the METR study was the perception gap. Before starting, developers predicted AI would make them 24% faster. Afterward, they estimated it had made them 20% faster. The actual measurement: 19% slower. The tools feel fast. The work takes longer.
Where the debt compounds
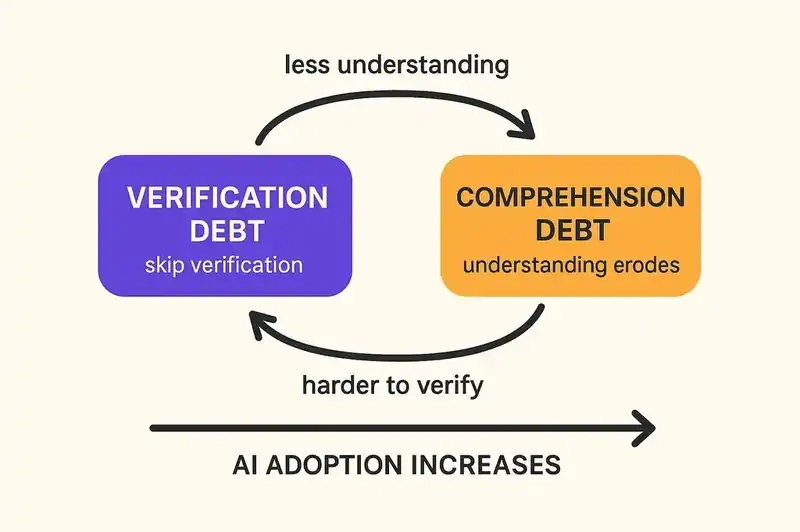
Verification debt and comprehension debt are not parallel concepts. They are compounding ones.
Skip verification, and you reduce your understanding of the code. Reduce your understanding, and your ability to verify new additions drops. That is a feedback loop, and it accelerates as AI adoption increases.
At organizational scale, Sonar's data shows 42% of committed code is now AI-generated. If only 48% of that is always verified, roughly 22% of all committed code enters the codebase without consistent human verification. In an organization committing thousands of lines per week, that is a substantial amount of unverified code accumulating in production systems.
Compound that over quarters. Over years. The comprehension gap widens. New engineers join and inherit a codebase that nobody fully understands. Incidents take longer to resolve because responders lack the mental model of what the system is supposed to do. Refactors become riskier because nobody can predict the downstream effects of changes to code that was never deeply understood in the first place.
This is not the future. This is now. The Sonar survey was published in January 2026. The METR study was published in July 2025. The ACM analysis is current. The debt is already accruing.
The review problem is structural
It is tempting to frame this as a discipline problem. Review more carefully. Enforce stricter gates. Allocate more time.
All true. All insufficient.
The problem is structural. AI generates code at a rate that human review cannot match. Faros AI's 2025 research, based on telemetry from over 10,000 developers, found that teams with high AI adoption see a 91% increase in code review time and a 154% increase in average PR size. That is a doubling of the review burden with a simultaneous increase in the complexity of each review.
You cannot solve a 154% increase in PR size with "review more carefully." You need a different model of what review means.
The current model assumes that the reviewer can read the code and understand it in context. That held when code was written by humans who could explain their decisions, when PRs were a manageable size, and when reviewers had a mental model of the system being modified. All three assumptions are breaking down at the same time.
When a human writes code, the reviewer can ask: "Why did you do it this way?" The answer provides context, reveals intent, surfaces trade-offs. When AI writes code, there is no one to ask. The code just exists, and the reviewer has to reconstruct the reasoning from the output alone. That reconstruction is the expensive part, and it is the part that gets skipped under time pressure.
What verification actually requires
Vogels, in his re:Invent keynote, was not just naming the problem. He was pointing toward a solution. He emphasized specifications -- documents that reduce the ambiguity of natural language before AI generates code -- and demonstrated an IDE built around spec-driven development, automated reasoning, testing pipelines, and human code review.
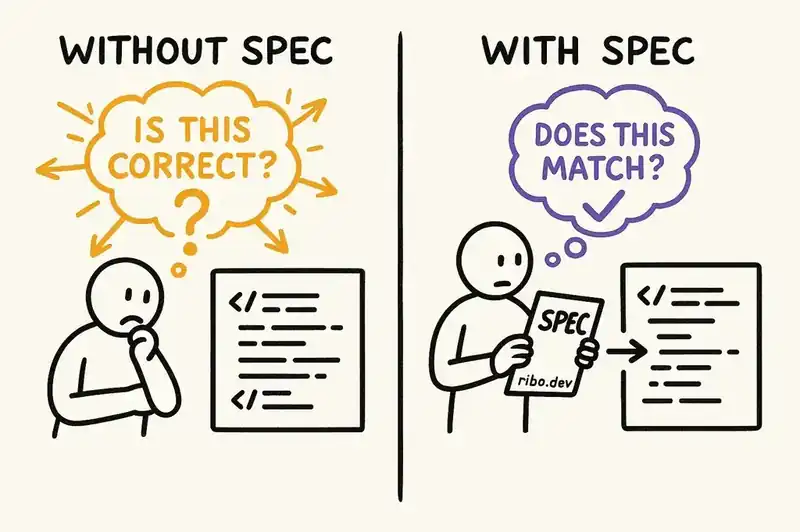
The logic is straightforward. If you want to verify AI-generated code, you need something to verify it against. A spec defines what the code should do, what constraints it should respect, and what behaviors are out of scope. With a spec, verification changes from an open-ended question ("Is this code correct?") to a closed one ("Does this code match the spec?"). The second question is far cheaper to answer.
The ACM's analysis reinforces this. They describe a promising paradigm of automated, proof-oriented programming in which LLMs generate code together with formal specifications in verifiable languages. The code is then automatically verified against those specifications, providing a level of trust that testing alone cannot achieve.
This is the direction the industry is moving, not because specifications are trendy, but because the alternative -- manually rebuilding comprehension for every AI-generated PR -- does not scale.
The naming matters
There is a reason Vogels and Osmani bothered to coin these terms. You cannot measure a problem you cannot name, and you cannot manage what you do not measure.
Before we had the term "technical debt," we had the vague feeling that the codebase was getting worse. Ward Cunningham gave us the word, and with the word came frameworks for tracking it, budgets for paying it down, and organizational conversations about acceptable levels of accumulation.
Verification debt and comprehension debt need the same treatment. They need to become line items in sprint planning. They need metrics -- not perfect ones, but directional ones. They need organizational acknowledgment that the gap between generation and understanding is real, it is growing, and it has a cost that compounds over time.
96% of developers do not fully trust AI-generated code. Only 48% always verify it. 38% say verification takes longer than reviewing human-written code. 61% say AI produces code that looks correct but is not reliable.
Those numbers are not a warning. They are a diagnosis.
The debt is already on the books. The only question is whether we start paying it down now or wait until the next incident forces us to confront how much of our production code nobody actually understands.