Somewhere in your codebase, there's a function your AI assistant wrote three weeks ago. It handles authentication token rotation. It works. The code review passed. The tests pass. Nobody flagged anything.
The function is derived from a GPL-licensed library. Your AI assistant consumed that library during training, internalized its patterns, and reproduced a structurally similar implementation without any of the license annotations the GPL requires. You now have copyleft code in your proprietary codebase. No license header. No attribution. No indication it was ever there.
Under the GPL, the presence of that code in your proprietary product triggers a licensing obligation. If you distribute the product, you are required to release the corresponding source code under the GPL. You haven't done that. You don't know you need to. Your AI assistant didn't tell you, because it doesn't know either.
This is happening at scale, across the industry, right now.
The numbers
The 2026 Open Source Security and Risk Analysis (OSSRA) report, published by Black Duck in February 2026, analyzed 947 commercial codebases across 17 industries.
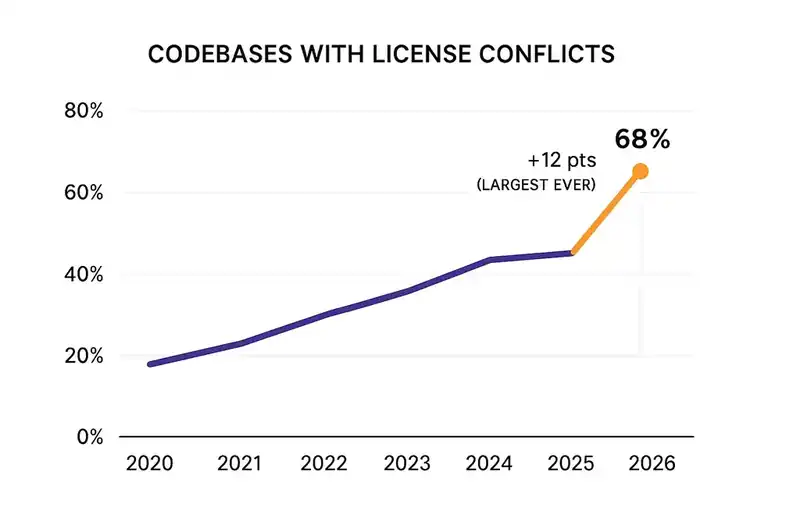
Two-thirds of audited codebases -- 68% -- contained open source license conflicts. That is the highest percentage in the report's history. The jump from 56% to 68% is the largest single-year increase the study has ever recorded. One codebase contained 2,675 distinct licensing conflicts. Not 2,675 open source components -- 2,675 individual conflicts, each a potential legal exposure.
The report identified a specific driver: AI-assisted code generation. When AI tools generate code, they draw on training data that includes millions of open source repositories. The output often reproduces patterns and implementations derived from copyleft-licensed code, but the AI strips the license information. The developer receives clean, unlabeled code that looks like original work. It isn't.
Black Duck found that 17% of open source components now enter codebases outside of traditional package managers -- through copy-and-pasted snippets, direct vendor inclusions, or AI generation. These components bypass conventional software composition analysis (SCA) tools. The code arrives without metadata. It arrives without provenance.
Only 54% of organizations evaluate AI-generated code for intellectual property and licensing risks. Nearly half of all organizations using AI coding tools are accepting generated code with no process for determining whether it carries license obligations.
How license laundering works
The term "license laundering" describes what happens when an AI system consumes copyleft-licensed code during training and produces functionally equivalent code without the license terms attached.
An AI model trains on publicly available code, which includes vast quantities of GPL, LGPL, AGPL, and MPL-licensed repositories. The model learns patterns, algorithms, data structures, and implementation approaches. When a developer prompts it to generate, say, an authentication flow, the model may produce output substantially similar to copyleft-licensed training data.
The problem: the AI generates the code but not the license. The GPL header that accompanied the original implementation doesn't transfer. The copyright notice doesn't transfer. The obligation to distribute source code under the same license doesn't transfer. What transfers is the copyrightable expression -- the part that actually triggers the license obligation.
This creates a paradox. The U.S. Copyright Office's January 2025 report on AI-generated content concluded that "mere prompting" is insufficient for authorship. If AI-generated code cannot be independently copyrighted by the developer using it, then open source licenses -- which depend on copyright for their enforcement mechanism -- may not attach to the output the same way they attach to human-written code. But that's a question about the developer's rights to the output. The question about the original author's rights to the input -- the copyleft-licensed training data -- remains open.
The legal uncertainty is not a defense. It's a risk multiplier. An organization with GPL-derived code in its proprietary codebase is exposed regardless of whether courts eventually find that AI-generated code constitutes a derivative work. The question is unresolved and the downside is severe.
Doe v. GitHub and the legal landscape
The legal system is working through these questions. The answers so far are not reassuring.
Doe v. GitHub, Inc. -- the class action filed in November 2022 against GitHub, Microsoft, and OpenAI -- alleges that Copilot's training on billions of lines of publicly available code violates the Digital Millennium Copyright Act, breaches open source licenses, and unlawfully monetizes developers' intellectual property. The plaintiffs estimate that statutory damages for DMCA violations alone could exceed $9 billion.
In May 2023, the U.S. District Court for the Northern District of California dismissed the copyright infringement claims due to lack of specific examples of copied code, but allowed breach of contract and DMCA violation claims to proceed. The case moved to the Ninth Circuit Court of Appeals in September 2024 on an interlocutory appeal concerning the DMCA's identicality requirement.
The case hasn't produced a definitive ruling on whether AI-generated code constitutes a derivative work. But it has established that the question is justiciable -- courts are willing to hear it -- and that the potential damages are enormous. For an organization shipping proprietary software that contains AI-generated code of unknown provenance, the prudent assumption is that some of it carries unmet license obligations.
The compliance landscape is tightening independently of the litigation. The EU AI Act's transparency requirements, enforceable from August 2026, will require organizations to disclose AI involvement in certain outputs. The combination of mandatory AI disclosure and unresolved license obligations creates an uncomfortable situation: you may soon be required to disclose that your code was AI-generated while being unable to certify it is free of license conflicts.
The detection gap
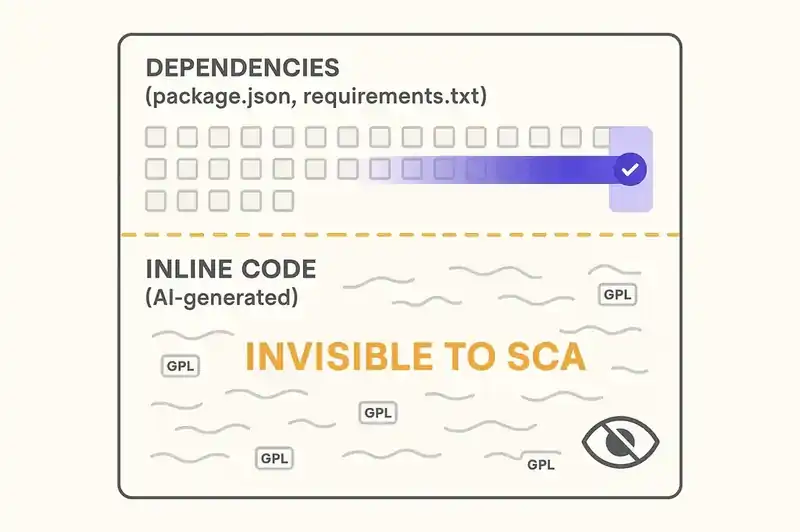
Traditional software composition analysis works by matching code against known open source packages. You import a library, the SCA tool identifies it, checks its license, flags conflicts. This works for explicitly imported dependencies.
It does not work for AI-generated code.
When an AI assistant generates a function derived from a GPL-licensed implementation, the output isn't an import. It's not a dependency. It's inline code in your repository that looks like it was written by someone on your team. No import statement. No package manifest entry. No metadata trail. SCA tools that scan dependency trees will never find it.
Some AI-generated code is similar enough to its training data that snippet-level analysis could detect the derivation. Tools like SCANOSS, FOSSA, and Black Duck's own scanning capabilities can do this. But snippet-level scanning against the entire corpus of open source code is computationally expensive, produces false positives, and only works when the derived code is similar enough to trigger a match. An AI that has internalized a pattern and reproduced it with different variable names, different formatting, and minor structural variations may produce output that is functionally equivalent to GPL-licensed code but different enough to evade snippet detection.
This is the detection gap. The derivation is real. The license obligation is real. The technical mechanisms for detecting the derivation at scale are inadequate.
The arXiv paper on DevLicOps -- a framework for mitigating licensing risks in AI-generated code -- proposes integrating license compliance checks into all phases of the development lifecycle where AI coding assistants can introduce risks. The framework treats license compliance as a concern distinct from security (the domain of DevSecOps), requiring its own tools, processes, and governance. The authors argue that SCA tools must be deployed not just at build time but at the point of code generation -- scanning AI output before it enters the codebase, not after.
Right direction. But it requires organizations to acknowledge a problem most haven't identified.
The M&A time bomb
License conflicts become acutely consequential in mergers and acquisitions. Due diligence for software acquisitions routinely includes open source audits. If the target company has GPL-licensed code embedded in a proprietary product, the acquirer inherits the obligation to open-source the relevant code or face litigation risk.
Before AI coding tools, the license audit was tractable. Most open source entered through package managers, which left metadata trails. An SCA scan of the dependency tree caught the majority of license obligations. Copy-pasted snippets and vendored libraries were manageable edge cases.
AI-generated code changed the scope. The 17% of open source components entering codebases outside of package managers represents risk that conventional due diligence may not catch. An acquirer's SCA scan shows a clean bill of health. The codebase is full of AI-generated code with undisclosed license obligations. The acquisition closes. The obligation transfers. The acquirer discovers the problem during a subsequent audit, or when a rights holder files a claim.
Only 54% of organizations evaluate AI-generated code for IP risks. Roughly half of all potential acquisition targets are accumulating license debt that doesn't show up in standard due diligence. For acquirers, the question is no longer "does this codebase have license conflicts?" It's "does this codebase have license conflicts that our tools can detect?"
What Red Hat sees

Red Hat's November 2025 advisory on AI-generated code in open source projects is blunt. Enterprises must maintain strict due diligence on the licensing of AI-generated code: automated license scanning, clear documentation of how and where AI-generated code was obtained, and internal policies defining how it is introduced and managed.
The advisory recommends internal policies covering code acceptance criteria, attribution and licensing, security compliance, and maintenance. The message is plain: organizations that treat AI-generated code the same as human-written code -- same review process, same tooling -- are accepting risk their existing processes weren't designed for.
Red Hat is one of the largest commercial open source companies in the world, with direct visibility into how license conflicts play out at enterprise scale. When they tell you to audit AI-generated code for license compliance, it's because they've seen what happens when you don't.
The structural fix
The problem has three layers, each requiring a different intervention.
Layer one: visibility. Organizations need to know which code was AI-generated. This is a metadata problem. If AI-generated code enters the codebase without any marker distinguishing it from human-written code, no downstream process can apply the right audit. The fix is simple in principle -- tag AI-generated code at creation -- and difficult in practice, because most AI coding tools don't produce this metadata and most workflows don't capture it.
Layer two: scanning. Once AI-generated code is identified, it needs snippet-level scanning against known open source repositories, not just package-level. This is the DevLicOps approach: license compliance at the point where risk is introduced, not at the end of the pipeline. SCA tools like SCANOSS and FOSSA are building these capabilities, but adoption lags far behind the AI coding tools creating the problem.
Layer three: constraints. The most effective mitigation is proactive. If the system's license requirements are declared in a machine-readable specification -- "this codebase is distributed under a proprietary license; no copyleft-licensed code or copyleft-derived implementations are permitted" -- then both human developers and AI agents can be constrained before the code enters the repository.
This is where most organizations are furthest behind. They have no machine-readable declaration of their licensing posture. The information lives in legal documents, corporate policies, maybe a wiki page nobody reads. The AI assistant doesn't know your codebase is proprietary. It doesn't know you can't accept GPL-derived code. It generates what it generates, you accept what you accept, and nobody finds the problem until the due diligence audit or the lawsuit.
The scale of the exposure
There are approximately 28 million software developers worldwide using AI coding tools, according to GitHub's 2025 developer survey. If the average developer accepts AI-generated code multiple times per day -- which usage data from Copilot and similar tools suggests -- then millions of AI-generated snippets are entering commercial codebases every day.
If Black Duck's finding holds -- that 68% of commercial codebases have license conflicts, driven in part by AI-generated code -- the aggregate license exposure across the global software industry is at the scale that historically drives class-action litigation and regulatory action.
Doe v. GitHub seeks $9 billion in damages from three defendants. The total exposure across all organizations shipping AI-generated code without license audits is orders of magnitude larger.
This is not a future problem. The code is already in production. The license obligations already exist. The only question is when they'll be enforced.
What to do now
If you are shipping commercial software and your developers use AI coding tools, here is the minimum response.
First, establish whether AI-generated code is being tagged or tracked in your codebase. If it isn't, you have no visibility into your exposure. Start capturing this metadata.
Second, deploy snippet-level license scanning on AI-generated code, not just dependency-level scanning. Your SCA tool needs to detect license-encumbered patterns in inline code, not just in imported packages.
Third, declare your licensing constraints in a machine-readable format accessible to your development tools. If your codebase is proprietary, that constraint should be explicit and enforceable at the point of code generation. Not in a policy document. In the system.
Fourth, audit your existing codebase. The AI-generated code that entered your repository six months ago, twelve months ago, two years ago -- before anyone was thinking about this -- is still there. It still carries whatever license obligations it carried when it was generated. Find out what's in there before a due diligence process or a legal action discovers it for you.
The code is already written. The licenses already apply. The only variable is whether you find the conflicts or they find you.