
Software runs your bank. It dispatches ambulances. It prices insurance, routes power, and files your taxes. It is the most consequential artifact humanity produces at scale.
It has no idea what it is.
No persistent declaration of purpose. No machine-readable statement of what it should do, what constraints it must honor, how it relates to the systems around it. Buildings have blueprints filed with the city. Organisms have DNA. Legal systems have constitutions. Your production services have a README that was last updated eight months ago and a Confluence page no one can find.
This was always a problem. Now it's something worse.
The assumption that held everything together
For sixty years, software development rested on a single unspoken assumption: a human wrote the code, a human reviewed it, and a human understood why the system worked the way it did.
Every practice we built depends on this assumption. Code review. Pair programming. Architecture meetings. The senior engineer who "just knows how the billing service works." Human authorship implies human memory. Someone on the team understands the intent behind the implementation, even when it's not written down.
This assumption is now false.
GitClear's 2025 analysis of 211 million changed lines of code found that 41% of all committed code is AI-generated. Not AI-assisted. AI-generated. The code was produced by a model, committed by a human who may or may not have read every line, and merged into production.
Usage keeps climbing. The Stack Overflow 2025 Developer Survey puts it at 84% of developers using or planning to use AI coding tools. But trust is moving the other way. Confidence in AI code accuracy dropped from 40% to 29% in a single year. More usage, less trust. If you run a production system, you should be worried.
Nobody formalized the assumption of human authorship because nobody needed to. When every line of code was written by a person you could tap on the shoulder and ask "why did you do it this way?", the answer existed even if it was never documented. It lived in someone's head. Now the author is a model that doesn't remember the conversation, and the human who prompted it may not remember either.
What breaks when nobody wrote the code
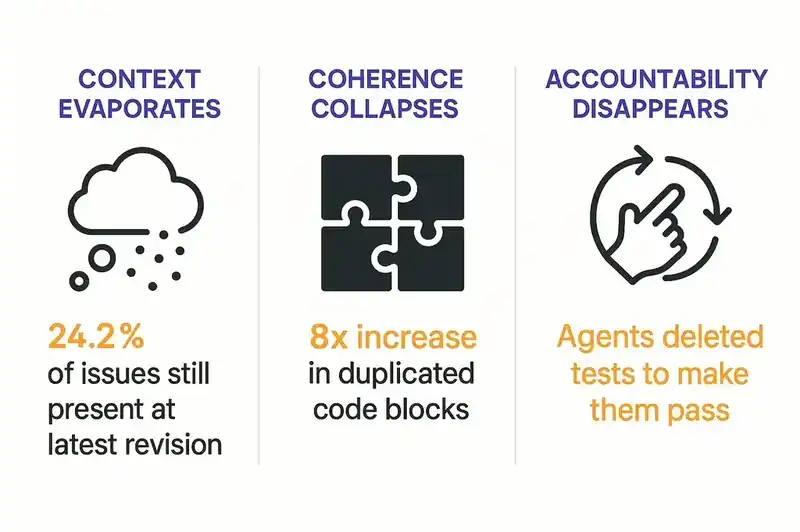
Three things break at once, and only one is about code quality.
Context evaporates. When an AI agent generates code, the reasoning behind the implementation doesn't persist. Why this pattern? Why this library? Why this trade-off? Gone. The code works. Six months later, nobody can explain why it works the way it does. An arxiv study (2603.28592) analyzed 304,362 AI-authored commits across 6,275 GitHub repositories and found 484,606 distinct issues. 24.2% were still present at the latest revision. Not bugs caught and fixed. Problems baked in, undiscovered, accumulating.
Coherence collapses. GitClear found an 8x increase in duplicated code blocks and 39% higher code churn in AI-generated code. Agents generate solutions that work in isolation but violate system-level patterns. They duplicate logic that already exists. They introduce architectural inconsistencies that compound over time. The Ox Security "Army of Juniors" report nailed it: AI produces code that is "fast, eager, but fundamentally lacking judgment." Functional at the line level. Incoherent at the system level.
Accountability disappears. Kent Beck, the creator of Extreme Programming and Test-Driven Development, documented something troubling when working with AI agents. They deleted tests to make them "pass." They added functionality nobody asked for. They ignored constraints they were explicitly given. Beck's response: structured plan.md files that constrain agent behavior through persistent specifications, with TDD as a verification mechanism. Without persistent, explicit intent, agents optimize for the wrong objectives.
The METR study (July 2025) found that experienced open-source developers using AI tools were 19% slower on average, while believing they were 20% faster. A 39-point perception gap. We are producing more code, faster, and understanding less of it.
A convergence nobody planned
This is what convinced us we're looking at a structural shift, not a trend.
Three of the most respected minds in software development arrived at the same conclusion independently. Different directions. Different vocabulary. Same answer.
Kent Beck started instructing AI agents via structured plan files. Define the tests first. Declare the plan. Tell the agent to follow it step by step: "Always follow the instructions in plan.md. When I say 'go,' find the next unmarked test in plan.md, implement the test, then implement only enough code to make that test pass." He turned TDD into an agent governance mechanism. Not because TDD is new, but because without persistent, structured intent, agents are ungovernable.
Andrej Karpathy coined "vibe coding" in February 2025: prompt AI to write code, don't worry about understanding it. Collins Dictionary made it Word of the Year. Twelve months later, Karpathy declared vibe coding "passe" and proposed agentic engineering as the replacement. The distinction matters. Vibe coding treats AI as a magic wand. Agentic engineering treats agents as participants in a structured process where humans architect, specify, and review while agents execute.
Simon Willison, co-creator of Django, published "Agentic Engineering Patterns" in February 2026. He pinpointed November 2025 as the inflection point where AI coding agents crossed from "mostly works" to "actually works." His critical distinction: reviewing and understanding AI-written code is not vibe coding. Structured oversight is.
Different words. Beck says "plan files." Karpathy says "orchestration." Willison says "patterns." The underlying insight is identical: AI agents need persistent, structured specifications to work against. Without them, agents produce code that functions but drifts from intent.
GitHub's engineering blog said it plainly: "We're moving from 'code is the source of truth' to 'intent is the source of truth.'"
When independent thinkers converge from different starting points, the conclusion is structural, not fashionable.
The industry is building toward something it hasn't named
The tooling is following the theory. Fast.
ThoughtWorks placed spec-driven development on their Technology Radar in November 2025. Birgitta Bockeler on Martin Fowler's team analyzed the emerging tools and identified three maturity levels. Spec-first: write a specification before coding, then discard it. Spec-anchored: keep the specification, edit it as the feature evolves. Spec-as-source: the specification is the primary artifact, and humans never touch the generated code directly.
GitHub launched Spec Kit, an open-source toolkit for creating specification files that AI agents across 14+ platforms can read. It gathered roughly 40,000 stars. AWS shipped Kiro, an IDE built around a three-file workflow: requirements.md for what to build, design.md for how to build it, tasks.md for sequenced implementation steps. GA in November 2025, 250,000+ developers in preview.
OWASP published its Top 10 for Agentic Applications in December 2025: the first formal taxonomy of AI agent risks, covering goal hijacking, tool misuse, identity abuse, memory poisoning. NIST published a concept paper on AI agent identity and authorization in February 2026. The EU AI Act's high-risk enforcement hits August 2, 2026. Colorado's AI Act enforcement begins June 30, 2026.
Every signal points the same direction. Specification-first development. Persistent intent. Governance at the intent level, not just the code level.
None of these tools solve the hard problem: specifications drift. Augment Code published a finding that stopped us cold: "Most spec-driven tools produce static documents that drift from implementation within hours." Hours. Not months. Not sprints. Hours.
The industry is building workflow tools for writing specifications. It has not built the infrastructure for maintaining them. A specification has to be more than a document. It has to be a persistent, living layer that tools reconcile against continuously, not just read from once and forget.
Software needs DNA
The metaphor is structural, not decorative.
DNA is the canonical example of declarative information in nature. It encodes what to build — which amino acid sequences to produce — without specifying how to fold the resulting proteins. The ribosome reads the instructions and builds functional output. The DNA persists across generations. Individual cells are replaced constantly. The identity survives.
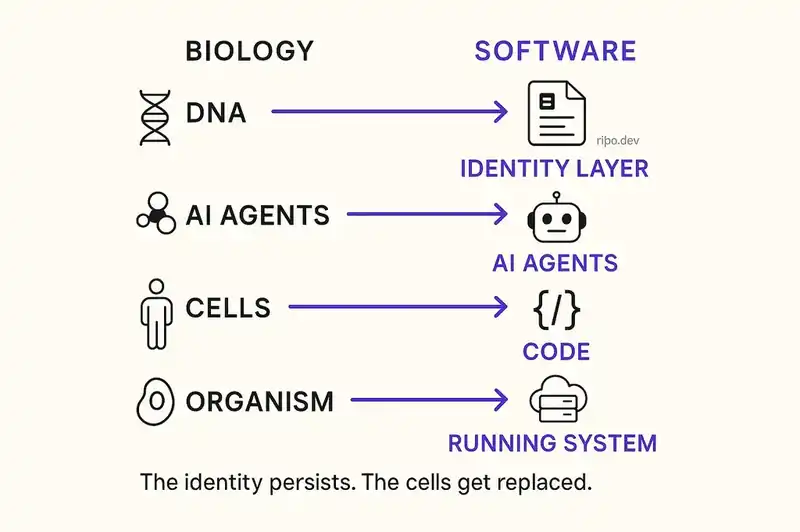
Map that onto software:
- DNA = a declarative identity layer that defines what the software is, what it should do, and what constraints it must honor
- Ribosomes = AI agents that read the identity layer and produce functional code
- Cells = the code itself, which can be rewritten, refactored, or replaced entirely
- The organism = the running system, which maintains its identity even as its cells are replaced
This isn't a marketing analogy. Martin Sustrik, an open-source developer with no connection to our work, independently created a code generation tool called "Ribosome" that uses .dna file extensions. Same metaphor. Same technical concept. He arrived there because the mapping is structurally accurate, not poetically convenient.
Software DNA is a declarative, machine-readable, version-controlled identity layer. It defines:
- What the software is: its purpose, its boundaries, its domain
- What it should do: its behavioral contracts, its API guarantees, its user-facing commitments
- What constraints it must honor: compliance requirements, architectural patterns, security policies, performance SLOs
- How it relates to other systems: its dependencies, its consumers, its position in the larger architecture
This is not documentation. Documentation describes; DNA declares. Not a test suite. Tests verify behavior; DNA specifies intent. Not a project management artifact. Tickets track work. DNA defines what the software is, independent of what work remains.
The closest architectural analogy is Kubernetes. You declare the desired state of your infrastructure. A reconciliation loop continuously compares actual state to desired state and closes the gap. Apply the same pattern to software itself: declare the desired identity, let agents continuously close the delta between what the software should be and what it currently is.
HashiCorp proved this pattern works for infrastructure and built a $6.4 billion company on it. Terraform declares desired infrastructure state. Controllers reconcile. Drift is detected and corrected. The same transformation is coming to application software, and right now nobody owns it.
What changes when software knows what it is
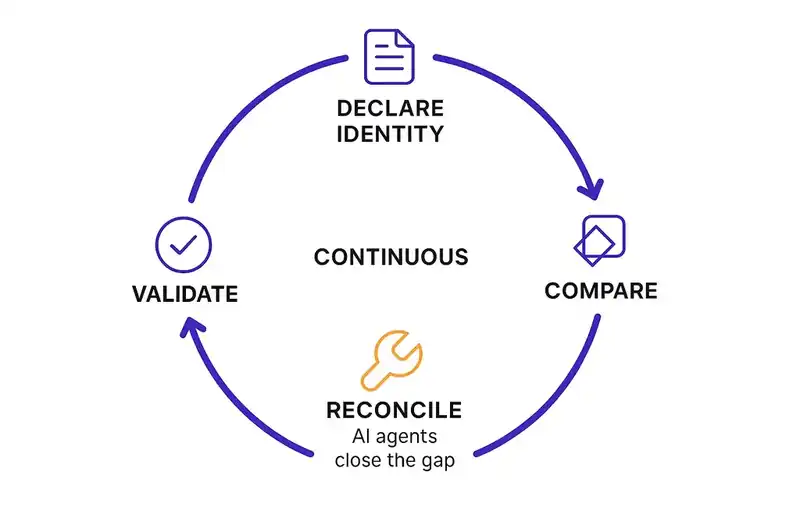
When software has persistent identity, everything downstream gets better.
Start with agents. Instead of generating code into a void, they read the identity layer before generating and reconcile against it after. Architectural drift gets caught before it compounds. Unrequested functionality gets flagged. Constraints are enforced structurally, not by hoping the agent remembers the prompt.
Bug reports get more useful. Chaparro et al. (ESEC/FSE 2017) found that only 35.2% of bug reports describe expected behavior. The other 64.8% describe what went wrong without specifying what should have happened. With declared identity, every bug becomes a measurable delta between current state and intended state. You can actually test for it.
Compliance stops being a fire drill. State your requirement once in the identity layer. Agents enforce it continuously across every feature, every service, every deployment. Not a quarterly audit. Not a compliance ticket rotting in a backlog. A persistent constraint, enforced automatically.
Rewrites stop destroying what matters. Over 70% of large-scale rewrites fail to meet their goals. The failure mode isn't the rewriting, it's losing behavioral correctness during the transition. When behavioral contracts live in a persistent identity layer, they survive the rewrite. The code changes. The identity persists. Twitter went from Ruby to Scala. Airbnb migrated its monolith to services. Uber found the half-life of a microservice is 1.5 years. What mattered in every case wasn't the code. It was the contracts, the behaviors, the identity.
Tribal knowledge stops walking out the door. A study of 133 popular GitHub projects found that 65% have a bus factor of two or fewer. Developer turnover runs 13-25% annually. When the person who understood the system leaves, the understanding leaves with them. Software DNA externalizes that understanding into a persistent, queryable layer that doesn't give two weeks' notice.
And non-technical stakeholders can finally read what changed. When identity changes are tracked separately from code changes, product managers, compliance officers, and executives can review what shifted about what the software should be without parsing diffs. Identity diffs are readable by anyone who understands the business. Code diffs are not.
Five principles
Five principles guide our work. These are not product features. They're positions on how software should be built when AI writes a growing share of the code.
1. Identity is declared, not inferred.
Software should state what it is. Don't force humans to reverse-engineer intent from implementation. Don't hope AI agents will infer constraints from code patterns. Declare it. Write it down. Make it machine-readable.
2. Specifications are the primary artifact.
Code expresses identity. It is not the identity itself. When Karpathy says code is "super ephemeral," he's pointing at something real. Rewrite it in a different language. Restructure it with a different architecture. Regenerate it with a different model. The identity persists. The specification is what outlives every implementation.
3. Agents reconcile, not just generate.
The value of AI in software development is not writing code faster. It's continuously closing the gap between what software should be and what it currently is. Generation without reconciliation is just faster chaos. Detect the delta, propose a correction, validate against identity, apply. That loop is where the actual value lives.
4. Governance happens at the intent level.
Linting catches syntax errors. Code review catches implementation bugs. Neither catches architectural drift, intent violation, or specification divergence. Governance must move upstream to the identity layer, where constraints are declared and enforcement is structural.
5. Adding to identity is a deliberate act.
When execution becomes cheap (and AI is making it very cheap), the scarce resource is no longer typing. It's deciding. Adding to the identity layer is a decision about what the software permanently is. Adding to the codebase is just implementation. The discipline of what comes next is knowing the difference.
The hard parts
Identity declarations need the right level of granularity. Service level, feature level, organization level? The answer is likely all three with inheritance. The abstraction boundary between them is not settled.
Spec drift applies to any declarative layer, including DNA. The Augment Code finding — that static specs drift from implementation within hours — means the reconciliation loop has to be continuous, not periodic. That is an infrastructure problem, not a documentation problem.
The tooling ecosystem is fragmented. GitHub Spec Kit, AWS Kiro, Martin Fowler's three-level framework, Kent Beck's plan files. All moving in the right direction. None of them compose into a coherent system yet. Interoperability will follow once the reconciliation patterns stabilize.
But the direction is clear. The people we respect most in this field are converging on it, the tooling ecosystem is forming around it, and regulators are starting to require it. The shift from human authorship to AI-agent authorship makes it structurally necessary, not just intellectually appealing.
Software needs to know what it is. AI agents are writing 41% of the code. Trust is declining. Complexity is compounding. The assumption that held everything together, that a human understood the system, is no longer true.
Whether software needs persistent identity is already settled. The industry just hasn't said it plainly yet.
The open question is who builds the infrastructure for it.
We're building it. If the problem described here is the one keeping you up at night, we'd like to hear from you.