
Your developer asks an AI coding assistant to help build a feature. The AI suggests importing a package -- let us call it flask-security-utils. The name is plausible. It sounds like it should exist. The developer runs pip install flask-security-utils and moves on with their day.
The package installs cleanly. It does not throw errors. It even appears to provide the functions the AI said it would.
There is one problem: flask-security-utils did not exist six months ago. The AI hallucinated the name -- it invented a package that sounded right based on patterns in its training data. And between the time the AI started recommending that name and the time your developer installed it, someone registered it on PyPI. Not the Flask team. Not the security community. An attacker who understood that AI models hallucinate the same fake package names repeatedly and predictably.
Your developer just installed malware, willingly, on the AI's recommendation.
This is not hypothetical. It has a name now: slopsquatting.
What slopsquatting is and why it works
The term was coined by Seth Larson, the Python Software Foundation's Security Developer-in-Residence, as a variation on typosquatting -- the decades-old attack where malicious actors register package names that are common misspellings of popular libraries (e.g., reqeusts instead of requests). Typosquatting relies on human error. Slopsquatting relies on machine error. Specifically, it relies on the tendency of large language models to confidently recommend packages that do not exist.
The attack works in three steps. AI models hallucinate package names. Attackers register those names on public registries like npm and PyPI. Developers install them, either directly on the AI's recommendation or because the hallucinated name appears in AI-generated code that gets committed and deployed.
What makes slopsquatting different from typosquatting is scale and predictability. A human typo is random -- you cannot predict which letters a developer will transpose. AI hallucinations are systematic. The same model, given similar prompts, will repeatedly hallucinate the same nonexistent package names. The hallucinated names are not just discoverable but reliable targets. An attacker does not need to guess which fake names developers might type. They just need to ask the AI what packages it recommends and register the ones that do not exist.
The research: 20% of recommended packages are fake
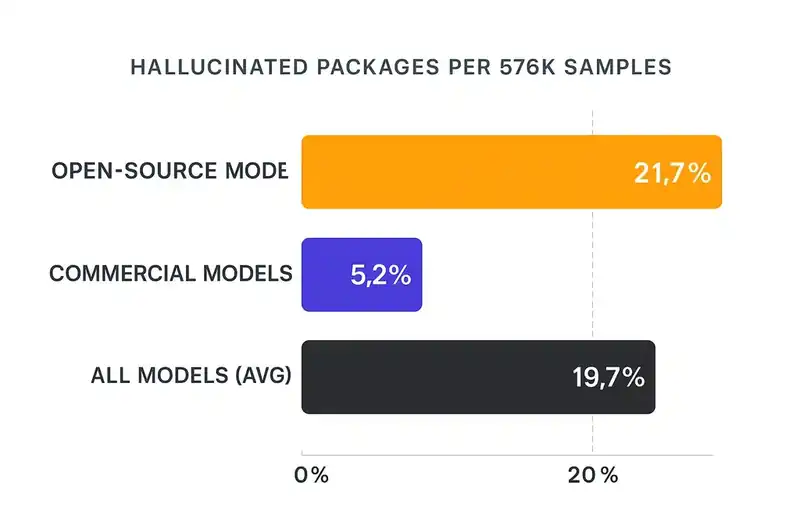
A research team from the University of Texas at San Antonio, Virginia Tech, and the University of Oklahoma published the most comprehensive study on this in early 2025. They generated 576,000 code samples across 16 code-generation models -- GPT-4, GPT-3.5, Claude, CodeLlama, DeepSeek, WizardCoder, Mistral, and others -- then checked whether the recommended packages actually existed.
19.7% of all recommended packages were hallucinated. Roughly one in five. Across 576,000 samples, that is approximately 205,000 references to packages that do not exist.
The hallucination rate varied by model. Open-source models like DeepSeek and WizardCoder hallucinated at an average rate of 21.7%. Commercial models like GPT-4 were better but not immune, hallucinating at approximately 5.2%. No model tested achieved a zero hallucination rate. Every single one recommended packages that did not exist.
What turns this from a nuisance into an attack vector: the hallucinations are persistent. When a model hallucinates a package name, it tends to hallucinate the same name again on similar prompts. An attacker can identify hallucinated names through systematic querying, register them, and wait. The AI will keep sending developers to the trap.
The anatomy of an attack
Here is what a slopsquatting attack looks like from the attacker's side.
The attacker queries multiple AI models with common coding prompts. "How do I implement JWT authentication in Python?" "How do I set up WebSocket handling in Node.js?" "How do I parse XML with validation in Go?" For each prompt, they collect the recommended packages and check whether they exist on the relevant registry.
The nonexistent ones go on a list. The attacker runs the same prompts multiple times, with slight variations, to identify which hallucinated names are stable -- which ones the model returns consistently rather than randomly.
Then they register those names. On npm, anyone can publish a package with any unclaimed name. On PyPI, the same. There is no verification that a package does what its name implies, or that the publisher has any relationship to the project the name suggests.
The registered package contains malicious code. It might exfiltrate environment variables (API keys, database credentials, cloud access tokens). It might establish a reverse shell or install a cryptocurrency miner. It might do nothing immediately and instead wait for a specific trigger, making it harder to detect during initial testing.
From the outside, the package looks legitimate enough. It has a name that sounds like a real utility, a README that describes plausible functionality, maybe even some working functions to avoid immediate suspicion. The malicious payload is hidden in the installation script, in an obfuscated module, or in a function that only executes under specific conditions.
The developer installs it. The tests pass -- the malicious code is not in the code path the tests exercise. The code review does not catch it -- the import statement looks reasonable and nobody verifies every dependency against the registry. The code ships to production.
The Claude Code incident: a real-world demonstration
In March 2026, a different kind of supply chain incident demonstrated just how quickly the ecosystem can be exploited. Anthropic accidentally exposed the full source code of Claude Code through a source map file bundled in the public npm package @anthropic-ai/claude-code version 2.1.88. The leak revealed approximately 512,000 lines of TypeScript across nearly 2,000 files.
The leak itself was a packaging error, not a security breach. But what happened next is the part that matters for slopsquatting.
Within hours, attackers began registering npm packages that mimicked the internal package names exposed in the leaked source code. They set up typosquatted and dependency-confused versions of Claude Code's internal dependencies, targeting developers who might try to compile or inspect the leaked source. BleepingComputer reported that at least one campaign used the leak to distribute the Vidar infostealer through GitHub repositories disguised as Claude Code rebuilds.
This was not slopsquatting per se -- it was dependency confusion and typosquatting exploiting a specific incident. But it demonstrates how fast attackers move when new package names enter the ecosystem. Every new name -- whether hallucinated by an AI or exposed by an accidental leak -- is potential ammunition.
Why existing defenses do not help
The traditional defenses against supply chain attacks were designed for a different threat model.
Lockfiles protect against version drift but not against installing the wrong package in the first place. If a developer adds a hallucinated package to requirements.txt or package.json, the lockfile faithfully records the malicious version.
Code review catches many things but rarely catches bad dependencies. Reviewers focus on the logic of the code, not on verifying that every imported package is legitimate. An import statement like from flask_security_utils import token_validator looks reasonable in a PR. Nobody opens a browser to check whether flask-security-utils is a real project maintained by real people.
Vulnerability scanners check known packages for known vulnerabilities. A freshly registered malicious package has no CVEs, no known vulnerabilities, no history at all. It is invisible to scanners because it is too new to have been analyzed.
Package signing helps if you only install signed packages, but the vast majority of packages on npm and PyPI are unsigned. Requiring signatures would break most workflows.
None of these defenses verify that a package should be a dependency of your project. They verify properties of packages you have already decided to install. The decision to install -- the moment the AI recommends a package and the developer runs pip install -- is unguarded.
The scale of exposure
AI accounts for 42% of all committed code, according to Sonar's 2026 survey. That code includes import statements. Those import statements include package names. If 19.7% of AI-recommended packages are hallucinated, and some fraction of those hallucinated names have been registered by attackers, the surface area is enormous and growing.
In practice, a developer asks the AI for help. The AI generates a code block that includes an import. The developer copies it into their editor. Maybe they notice the import. Maybe they do not. Even if they notice it, the package name sounds plausible. They install it. It works -- the malicious package was designed to appear functional.
In a vibe coding workflow, where the developer is moving fast and trusting the AI to handle implementation details, the probability of verifying each dependency drops further. The whole point of AI-assisted coding is to move faster. Verifying every package name against the registry is the opposite of moving faster.
Trend Micro's analysis emphasizes this point: "Slopsquatting is particularly dangerous in AI-agent scenarios where code generation and execution happen with minimal human oversight." When AI agents are writing code, installing dependencies, and running builds in automated pipelines, there may be no human in the loop at all to question whether a package is legitimate.
The dependency allowlist as defense
The defense against slopsquatting is not better AI. Training models to hallucinate less would help, but the defense is structural: a mechanism that prevents unapproved packages from being installed in the first place.
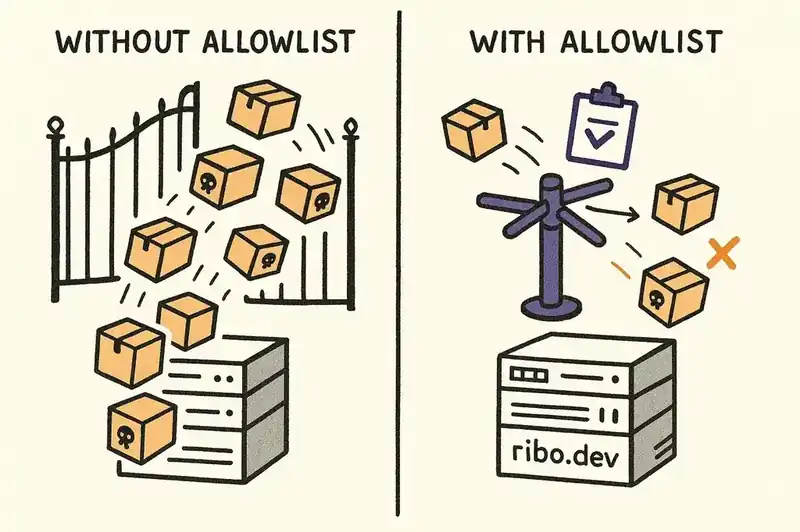
A dependency allowlist -- an explicit, maintained list of packages approved for use in a project or organization. Any package not on the list gets rejected before it can be installed, regardless of who or what recommended it.
The idea is not new. Enterprise software organizations have maintained approved dependency lists for years, mostly for compliance and licensing. What is new is the urgency. When the primary source of new dependency recommendations is an AI that hallucinates 20% of the time, the allowlist shifts from a compliance nicety to a security necessity.
An effective allowlist is not a static document. It is encoded in the project's configuration, enforced in the CI/CD pipeline, and updated through a deliberate process that requires human approval. When a developer or an AI agent attempts to add a new dependency, the system checks it against the allowlist. If the package is not approved, the build fails.
This changes the failure mode. Without an allowlist, the default is to install whatever the AI recommends. With an allowlist, the default is to reject anything not explicitly approved. The burden of proof shifts from "prove this package is malicious" to "prove this package is necessary and legitimate."
The broader supply chain picture
Slopsquatting is one attack vector in a supply chain that is becoming more fragile as AI adoption increases.
AI generates code that includes dependency recommendations based on pattern matching, not security analysis. Developers install those dependencies without systematic verification. Attackers register hallucinated package names with malicious payloads. The malicious code enters the CI/CD pipeline, passes automated checks that were not designed to detect it, and reaches production.
Each step in that chain is individually rational. The AI recommends what looks like the right package. The developer trusts the recommendation. The attacker registers a name that nobody is using. The CI/CD pipeline installs whatever is in the dependency file. Nobody is making a mistake. The system is working as designed. The design just is not equipped for a world where 20% of AI-recommended packages do not exist.
This is a systems problem. It requires a structural mechanism that defines what belongs in your software and enforces that definition at the point where dependencies enter the system.
The alternative is to hope that your developers can tell the difference between real packages and traps, every single time. They cannot. The research says 20% of the time, neither can the AI.
What this means going forward
The supply chain attack surface is changing shape. For twenty years, the primary risks were known: compromised maintainer accounts, malicious updates to existing packages, typosquatted names targeting human error. These are well-understood and at least partially defended.
Slopsquatting exploits a behavior that did not exist before AI coding tools: the systematic, repeatable recommendation of nonexistent packages by systems that developers trust. It turns the AI's confidence -- the same confidence that makes it useful -- into an attack vector.
The 576,000-sample study showed a 19.7% hallucination rate across models. That rate will improve as models get better. But it does not need to reach zero for slopsquatting to be viable. Even a 1% hallucination rate, multiplied across millions of developers generating code daily, produces a steady stream of hallucinated package names for attackers to exploit.
The defense is not vigilance. The defense is structure. Approved dependency lists, enforced at the pipeline level, updated through deliberate human processes. If a package is not on the list, it does not get installed.
The AI can recommend whatever it wants. Your system decides what actually gets in.