
Open your codebase. Search for how you validate email addresses. If you've been using AI coding tools for the past year, you'll probably find three implementations. Maybe four. Slightly different variable names, different edge case handling, different levels of thoroughness. Each one generated in response to a different prompt, in a different context, by an agent that had no idea the others existed.
Each one, from the agent's perspective, is new work.
This is the duplication problem. The data on it is now comprehensive enough to stop treating it as anecdote and start treating it as a measured phenomenon.
What GitClear found
GitClear's 2025 AI code quality research analyzed 211 million changed lines of code authored between January 2020 and December 2024. The analysis classified changes by type -- new code, refactored code, moved code, deleted code, and copy/pasted (cloned) code -- based on structural analysis of the diffs, not self-reporting.
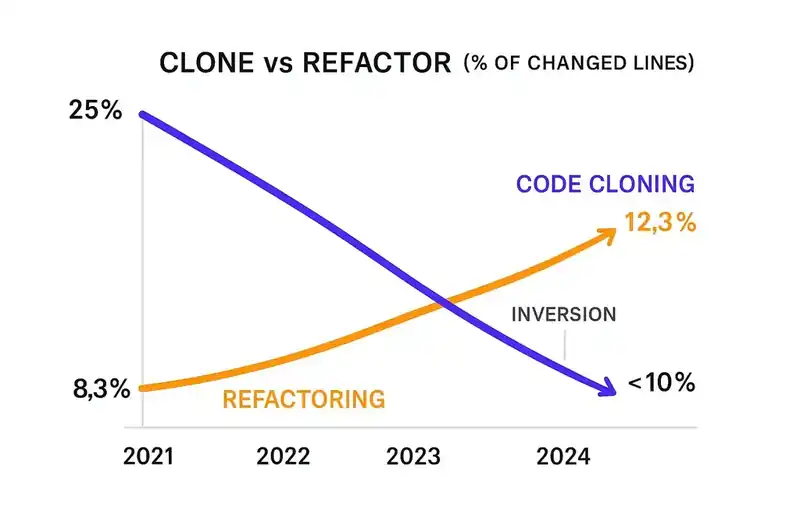
Code cloning increased by 4x. The proportion of changed lines classified as "copy/pasted" rose from 8.3% in 2021 to 12.3% in 2024. The number of code blocks containing five or more duplicated lines increased eightfold during 2024 alone. This isn't incidental similarity. It's wholesale duplication of non-trivial code blocks.
Refactoring collapsed. The percentage of changed lines associated with refactoring sank from 25% in 2021 to less than 10% in 2024. A 60% decline. 2024 was the first year in GitClear's dataset where copy/pasted lines exceeded moved lines. Developers are now more likely to duplicate code than to reorganize it.
The copy/paste-to-move ratio inverted. Historically, when developers needed functionality from elsewhere in the codebase, they moved it -- extracting it into a shared module, refactoring it into a reusable function. That pattern has reversed. The dominant pattern is duplication: generate a new version rather than reuse the existing one.
This is 211 million lines of code across a large cross-section of active repositories. The trends are directional, consistent, and accelerating.
Why AI generates duplicates
The mechanism follows from how these tools work.
When you prompt an AI assistant to write a function, it generates code based on the prompt, its training data, and whatever context window it has. In most workflows, the context window includes the current file, maybe a few related files, and the conversation history. It does not include a map of every utility, helper, and shared module in the codebase.
The assistant doesn't know you already have an email validator in utils/validation.ts. It doesn't know your team standardized on a date formatting approach six months ago. It doesn't know the authentication flow it's about to generate duplicates one in a different service. It generates from scratch, every time.
This is a context limitation, and it's fundamental. Even with expanded context windows -- 100K tokens, 200K tokens, a million tokens -- the assistant is working from a text dump of code, not from a semantic understanding of the architecture. It can see code. It can't see intent. It can't see the decision that led to the existing implementation.
Mike Mason, Chief AI Officer at ThoughtWorks, described the result in his January 2026 analysis of AI coding agents: agents make decisions that are locally sensible but globally inconsistent. Each individual code generation is reasonable in isolation. The function works. The tests pass. The review approves. But at the codebase level, the proliferation of slightly different implementations fragments the architecture.
Mason's core argument is that the challenge is coherence -- maintaining consistency across a codebase when code is being generated by tools that lack global context. The agent produces working code. The code doesn't know about the other working code doing the same thing two directories away.
The compounding effect
The duplication problem compounds in a way that isn't obvious from any individual code review.
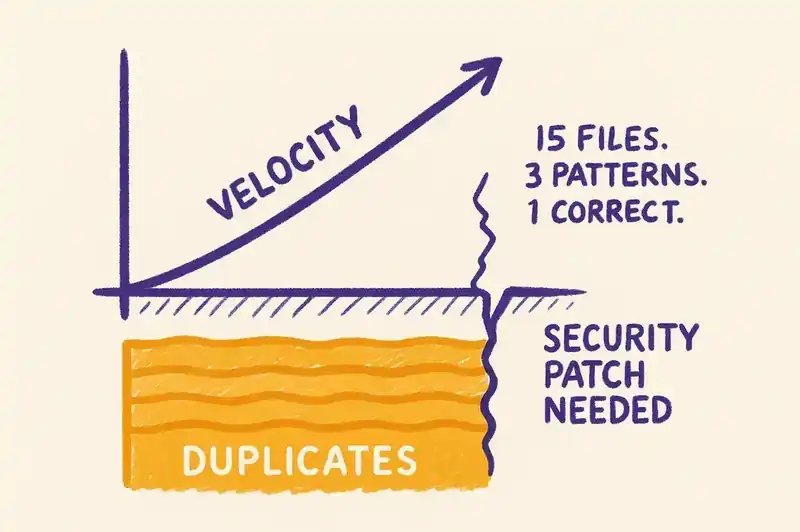
When a codebase has three implementations of email validation, the cost isn't the redundant code. It's the maintenance surface. When validation requirements change -- a new TLD is approved, a security vulnerability is discovered in the regex pattern, a compliance requirement mandates logging -- the change needs to happen in three places. The developer making the change finds one implementation, updates it, and moves on. The other two remain unchanged. Three implementations. One correct. Two subtly wrong.
Multiply this across every duplicated utility, every copied pattern, every generated-from-scratch implementation. The codebase develops pattern fragmentation: multiple competing approaches to the same operation, each with its own edge case handling, error behavior, and assumptions. Bug surface area grows linearly with duplicates. Cognitive load for any developer trying to understand the system grows faster than that, because they have to figure out which implementation is canonical and whether the differences are intentional.
The GitClear data on refactoring decline is the other side. Refactoring is the immune system that historically kept duplication in check. When a developer noticed duplicate code, they extracted it into a shared module. When inconsistencies emerged, they consolidated. That work has declined by 60% since 2021.
The decline is partly mechanical. AI coding tools make it easy to generate new code -- type a prompt, press tab, get a function. The path of least resistance is always generation. The AI won't say "you already have this function in utils/validation.ts, let me import it." It will generate a new one.
The decline is also economic. Refactoring is hard to justify in sprint planning. The feature works. The tests pass. In organizations where AI tools are measured by output velocity -- lines generated, features shipped, pull requests merged -- the incentive structure punishes refactoring. Why spend two hours consolidating duplicates when you could spend two hours generating three new features?
The METR study and the productivity paradox
A randomized controlled trial published by METR in July 2025 complicates the productivity narrative.
Sixteen experienced open-source developers completed 246 real tasks on repositories they personally maintained -- codebases averaging over one million lines. Tasks were randomly assigned to either "AI-allowed" (Cursor Pro with Claude 3.5 Sonnet) or "AI-forbidden" conditions.
Developers were 19% slower with AI tools. They expected to be 24% faster. Even after completing the tasks, they believed AI had sped them up by 20%.
The perception gap is striking, but the mechanism matters more. Developers accepted less than 44% of AI-generated suggestions. 75% reported reading every line of AI output. 56% made major modifications to clean up AI-generated code.
The AI was generating code that required significant effort to evaluate and correct. These were experienced developers on codebases they knew intimately. They caught the problems because they had the architectural context to recognize when generated code was wrong, redundant, or inconsistent. A less experienced developer, or one on an unfamiliar codebase, would catch fewer problems. More duplication would survive.
What canonical patterns look like
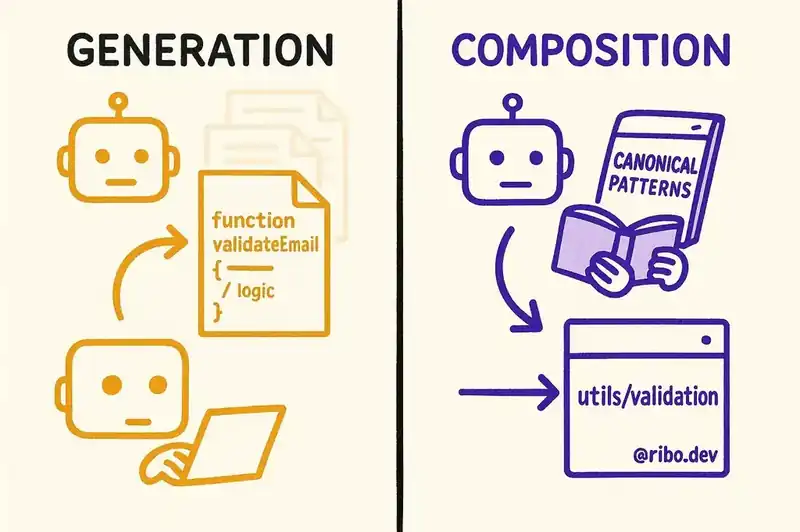
The opposite of pattern fragmentation is declared canonical patterns: a machine-readable specification of the approved way to perform common operations in a given codebase.
Style guides, architectural decision records, and coding standards have existed for decades. The difference is that those artifacts are written for humans. An AI coding agent doesn't read your ADR. It doesn't consult your style guide. It generates code from training data and immediate context, neither of which reliably contains your team's architectural decisions.
A machine-readable declaration of canonical patterns changes the generation context. Instead of generating email validation from scratch, the agent consults the specification, discovers the canonical function is utils/validation/validateEmail, and imports it. Instead of generating a new authentication flow, the agent finds the canonical pattern documented in the specification, with a reference implementation and constraints on acceptable variations.
This shifts the agent from generation to composition. It doesn't write new code for established operations. It reuses existing code. The duplication problem shrinks not because a linter catches duplicates after the fact, but because the agent never created them.
The architectural coherence problem
Mason's framing points to something deeper than code duplication. When multiple AI agents -- or the same agent across multiple sessions -- generate code for a codebase without a shared understanding of its architecture, the result is architectural fragmentation.
Different services adopt different patterns for the same cross-cutting concern. Error handling follows three conventions. Logging uses two libraries. API clients are inline in some services and shared modules in others. Each decision was locally sensible. The global result is an architecture with no coherent identity.
Human engineering teams historically solved this through code review, architectural governance, and the shared mental model that develops when a team works together over time. AI agents erode all three. They generate code too fast for review to be comprehensive. They don't participate in governance. They don't develop a shared mental model because they don't have persistent memory across sessions.
The replacement is a declared architecture: a specification that captures canonical patterns, permitted libraries, expected conventions, and the boundaries between components. Human teams can internalize this informally. AI agents need it written down.
The maintenance cliff
Here is the scenario most organizations using AI coding tools are building toward.
Over the next twelve to eighteen months, AI-generated code accumulates at the current rate. Duplication increases. Refactoring stays depressed. Pattern fragmentation grows. The codebase works -- features ship, tests pass, users don't notice.
Then something changes. A security vulnerability requires updating a utility duplicated across fifteen files. A compliance requirement mandates consistent logging across all services. A performance bottleneck traces to three different implementations of the same database query, one catastrophically inefficient.
The organization discovers that speed gains from AI-assisted development were borrowed from future maintenance costs. The code was generated fast. It wasn't generated consistently. Making it consistent now -- finding all the duplicates, determining which is canonical, refactoring the others -- is more expensive than writing it correctly would have been.
This is the maintenance cliff. It doesn't show up in quarterly velocity metrics. It shows up when the codebase needs to change in ways the original generation didn't anticipate. Every codebase eventually does.
What to do about it
The interventions that matter are structural.
Detect duplication continuously. If you aren't measuring code cloning, you don't know how bad the problem is. GitClear's methodology -- classifying changes by type and tracking the clone ratio over time -- is reproducible. Tools like SonarQube and Codacy can surface duplication at the PR level. Make it visible before it becomes entrenched.
Declare canonical patterns. For every common operation -- validation, authentication, error handling, logging, API calls, data transformation -- establish a canonical implementation and declare it in a format both humans and AI agents can read. When an agent generates code that duplicates a canonical pattern, the specification redirects it toward reuse.
Measure refactoring, not just generation. If your engineering metrics reward output velocity and ignore structural quality, your incentives favor duplication over refactoring. Track the refactoring ratio alongside the generation ratio. When it drops below a threshold, the codebase is accumulating structural debt faster than it's being retired.
Give agents global context. The context window problem is real but manageable. Agent frameworks that can index and query the codebase's architecture -- its structure and patterns, not just its text -- enable agents to discover existing implementations before generating new ones. This is an active area of tooling development worth investing in.
The AI wrote that function three times because nobody told it the function already existed. That's not a failure of the AI. It's a failure of the specification. The codebase's identity -- its canonical patterns, its architectural decisions, its shared conventions -- is the context that prevents duplication. If that identity exists only in the heads of the engineers, the AI will never see it. And the functions will keep multiplying.