
Every sprint burndown chart tells the same story: you start with a pile of work, you chip away at it for two weeks, and the line goes down. If the line hits zero, you succeeded. If it doesn't, you failed. Reset. Repeat.
This model has a problem. It assumes "done" is a fixed point. The definition of the work stays constant while you execute against it.
For discrete tasks (ship this button, fix this query, patch this vulnerability) the assumption holds well enough. But for the system as a whole? The system is never done. Its requirements shift, its contracts evolve, its compliance obligations get rewritten by regulators on a timeline you do not control. The gap between what your software declares itself to be and what it actually does is always non-zero.
The useful question is how fast you close that gap when it opens.
The burndown chart's blind spot
Burndown charts have well-documented limitations. They do not track scope changes. They do not reveal whether the completed work is the most valuable work. They encourage a fixed-scope mindset that contradicts the adaptive principles agile was supposed to embody. A team can hit the ideal burn line every sprint while the system drifts further from what it needs to be.
The deeper issue is structural. A sprint burndown models work as a finite resource that gets consumed. But software identity (the set of constraints, contracts, and behavioral requirements that define what a system is) is not finite. It grows. It changes. Some months you are adding SOC 2 controls across every service. Other months you are ripping out a deprecated authentication pattern. And sometimes nothing changes and the system sits in equilibrium.
A burndown chart has no vocabulary for this. It cannot represent a target that moves. It cannot distinguish between "we finished the work" and "the work finished mattering." It measures completion against a snapshot, not convergence toward a living definition.
The identity burndown
Imagine a different chart. The horizontal axis is time, continuous, not boxed into sprints.
The first line represents your software's declared identity: the full set of constraints, contracts, and compliance requirements that define what the system should be at any given moment. This line is not flat. It steps up when you add a new constraint ("all services must encrypt PII at rest"). It steps down when you remove an outdated one. It shifts laterally when a contract gets renegotiated. Every identity mutation moves this line.
The second line represents your implementation: what the code actually does right now. This line chases the first. When a new constraint lands, a gap opens. The implementation line curves upward toward the identity line as agents and engineers close the delta. It never quite reaches it before the identity line moves again.
The gap between these two lines is always non-zero. That is the permanent condition of a living system, not a failure state. The metric that matters is the derivative: how fast the implementation line converges toward the identity line after each mutation. A team that closes 80% of a new constraint's delta within 48 hours is performing well, even if the gap never hits zero. A team whose implementation line lags the identity line by weeks is in trouble, even if their sprint burndowns look perfect.
This is the shift: from measuring completion to measuring convergence velocity.
Why convergence behaves like model training
If you've watched a neural network train, the identity convergence pattern will look familiar.
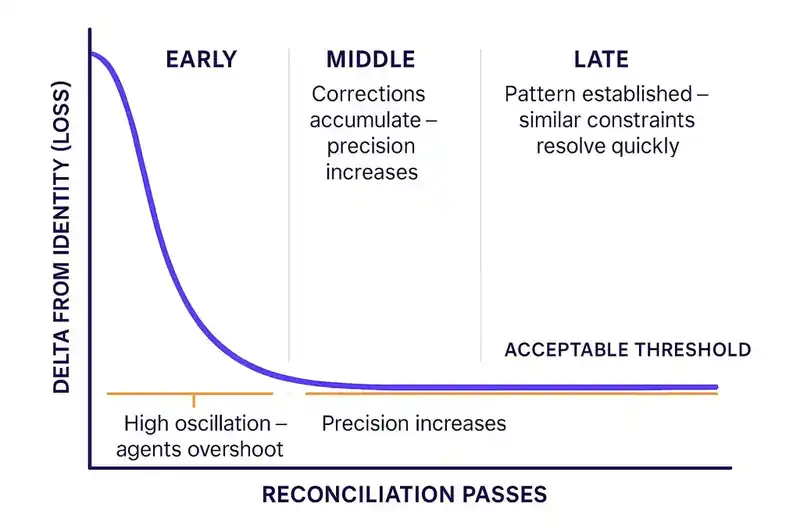
In the early passes (the first time agents encounter a new constraint) the system overshoots. An agent tasked with enforcing "all API endpoints must validate authentication tokens" applies the constraint everywhere, including internal health-check endpoints that sit behind a service mesh and never touch user data. The implementation swings past the target. The gap inverts. Things that were fine are now broken.
This is the equivalent of early training epochs with a high learning rate. The model has not learned the pattern yet. It applies broad corrections that move the loss function in the right direction on average but oscillate wildly on individual examples. Loss is high. Variance is high.
In the middle passes, corrections accumulate. The reconciliation loop has history. Agents distinguish between endpoints that handle user data and endpoints that do not. The oscillation dampens. Each reconciliation pass makes smaller adjustments. The constraint gets applied with more precision.
In the late passes, the system has converged on the pattern. When a similar constraint lands later ("all endpoints handling financial data must log access events") the agents resolve it quickly because the structural patterns are established. The auth token constraint already separated internal from external endpoints. The logging constraint inherits that distinction. The system has learned.
The failure modes map too. Overfitting in ML means the model memorizes training examples instead of learning the underlying pattern. In identity convergence, overfitting is over-enforcement: an agent applies a constraint too literally in contexts where the spirit of the constraint does not apply. A security logging requirement gets added to a /healthz endpoint that returns a static 200 and processes no user data. The implementation technically satisfies the constraint. It also adds latency, log noise, and maintenance burden for zero security value.
Human review is the regularization mechanism. An engineer looks at the over-enforced endpoint, recognizes the mismatch between letter and intent, and corrects course. Regularization in training penalizes complexity that does not improve generalization. The human does not need to review every reconciliation. They review the ones where the agent's confidence is lowest or the blast radius is highest, the same places where a training engineer would inspect outlier predictions.
The identity changelog
Teams struggle to accept "done" as a moving target because they cannot see the target moving. A new compliance requirement lands in a Slack thread. A contract change gets negotiated in a meeting. None of it is tracked as a formal change to the system's definition.
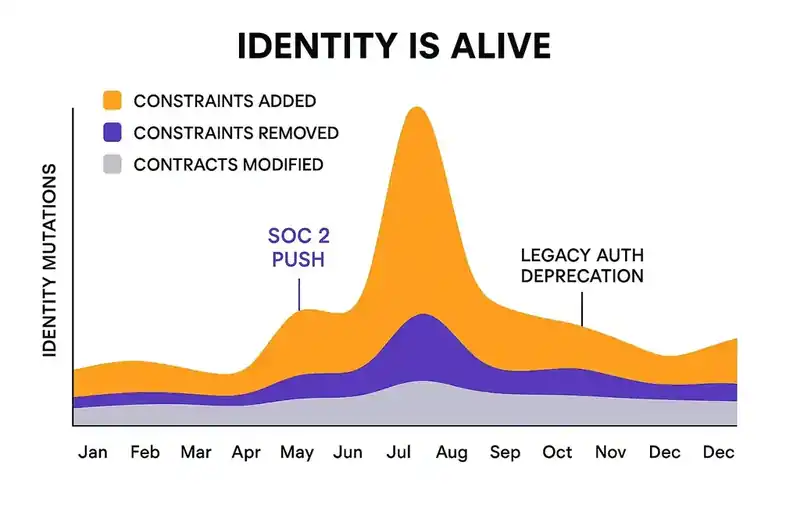
Now imagine you could see it. A stacked area chart showing every identity mutation over time. Constraints added in violet. Constraints removed in amber. Contracts modified in gray.
Some months are heavy. A SOC 2 audit triggers dozens of new constraints across every service. Some months are quiet. The system sits in near-equilibrium, and the implementation line hugs the identity line closely. Neither pattern is wrong. The heavy months are the organization learning and encoding what it learned. The quiet months are the payoff of prior convergence work.
This makes identity change something healthy, not something to avoid. The 2024 DORA report found that organizations with strong platform foundations see their improvements compound; each investment makes the next change cheaper. Identity mutations work the same way. The first SOC 2 constraint takes weeks to reconcile across the system. The thirtieth takes hours, because the patterns are established and the agents have learned.
The spike of truth
There is an uncomfortable moment that every team hits when they first adopt this model.
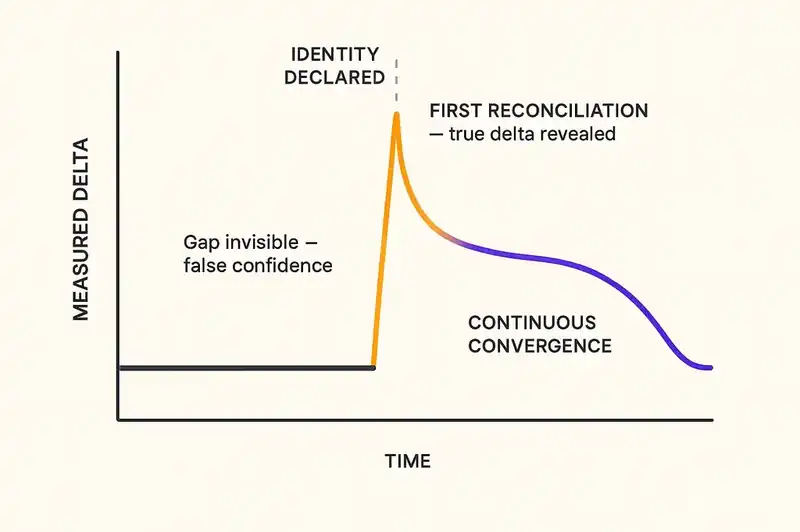
Before you declare your software's identity, the gap between intent and implementation is invisible. You cannot measure it. You cannot see it. So you assume it is small. The dashboard says 100% of tests pass, 100% of deployments succeed, sprint velocity is trending up. Everything looks fine.
Then you declare the identity. You write down the constraints. You encode the contracts. You run the first reconciliation.
The result is a spike. A vertical line on the chart showing every place where your code diverges from your stated intent. Things did not suddenly get worse. You are seeing the gap for the first time. The delta was always there. You just could not measure it.
This spike is hard to stomach. A VP of Engineering who just told the board that the platform is stable now has a chart showing 200 unresolved constraint violations. The temptation is to kill the measurement.
Resist it. The violations existed before you measured them. The spike is the first moment of honest data your organization has had about the distance between what your software should be and what it is. SOC 2 compliance alone takes 6 to 12 months for most organizations, not because the controls are hard, but because the gap between "we think we're doing this" and "we're actually doing this" is wider than anyone expected.
Every team that adopts identity engineering goes through this. The ones that survive the spike build better systems. The ones that flinch go back to not knowing.
Token spend as learning rate
In identity convergence, token spend plays the role of learning rate. Tokens are the unit of compute that agents consume when reconciling code against constraints. More tokens means more agents running more passes, trying more approaches, which gives you fast convergence but high oscillation. Fewer tokens means slower, smoother reconciliation. But if the identity line keeps moving faster than the implementation line can follow, the gap widens.
The skill is tuning. A data residency requirement with a regulatory deadline and a EUR 15 million penalty gets maximum spend. An internal code style preference gets the minimum. This is resource allocation, the same kind engineering leaders already do with headcount and sprint capacity. The unit is different. The judgment is the same.
The efficiency facilitator
In the old model, engineers are the convergence mechanism. They read requirements, write code, review each other's code, and hope the collective output matches the collective intent. In the identity engineering model, agents handle convergence. The human role shifts to something closer to an ML engineer managing a training run. You stop adjusting weights by hand and operate at a higher level.
You define what convergence means: which constraints matter, which contracts are binding, which compliance requirements apply. This is product and architectural judgment, the part that cannot be automated.
You set the learning rate. Which identity mutations get aggressive reconciliation and which get conservative treatment. Speed versus stability, based on deadlines, risk, and organizational tolerance for noise.
You detect overfitting by reviewing agent behavior where confidence is low or stakes are high. Catching over-enforcement. Providing the corrective signal that keeps the system generalizing rather than memorizing.
You decide when it is good enough. A non-critical internal service at 92% convergence might be fine. A payment processing service at 92% might not be. You set the threshold per service, per constraint category, per risk profile.
You time new mutations. You do not dump thirty new constraints into the system during a production incident. You sequence identity changes based on organizational readiness, the same way an ML engineer does not change the architecture, the learning rate, and the training data simultaneously.
The work moves from "write the code that satisfies the constraint" to "design the system that ensures constraints get satisfied continuously." The leverage is higher.
The metric that replaces "done"
If "done" is the wrong frame, what replaces it?
Convergence velocity is how quickly your implementation closes the gap after an identity mutation. Measured in hours or days, not sprints.
Steady-state delta is the residual gap during quiet periods when the identity line is stable. A smaller steady-state delta means your system is well-converged. A larger one means drift is accumulating faster than reconciliation can close it.
Mutation absorption rate is how quickly new types of constraints get reconciled compared to established types. If your first data residency constraint took two weeks and your fifth takes two days, the system is learning. If the fifth still takes two weeks, something structural is blocking pattern reuse.
Over-enforcement rate is how often human reviewers override agent reconciliation decisions. A declining rate means the agents are improving. A flat or increasing rate means the constraints need refinement, or the agents need better context.
None of these are binary. They measure trajectory, direction, rate of change. They tell you whether your system is getting better at becoming what it is supposed to be, and whether it is doing so fast enough to keep up with what "supposed to be" means this month.
The system that converges
The sprint burndown served its era well. It gave teams a visual model of progress against a fixed goal. For work that has a fixed goal (ship this feature by Friday) it still works fine.
But the work that matters most does not have a fixed goal. The system's identity changes. The regulatory environment shifts. Contracts get renegotiated. Competitors move. The definition of "what this software should be" is a function that changes over time, and the question is whether your rate of convergence toward the current definition is fast enough to matter.
Your software is never done. That is the operating condition of every system that is still alive. The teams that accept this, that stop measuring completion and start measuring convergence, are the ones whose systems actually become what they are supposed to be.