
Ask two engineers to build the same payment service. One works in Go. The other works in Rust. Give them identical requirements: process transactions, guarantee idempotency, honor a P99 latency target of 200ms, log every state change for audit.
Both will deliver working systems. Both will honor the same contracts. And the code will be completely different. The Go engineer reaches for goroutines and channels. The Rust engineer reaches for async traits and ownership semantics. Error handling, concurrency, dependency trees, testing patterns -- all different. Same intent. Same behavioral guarantees. Radically different implementations.
Everyone knows this. Nobody has named the thing that accounts for the difference.
The gap has a shape
We've spent the last year working on Software DNA -- the declarative identity layer that defines what a piece of software is, what it guarantees, and what constraints it must honor. DNA answers the question "what should this be?" It declares purpose, behavioral contracts, system relationships, compliance requirements. It's the specification that survives when the code gets rewritten.
But DNA doesn't produce code. DNA says "this service guarantees idempotent payment processing with P99 under 200ms." It doesn't say anything about whether that guarantee gets implemented with Go's net/http and sqlc, or with Rust's Axum and sqlx, or with Node's Fastify and Prisma. Each of those choices carries an entire world of implications -- idioms, error handling, testing frameworks, static analysis tooling, performance characteristics. All different.
There's a layer between "what the software should be" and "the code that runs." That layer determines how identity gets translated into a specific implementation given a specific set of tools, constraints, and conventions.
We call it the Ribosome Layer.
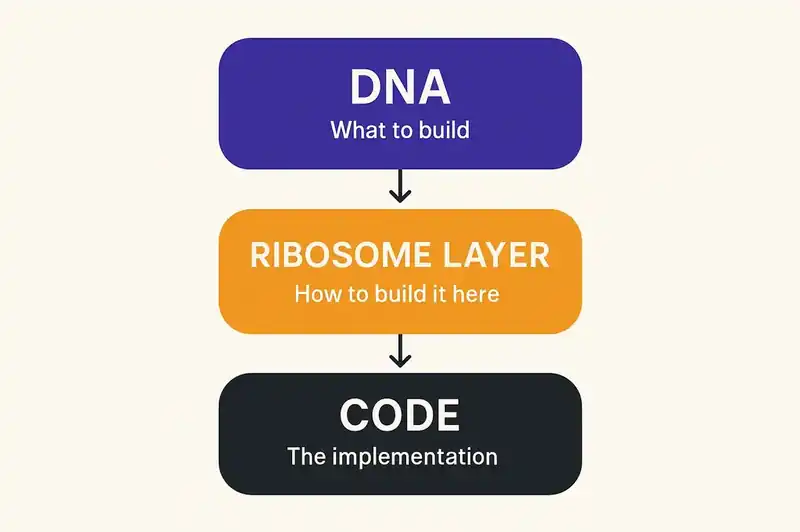
Why "ribosome" and not "compiler" or "translator"
The name isn't decorative. It's structurally precise.
In molecular biology, DNA encodes instructions for building proteins -- the functional molecules that do actual work in cells. But DNA doesn't build proteins directly. The ribosome does. It reads messenger RNA (transcribed from DNA), recruits transfer RNA molecules carrying amino acids, and assembles those amino acids into a polypeptide chain that folds into a functional protein. Biologists call this translation.
The part that matters: the ribosome's output depends on the cellular environment. The available pool of transfer RNA molecules, the concentration of amino acids, the temperature, the presence of molecular chaperones that assist protein folding -- all of these shape what the ribosome actually produces. The same DNA sequence, read in different cellular environments, can yield different protein conformations. The instructions are identical. The translation machinery and its context determine the output.
This maps precisely to software. The DNA (identity layer) declares what to build. The Ribosome Layer is the translation machinery: the language, the framework, the linter configuration, the test coverage requirements, the dependency policies, the deployment constraints. Change the ribosome layer -- swap Go for Rust, swap Chi for Axum, swap golangci-lint for Clippy -- and you get different code implementing the same identity. The DNA is stable. The ribosome layer is what varies.
Martin Sustrik, the creator of ZeroMQ and nanomsg, built a code generation tool and named it Ribosome. His template files use .dna extensions. The tool compiles DNA files into intermediate RNA scripts, which execute to produce final output. He arrived at the same metaphor independently, because the structural parallel between biological translation and code generation is real. DNA provides the template. The ribosome reads the template and produces functional output. The environment shapes what that output looks like.
What the ribosome layer contains
A painting analogy makes this concrete.
Imagine the identity declaration is: "Paint a lighthouse scene. Swirling sky. Blue palette. A face in the foreground." That's the DNA. It declares intent without specifying medium.
Now consider two ribosome layers.
The first is oil painting: you have oil paints, a 24x36 canvas, a palette knife. Texture matters. Drying time is three days. You can layer and rework. The medium rewards bold, impasto strokes.
The second is watercolor: you have watercolors, a 5x7 card, a fine brush. Transparency matters. The paint dries in minutes. You plan washes in advance because you can't cover mistakes. The medium rewards precision and economy.
Same identity. Completely different outputs. Both faithful to the intent. The medium shapes everything.
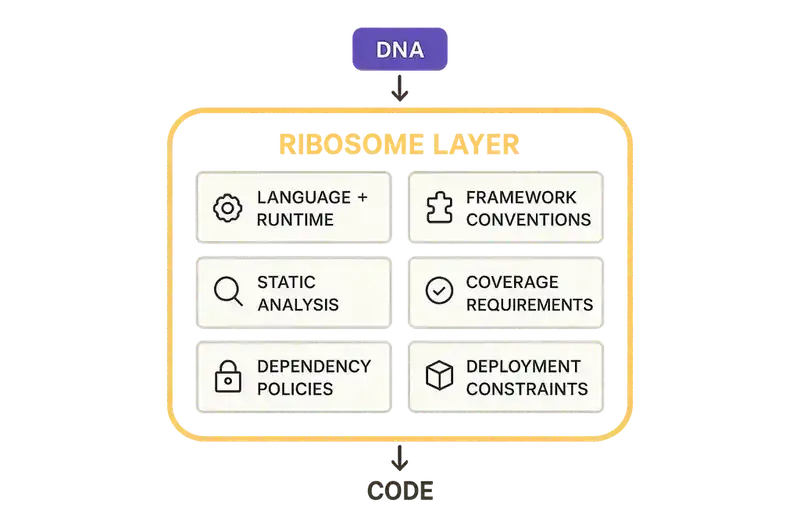
In software, the ribosome layer is the medium. It contains:
Language and runtime. Go, Rust, Node, Python, Java. Each carries different concurrency models, error handling patterns, memory management approaches, and ecosystem conventions. Go returns errors as values. Rust encodes them in the type system. Node uses async/await with promises. These aren't stylistic preferences. They're structural constraints that shape every function in the codebase.
Framework conventions. Express vs. Fastify in Node. Gin vs. Chi in Go. Actix vs. Axum in Rust. Same language, different patterns for routing, middleware, request handling, and error propagation. The framework choice ripples through the entire implementation.
Static analysis and quality tooling. ESLint rules, golangci-lint configuration, Clippy settings, Ruff for Python. These define what "correct" looks like in this specific codebase. A strict golangci-lint config that enforces errcheck, govet, and exhaustive produces different code than a permissive one.
Complexity and coverage requirements. Maximum cyclomatic complexity of 15. No function longer than 50 lines. 85% unit test coverage. Integration tests for every public API endpoint. No untested error path. These are the quality floor -- the line below which code doesn't ship.
Dependency policies. Approved package list. Version pinning strategy. License restrictions (no GPL in commercial code, for instance). Maximum transitive dependency depth. These constrain what building blocks are available, the way the available amino acids constrain what proteins a ribosome can produce.
Deployment constraints. Container image must be under 50MB. Cold start budget under 500ms. Memory ceiling of 256MB. These are physical constraints that eliminate entire categories of implementation choices. A 200ms cold start budget rules out most JVM-based approaches for serverless functions.
Performance SLOs as implementation constraints. P99 under 200ms isn't just a target -- it's a constraint that eliminates certain ORM patterns, mandates connection pooling, and may require caching at specific layers. The SLO shapes the code.
None of these belong in the DNA. The DNA says "guarantee idempotent payment processing." The ribosome layer says "do it in Go, with Chi, using sqlc for queries, zerolog for structured logging, golangci-lint in strict mode, 85% test coverage, no function over 50 lines, deployed as a container under 50MB."
An agent without a ribosome layer is guessing
An AI agent generating code has two sources of information: the prompt (or specification) it was given, and whatever it can observe in the existing codebase. If you give it identity -- "build a user service with OAuth 2.0 auth, Redis sessions, rate limiting at 100 req/s, audit logging on all endpoints" -- it knows what to build. Good start.
But it doesn't know your linting rules unless they're in context. It doesn't know your approved dependency list. It doesn't know that your team uses Chi instead of Gin, or zerolog instead of zap, or that your coverage threshold is 85%, or that your maximum function length is 50 lines. It doesn't know your container size limit or your cold start budget.
Without the ribosome layer, the agent produces code that works but violates every convention your team has established. It picks whatever framework shows up most in its training data. It imports packages your security team hasn't approved. It writes functions that pass tests but fail your linter. It generates code that's technically correct and practically unusable without significant rework.
It's "works on my machine" at a new scale. The agent's machine has no conventions, no constraints, no organizational context. Just training data, a prompt, and good intentions.
The ribosome layer makes all of this declarative and injectable. The agent reads identity (what to build) and the ribosome layer (how to build it here, in this environment, with these tools). The output honors both: the behavioral contracts from the DNA and the implementation constraints from the ribosome layer.
Identity without the ribosome layer: code that builds the right thing the wrong way. Ribosome layer without identity: well-linted code that builds the wrong thing entirely. You need both.
Rewrites become ribosome swaps
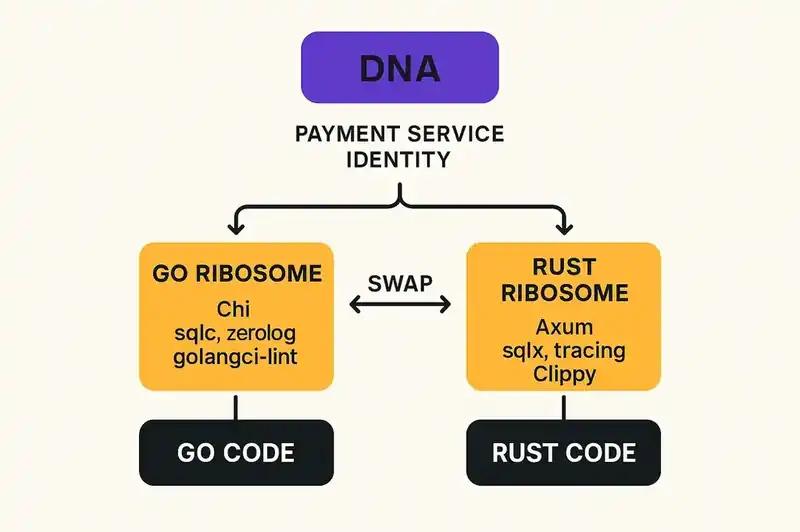
When you rewrite a system from Node to Go, what actually changes? The payment service still processes payments. It still guarantees idempotency. It still honors the same SLOs. It still integrates with the same upstream and downstream systems. The behavioral contracts, the constraints, the purpose -- the identity -- none of that changes.
What changes is the ribosome layer. The language, the frameworks, the idioms, the quality tooling, the deployment targets -- all of it. You're not changing what the software is. You're changing how it's translated into running code.
We wrote about this in "Rewrite Everything. Lose Nothing." -- the observation that rewrites fail because they lose behavioral correctness during transition, because the implicit contracts are trapped inside the implementation. The ribosome layer concept explains why that happens and how to prevent it.
If the identity (DNA) is externalized and the ribosome layer is declared separately, then a rewrite is a ribosome swap. You keep the DNA. You define a new ribosome layer (Go instead of Node, Chi instead of Express, golangci-lint instead of ESLint). You point the agent at both and let it re-translate. The identity survives because it was never coupled to the implementation. The implementation changes because the ribosome layer changed.
Twitter's 2009-2014 migration from Ruby on Rails to Scala was, in retrospect, a ribosome swap performed manually. The identity -- real-time message delivery, social graph consistency, specific semantics of tweets and retweets -- survived the transition. The ribosome layer changed: new language, new runtime, new frameworks, new performance characteristics. Throughput went from 200-300 requests per second per host to 10,000-20,000. Same DNA, different ribosome, different output.
The difference between what Twitter did manually over five years and what becomes possible with a declared ribosome layer is the difference between hand-copying a manuscript and feeding it through a printing press. The content is the same. The production machinery determines the medium.
A master painter needs both canvas and vision
A master painter with the right tools and constraints produces a masterpiece. Hand them oil paints, a quality canvas, a well-lit studio -- and a clear vision of what to paint -- and the result is extraordinary.
Hand them the tools without the vision, and you get technically proficient exercises that say nothing. Hand them the vision without appropriate tools, and you get frustrated genius working against the medium.
The same holds for AI agents generating code. Identity without the ribosome layer produces code that's directionally correct but conventionally wrong. The ribosome layer without identity produces pristine, well-linted code that implements the wrong thing. The combination -- clear identity declaration plus fully specified ribosome layer -- produces code that is both what you intended and how your team builds.
What this looks like in practice
Your team is building a user authentication service.
The identity (DNA) declares:
- Authenticates via OAuth 2.0 with PKCE
- Stores sessions in Redis with 24-hour TTL
- Rate limits at 100 requests per second per user
- All endpoints require structured audit logging
- Depends on: identity-provider, redis-cluster, audit-service
- Consumed by: web-frontend, mobile-api, admin-dashboard
Now apply Ribosome Layer A (Go):
- Chi router for HTTP handling
- sqlc for database queries (type-safe, generated from SQL)
- zerolog for structured logging
- golangci-lint strict mode with errcheck, govet, exhaustive
- 85% unit test coverage minimum
- No function over 50 lines
- Container image under 40MB (distroless base)
- Cold start under 100ms
The agent reads both layers and produces Go code: Chi handlers implementing OAuth 2.0 PKCE flows, sqlc-generated queries, zerolog audit events, tests at 85%+ coverage, every function under 50 lines, passing golangci-lint strict. The container builds to 35MB on distroless.
Now swap to Ribosome Layer B (Rust):
- Axum for HTTP handling
- sqlx for database queries (compile-time verified SQL)
- tracing crate for structured logging
- Clippy pedantic mode, no
unsafeblocks - 80% unit test coverage minimum
- Container image under 20MB (musl static build)
Same identity. The agent produces Rust code: Axum handlers implementing the same OAuth 2.0 PKCE flows, sqlx queries with compile-time verification, tracing spans for audit logging, Clippy pedantic passing. The binary compiles to a static musl build under 15MB.
The behavioral contracts are identical. The audit logs capture the same events. The rate limiting enforces the same thresholds. But every line of implementation is different, because the ribosome layer is different.
The hard parts
Defining ribosome layers cleanly is harder than it sounds. The boundary between "what to build" (identity) and "how to build it" (ribosome) isn't always obvious. Is "use PostgreSQL" an identity decision or a ribosome decision? It depends. If your behavioral contracts include specific PostgreSQL features (advisory locks, LISTEN/NOTIFY, jsonb queries), then the database choice is part of the identity -- it's load-bearing for the contracts. If your contracts are database-agnostic and you're choosing PostgreSQL for operational reasons, it belongs in the ribosome layer.
Cross-cutting concerns blur the line further. Observability requirements might be identity ("all state changes must be auditable") with ribosome-layer implementation details ("use OpenTelemetry with zerolog export"). Getting the split right requires judgment. We're learning where the boundaries fall through work with production teams, and the heuristic that's emerging is: if it survives a rewrite, it's identity. If it changes when you swap languages, it's ribosome layer.
There's also the composition problem. Most real systems don't have a single ribosome layer. A service might use Go for the API layer, Python for the ML pipeline, and TypeScript for the admin dashboard. Each component has its own ribosome layer. We're working through how they compose -- and the biology is suggestive here too: different ribosomes in different cellular compartments (cytoplasm vs. endoplasmic reticulum) produce different classes of proteins from the same genetic instructions.
What to do Monday morning
Start with one service. The one your team rewrites most often, or the one where convention drift causes the most friction.
Write down the implementation constraints that aren't in the DNA. The language. The framework. The linter config. The coverage threshold. The dependency policy. The deployment limits. Everything that determines how code gets written in this specific context. Put it in version control, next to the DNA.
The next time an agent generates code for that service, feed it both layers. You'll see the difference immediately. The code won't just be correct -- it'll be yours. It'll follow your conventions, respect your constraints, and pass your quality gates on the first try instead of the fourth.
Then try the thought experiment: what would it take to swap the ribosome layer? If you had to move this service from Node to Go, what in the identity declaration would stay the same? Everything that stays the same is DNA. Everything that changes is ribosome layer. That mental exercise alone will clarify which decisions are load-bearing and which are medium-dependent.
The industry has spent decades conflating identity and implementation. DNA separates the what from the how. The ribosome layer makes the how explicit, declarative, and swappable. Together, they turn "rewrite the payment service in Go" from a six-month expedition into a specification change and a re-translation.
Ribosomes read instructions, account for the environment, and produce functional output. The biology got there a few billion years ago. We're catching up.
If you're working on the boundary between identity and implementation -- figuring out what persists across rewrites and what changes with the toolchain -- we'd like to compare notes.