
On April 4, 2026, Andrej Karpathy posted a gist called "llm-wiki" describing a pattern for an LLM agent that reads sources and maintains a personal wiki in Obsidian. Within days, Nate B. Jones was publicly comparing the approach to his own project, Open Brain, a Postgres-backed personal memory system accessible through MCP. Both projects are doing something useful. The fork they are making visible is the interesting part.
They are working on a question every agentic system eventually hits. When should the AI do the hard thinking: at the moment information arrives, or at the moment someone asks for it?
The fork, and why it matters
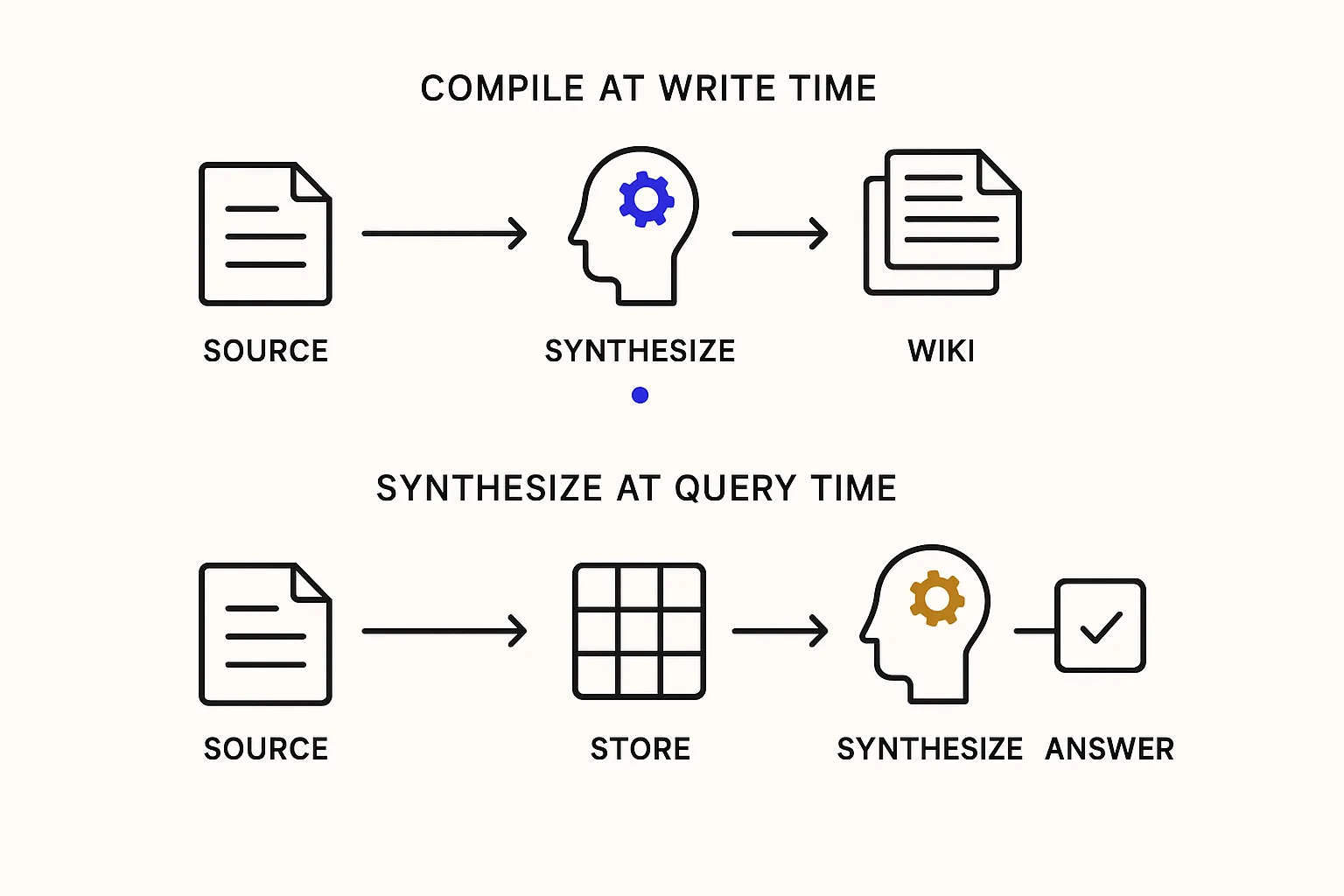
Karpathy's wiki puts the thinking at write time. "The knowledge is compiled once and then kept current, not re-derived on every query." The agent reads incoming sources, synthesizes what it learned into markdown pages, and stores the result as a browsable artifact. In his phrasing: "Obsidian is the IDE; the LLM is the programmer; the wiki is the codebase."
Open Brain puts the thinking at query time. Incoming facts land in a structured Postgres database, tagged and indexed. Any tool can query through MCP: Claude, ChatGPT, Cursor, a scheduled automation. The data never drifts from what was actually put in. Synthesis happens fresh against structured rows every time a question arrives.
Jones frames the tradeoffs with the clarity of someone who has lived on both sides:
- Wiki memory works beautifully up to around 10,000 high-signal documents. Past that it struggles. Database memory scales past the threshold.
- Wiki memory assumes one writer. A folder of markdown with two agents editing the same page creates conflict. Databases handle simultaneous writes by design.
- Wiki memory smooths contradictions. If engineering says a build will take twelve weeks and sales promised eight, the next synthesis quietly resolves it to ten. Databases preserve both rows, and visible contradictions are often the most valuable signal in the system.
- Wiki staleness reads confidently, like well-written prose that happens to be wrong. Database staleness looks like a gap the next query can surface.
Jones's own landing point is the right one: run both. The database is the source of truth, and the wiki is a compiled view generated from it on demand. That resolves the false choice.
The same fork, one layer upstream
We have been working on the same fork at a different altitude. Not personal memory. The identity of the software itself.
Your codebase is a knowledge base. Every agent that reads it is running one of the two patterns above, whether the team chose deliberately or not.
For most teams today, agents compile on every query. The agent reads the repo, skims READMEs, greps for nearby examples, opens a few tests, and synthesizes a working model of what the software is supposed to do. Fresh, every time. That synthesis never gets written down. The next agent starts over. The scanner in CI starts over. Nothing compounds.
This is the wiki approach applied to code, minus the wiki. Some teams close the gap with wiki-like artifacts: AGENTS.md, CLAUDE.md, PRDs in markdown, an architecture doc refreshed by whichever engineer last cared. These are prose synthesis, the wiki pattern retrofitted onto software. They help for a while. They hit the same ceilings Jones names: past 10,000 files, with multiple agents, when intent changes faster than anyone writes paragraphs.
Research bears this out. In February 2026, ETH Zurich researchers published Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents? (Gloaguen, Mündler, Müller, Raychev, Vechev). Across 138 repositories and thousands of agent runs, LLM-generated context files reduced task success rates versus providing no context file at all, and raised inference costs by over 20%. The promise was "compiled once, kept current." What teams measured was compiled once, quietly drifted, then confidently rebuilt from scratch anyway.
What the fork looks like for software
The dimensions Jones names map onto software identity almost without translation.
Scale. A production codebase crosses the high end of the wiki zone before the first deploy. Prose synthesis does not scale past the point where any one human could read all of it. That point, not coincidentally, is where agents became necessary in the first place.
Multi-agent writes. A platform team today runs a PR reviewer, a test generator, a compliance scanner, a dependency updater, an incident responder, and whatever the next vendor ships. All of them need to read the same source of truth. Some need to contribute back. Prose maintained by one agent cannot hold up. A structured, versioned, query-shaped declaration can.
Contradiction preservation. A wiki paragraph that asserts "the service supports idempotent retries" is useful until the implementation diverges and the paragraph doesn't. The prose still reads confidently. A structured declaration that names idempotent-retry as an invariant and is validated in CI fails the build the moment the implementation drifts. The contradiction does not smooth. It fires, which is what you want from a load-bearing claim about a production system.
Provenance. In a structured declaration, every fact traces to a source and a version. In a prose synthesis, the agent that wrote it is the source. For personal knowledge that is a philosophical preference. For software shipped to customers under a compliance regime, it is the difference between an audit trail and a memoir.
What we have been building
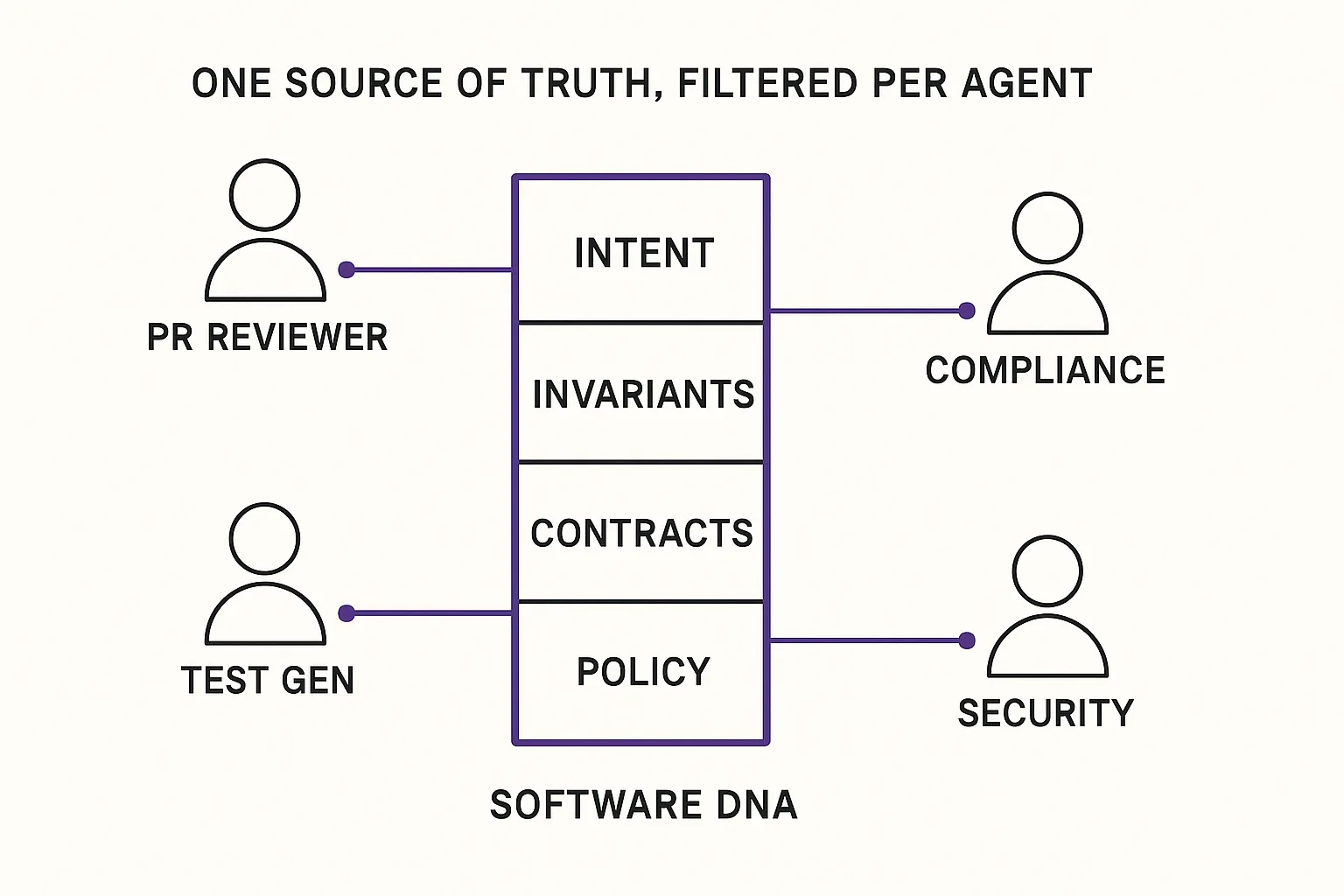
We think of this layer as Software DNA: a machine-readable, version-controlled declaration of what each service is, what it guarantees, what it forbids, and where its boundaries sit. Not a replacement for code. A layer above it that agents query, CI validates against, and auditors can read.
The architecture we have landed on agrees with Jones on the shape of the answer. The structured declaration is the source of truth. Prose views can be compiled from it on demand for humans who want to browse. Per-agent projections (a test generator sees contracts and invariants; a compliance scanner sees policy declarations; a security scanner sees threat models) let multiple tools read the same source of truth through filtered lenses without stepping on each other.
The hard parts are the same hard parts Karpathy names for personal wikis, one layer up. Bootstrapping: what to declare first, at what granularity, in a form that actually changes how agents behave. Authority: who gets to revise a declaration, and under what review. Migration: how to introduce a DNA layer into a production system that has been running on inferred intent for years. These are real engineering questions, and every team that adopts the pattern works through them in public.
Karpathy's gist echoes a conviction already well articulated in Steph Ango's 2023 "File Over App" essay: the artifacts that matter outlive any single tool, and ownership of them is non-negotiable. We think that principle extends up the stack. The declaration of what your software is belongs in your repository, in a format your agents can read today and the next generation of agents can still read after the current tooling is retired.
Come work on this with us
Karpathy's wiki is the right shape of answer for personal research. Jones's Open Brain is the right shape for personal knowledge at scale with multi-tool access. Software DNA is the shape we think the same question takes when the subject is a production codebase with non-human agents writing against it every day.
The hardest problems at this layer (contradiction preservation across writers, multi-agent write semantics under MCP, provenance when the corpus is generated faster than it is read) want to be solved once, at the right altitude, and then shared. If you are working on any of them at any scope, we want to hear how you are thinking about them.
Your agents are going to keep rediscovering your codebase until there is a layer below the code to read from. We are building that layer. Come build it with us.
We are building the identity layer for software. If you are working on the same problem at any scope, tell us what you are seeing.