Spec-driven development (SDD) is a software engineering paradigm where well-crafted specifications serve as the primary engineering artifact, and AI agents generate code from those specifications. Unlike documentation-driven or waterfall approaches, the specification is not a precursor to the "real work" -- it is the real work, continuously governing what agents build, how they build it, and what constraints they honor.
That definition will need unpacking. But first, a clarification about what we are not talking about.
What SDD is
In traditional development, code is the source of truth. Everything else -- design documents, architecture diagrams, README files -- exists in orbit around the code, and most of it drifts out of orbit within weeks.
Spec-driven development inverts this. The specification is the source of truth. The code is a derived artifact, generated by AI agents working against the spec, and regenerable when the spec changes. The human role shifts from writing code to writing intent: declaring what the software should do, what constraints it must honor, and what contracts it guarantees to its consumers.
As of early 2026, Fortune 10 cloud providers are shipping SDD tooling, GitHub has published spec-first workflows used by hundreds of thousands of developers, and ThoughtWorks has placed the practice on its Technology Radar. The paradigm has crossed from experiment to early discipline.
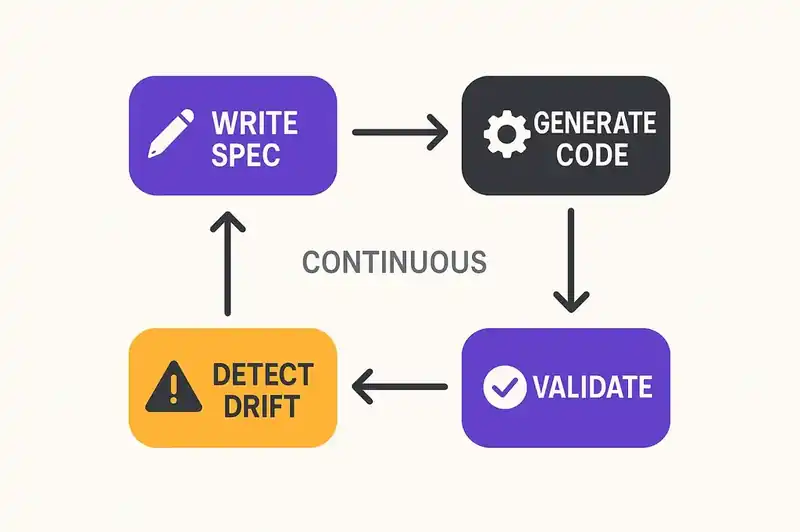
The core loop looks like this:
- A human (or a team) writes a specification: requirements, design decisions, behavioral contracts, constraints.
- An AI agent reads the specification and generates implementation code.
- Validation tooling compares the generated code against the specification.
- Drift is detected and corrected. The spec evolves; the code follows.
Every piece of that loop matters. Remove the specification and you get vibe coding. Remove the validation and you get documentation-driven development. Remove the evolution and you get waterfall. SDD requires all four.
What SDD is not
Naming a paradigm is useful only if you also draw its borders. SDD has been confused with at least three other approaches, and each confusion leads to a different failure mode.
It is not waterfall
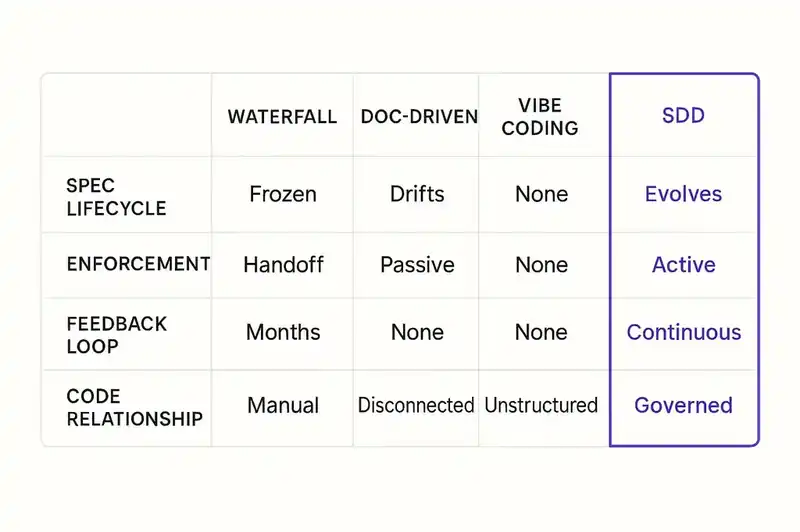
The most common objection, and the least accurate. Waterfall is a sequential process: specify everything upfront, hand the spec to developers, build to the spec, test the output. The spec is frozen. Change is expensive. The feedback loop is months long.
SDD specifications are living artifacts. They evolve continuously. An SDD spec might change three times in a single sprint as the team learns from what agents generate, discovers edge cases, or refines constraints. The specification is versioned, diffed, and reviewed through the same pull request workflow as code. The cadence is iterative, not sequential.
The structural difference: in waterfall, the spec is an input to a one-time process. In SDD, the spec is a persistent governing artifact that the system is continuously reconciled against. It is closer to Terraform than to a requirements document.
It is not documentation-driven development
Documentation-driven development says: write thorough docs, then build. The problem is that documentation is descriptive and passive. It describes what was intended. Nothing enforces it. The code diverges from the docs on day two, and the divergence compounds silently.
SDD specifications are prescriptive and active. They do not describe what was intended; they declare what must be true. Tooling validates code against the spec. Drift is detected, not assumed. The spec is not a reference document someone might consult. It is a constraint surface that agents and CI pipelines operate against.
Augment Code documented this distinction directly: "Most spec-driven tools produce static documents that drift from implementation within hours." The word "hours" matters. The failure mode of documentation-driven development shows up immediately in an AI-assisted workflow because agents generate code fast enough to outrun any passive document.
It is not vibe coding
Less a confusion than a genealogy. Spec-driven development emerged, historically, as a direct response to the failures of vibe coding.
In February 2025, Andrej Karpathy coined "vibe coding" -- the practice of describing what you want to an AI agent, letting it generate code, and not bothering to understand the output. "Forget that the code even exists." It was thrilling for demos and prototypes. It was catastrophic for anything that needed to survive its first week in production.
GitClear's 2025 analysis of 211 million changed lines found that AI-assisted codebases showed significant growth in duplicated blocks and higher code churn compared to pre-AI baselines. The METR study found that experienced developers using AI tools were 19% slower on real tasks while perceiving themselves as 20% faster. A 39-point perception gap. Vibe coding felt productive. It was not.
SDD is vibe coding's structured successor. You still describe intent. The AI still generates code. But the intent is formalized into a specification that persists, evolves, and governs -- rather than evaporating into a chat history that nobody will read again.
Twelve months separated Karpathy coining "vibe coding" and Karpathy declaring it passe in favor of agentic engineering. That is the fastest paradigm shift in modern software history.
The three levels of spec-driven development
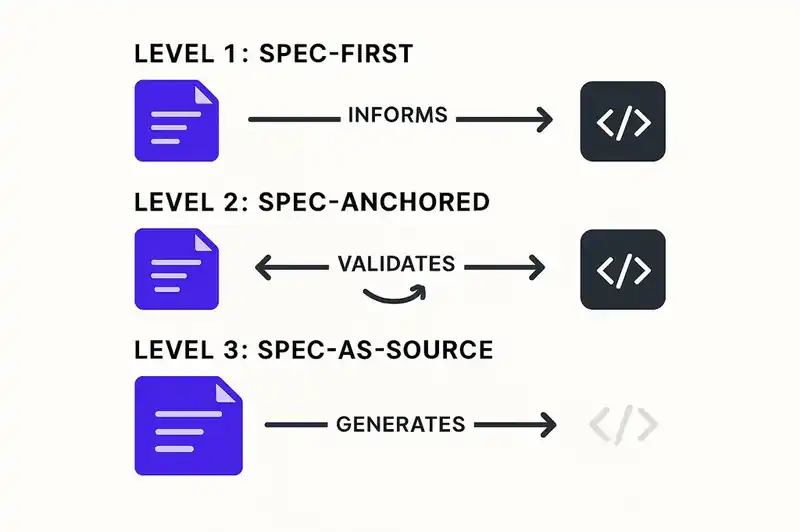
In October 2025, Birgitta Bockeler published an analysis on martinfowler.com that gave the emerging practice its first rigorous taxonomy. Her framework identifies three levels of maturity, each with a different relationship between specifications and code.
Level 1: Spec-first
The specification is written before code generation begins. The agent reads the spec and produces an implementation. This is the entry point -- the simplest form of SDD, and the one most teams adopt first.
At this level, the spec is a planning artifact. You write requirements, design notes, and constraints in structured markdown or a similar format. The agent consumes them as context. The improvement over unstructured prompting is significant: agents produce more consistent, more constrained output when they are working against a persistent spec rather than a conversational prompt.
The limitation is that the spec is still largely passive. It informs the agent's initial generation but does not actively govern ongoing development. Drift happens. It happens slower than without a spec, but it happens.
Kent Beck's "plan.md" approach operates at this level. Write a plan file that declares what you want. Use TDD as a reconciliation mechanism -- the tests verify that the agent's output conforms to the plan. The plan persists across sessions. Beck did not invent spec-first development, but he may have been the first prominent practitioner to formalize why it works with AI agents: the plan gives the agent something to be held accountable to.
Level 2: Spec-anchored
The specification is actively maintained alongside the code, and tooling validates conformance between the two. Drift is detected, not just possible. This is where most of the current tooling operates.
AWS Kiro is the clearest example. Kiro structures work into three linked artifacts: requirements.md (what the software must do), design.md (how it will be built), and tasks.md (the sequenced implementation steps). The agent generates code against these artifacts. When the code diverges from the spec, the divergence is visible. When the spec changes, the agent updates the implementation to match.
GitHub's Spec Kit operates at this level as well: specifications anchor the development process across multiple platforms and agent environments, with the spec serving as the persistent reference point that agents return to.
The advancement over Level 1 is the feedback loop. Spec-anchored development does not just use the spec as input; it uses the spec as a checkpoint. Generated code is compared against declared intent. The delta is surfaced. The human decides whether to update the spec or fix the code.
Level 3: Spec-as-source
The specification is the source code. The implementation is entirely derived. Change the spec, and the system regenerates.
Few teams operate here today, but the direction is clear. InfoQ described this level as a "declarative contract-centric control plane" -- the specification becomes the control surface for the entire system, and implementation is an output of that control surface, not a parallel artifact.
At this level, the relationship between spec and code mirrors the relationship between Terraform configuration and infrastructure. You do not SSH into a server and modify it by hand. You change the declaration, and the reconciliation engine makes reality match. Spec-as-source applies the same principle to application code.
If the spec is truly the source, then code review becomes spec review. Onboarding means reading the spec, not the codebase. Compliance auditing checks the spec, not the implementation. The entire governance model shifts upstream.
We are not there yet. But every major SDD tool is moving in this direction.
Current tools and platforms
SDD tooling consolidated rapidly in the second half of 2025. Three platforms define the current state.
AWS Kiro
Kiro launched in preview in July 2025 and reached general availability in November 2025. Over 100,000 developers used it within the first week of preview, with hundreds of thousands signing up for the waitlist. It's a full IDE (built on VS Code) with a spec-driven workflow baked into the development loop.
Every project begins with three markdown files -- requirements.md, design.md, and tasks.md -- that form a linked specification chain. The agent generates code against these files. The files are versioned, reviewable, and persistent. They survive the coding session. They survive the sprint.
When a Fortune 10 cloud provider builds an entire IDE around a paradigm, the paradigm has institutional backing.
GitHub Spec Kit
GitHub launched Spec Kit in September 2025 with a blog post containing a sentence that would have been unthinkable a year earlier: "Intent is the source of truth." The company that hosts the world's code, that built Copilot to generate code, was saying the code is not the point.
Spec Kit has accumulated tens of thousands of stars on GitHub and supports multiple platforms. It provides a structured specification format that agents across different environments can consume, making the spec portable across tools rather than locked into a single IDE or agent.
GitHub is positioning specifications as a first-class artifact in the development workflow, alongside code, issues, and pull requests.
Tessl
Tessl has raised $125 million to build what it calls an "AI-native software engineering platform." Their approach pushes further toward the spec-as-source level: specifications define the software, and the platform generates and maintains the implementation. A $125 million bet on spec-driven development is a bet that the spec-first workflow is a platform, not a plugin.
The broader ecosystem
Beyond these three, the ecosystem includes Augment Code (which has published some of the sharpest analysis of SDD failure modes), Cursor and Windsurf (which support spec-aware workflows within their AI-native editors), and a growing set of open-source frameworks for spec authoring and validation.
The pattern across all of them: the specification is moving from an optional pre-step to a structural component of the development pipeline.
ThoughtWorks Radar placement
In November 2025, ThoughtWorks Technology Radar Volume 33 placed spec-driven development in the "Assess" ring. For those unfamiliar with the Radar's taxonomy:
- Hold: Proceed with caution.
- Assess: Worth exploring. Understand how it will affect your organization.
- Trial: Worth pursuing. Adopt on a project with manageable risk.
- Adopt: Industry-proven. Use with confidence.
"Assess" means the practice is real, it has demonstrated value, and organizations should actively study it -- but it's not yet mature enough for broad adoption. The Radar is the closest thing the software industry has to an institutional opinion, and it's conservative by design. Practices that reach "Assess" tend to move to "Trial" within 12 to 18 months.
The placement matters because it provides a credible reference point for engineering leaders who need to justify investment in SDD practices and tooling. "ThoughtWorks recommends we assess this" is a different conversation than "I read a blog post."
How SDD connects to Software DNA
Spec-driven development solves the immediate problem: giving AI agents structured intent to work against instead of open-ended prompts. It works. The quality of agent output improves dramatically when agents operate against persistent specifications.
But SDD, as currently practiced, has a scope limitation. The spec governs a single project or service. It answers "what should this service do?" It does not answer "what is this service?" -- its identity, its relationships to other systems, its compliance obligations, its ownership boundaries, the persistent declaration of what it is across teams, tools, and time.
This is the gap that Software DNA addresses. Software DNA is a declarative identity layer that sits beneath and around specifications. If the spec is the blueprint for what to build right now, the DNA is the genome -- the persistent declaration of what the software is, what constraints it honors, and how it relates to everything else in the ecosystem.
Consider the practical scenario: an AI agent is working against a spec for your payment service. The spec says to add a refund endpoint. The agent generates the endpoint. But does the agent know that the payment service has a data residency constraint requiring EU-region storage? That the service has an SLO of P99 under 50ms? That changing the API contract will break three downstream consumers? That a compliance audit requires every data mutation to be logged?
A spec might contain some of this. A comprehensive Software DNA declaration contains all of it, in a machine-readable format that every agent, every CI pipeline, and every governance tool can query. The spec tells the agent what to build. The DNA tells the agent who the software is.
SDD and Software DNA are not competing concepts. They are layers. SDD provides the methodology. Software DNA provides the persistent identity that the methodology operates against.
Getting started: practical first steps
You do not need a new IDE or a platform to start practicing spec-driven development. The paradigm scales down to a single project and a markdown file.
Step 1: Write a spec before your next feature
Before your next feature, open a markdown file and write three things:
- What it must do. Not a user story. Not a vague requirement. Behavioral contracts. "Given X input, the system returns Y with status code Z." Specific enough that you could verify conformance by reading the output.
- What it must not do. Boundaries matter more than features when you are governing an agent. "This endpoint does not create user accounts." "This service does not make external API calls." Agents are enthusiastic. They will add capabilities you did not ask for unless you explicitly constrain them.
- What constraints it must honor. Performance targets. Security requirements. Dependency restrictions. Anything that is true regardless of what feature is being built.
Hand the spec to your AI agent alongside your prompt. Compare the output to the spec. Note where they diverge. That is your first spec-driven development cycle.
Step 2: Make the spec persistent
After the feature ships, do not delete the spec. Keep it in the repository, next to the code. Update it when the code changes. This is what separates spec-first from spec-anchored: the spec does not get consumed and discarded. It persists.
Create a specs/ directory or adopt a convention like Kiro's requirements.md / design.md / tasks.md structure. The format matters less than the persistence. A spec that lives in a Slack thread is not a spec. A spec in a versioned file in the repository is.
Step 3: Add validation
Start simple. After an agent generates code, manually compare the output to the spec. Look for drift: features you did not ask for, constraints that were ignored, contracts that were changed without changing the spec.
Then automate. Write tests that verify the behavioral contracts in your spec. If your spec says the endpoint returns 409 for duplicate emails, write a test that checks for 409 on duplicate emails. The test is derived from the spec, not from the implementation. Beck's insight: TDD becomes a reconciliation mechanism between spec and code.
Step 4: Evaluate the tooling
Once you have experienced the pattern manually, evaluate whether dedicated tooling would help. Try Kiro for a project. Explore Spec Kit for cross-platform spec portability. Read how to write specs that AI agents actually follow for detailed templates and patterns.
The tooling is maturing fast. What requires manual effort today will be automated within months. But the practice -- writing specs, governing agents against them, detecting drift -- that's the durable skill, regardless of which tool you use.
Step 5: Expand the scope
Once spec-driven development works for a single project, extend it. Write specs for services that interact. Declare the contracts between them. Map the dependencies. This is where SDD starts to approach Software DNA territory: the specifications are not just governing individual projects but describing a system.
FAQ
What is spec-driven development?
Spec-driven development (SDD) is a software engineering paradigm where well-crafted specifications serve as the primary engineering artifact, and AI agents generate code from those specifications. The spec is the source of truth; the code is a derived artifact. The practice emerged in 2025 as a structured response to the quality problems caused by unstructured AI code generation.
How is spec-driven development different from waterfall?
Waterfall uses specifications as a one-time input to a sequential process. The spec is written upfront, frozen, and handed off. Spec-driven development treats specifications as living, versioned artifacts that evolve continuously alongside the code. The spec is iterated on through pull requests, refined as the team learns, and actively enforced by tooling. The cadence is iterative, not sequential.
How is spec-driven development different from vibe coding?
Vibe coding is unstructured: you describe what you want to an AI agent conversationally and accept whatever it generates. SDD formalizes that intent into a persistent specification with behavioral contracts, constraints, and boundaries. The agent is held accountable to the spec, and drift between spec and code is detected and corrected. Vibe coding optimizes for speed. SDD optimizes for speed with governance.
What tools support spec-driven development?
The major platforms as of early 2026 are AWS Kiro (a full IDE with a spec-driven workflow), GitHub Spec Kit (a cross-platform specification format with roughly 40,000 GitHub stars), and Tessl (an AI-native engineering platform with $125 million in funding). Augment Code, Cursor, and Windsurf also support spec-aware workflows. The ecosystem is maturing rapidly.
Is spec-driven development on the ThoughtWorks Technology Radar?
Yes. ThoughtWorks Technology Radar Volume 33 (November 2025) placed spec-driven development in the "Assess" ring, recommending that organizations actively explore and understand the practice. "Assess" is the second ring from the outside, indicating that the practice has demonstrated value but is not yet mature enough for broad adoption.
What is the difference between spec-driven development and Software DNA?
Spec-driven development is a methodology: write specs, generate code against them, validate conformance. Software DNA is a persistent identity layer that declares what a piece of software is -- its purpose, boundaries, behavioral contracts, constraints, and relationships to other systems. SDD governs how individual features are built. Software DNA governs what the software is across features, teams, and time. They are complementary layers, not competing concepts.
Who is behind spec-driven development?
SDD is not a single company's invention. It emerged from converging insights: Kent Beck's plan-file approach to AI-assisted TDD, Birgitta Bockeler's three-level maturity analysis on martinfowler.com, AWS's Kiro IDE, GitHub's Spec Kit, and the broader recognition that AI code generation requires structured intent to produce reliable output. An industry-wide response, not a vendor initiative.
How do I start with spec-driven development?
Start with a markdown file. Before your next feature, write behavioral contracts (given X, then Y), explicit boundaries (what the feature must not do), and constraints (performance targets, security requirements). Hand the spec to your AI agent. Compare the output to the spec. Keep the spec in your repository and update it when the code changes. This gets you to Level 1 (spec-first) with zero tooling investment.
What is unsettled
Spec-driven development is real. It solves a genuine problem, the quality collapse that happens when AI agents generate code without structured intent. The tooling is maturing. The institutional validation is there. The trajectory from ThoughtWorks "Assess" to "Trial" to "Adopt" looks probable, not speculative.
The unsettled parts are concrete. The specification formats are not standardized. Kiro uses one structure. Spec Kit uses another. The ecosystem has not converged on a common format the way it converged on OpenAPI for REST APIs or HCL for infrastructure. That will be a friction point for teams that use multiple tools or switch platforms.
The reconciliation tooling is immature. Detecting drift between spec and code is still partly manual for most teams. The automated validation that exists is good for API contracts and behavioral tests, but thin for architectural constraints, performance SLOs, and compliance obligations. This gap will close. It has not closed yet.
The hardest problem is cultural. Spec-driven development asks engineers to invest time in specification before they see code. That investment pays off, but it feels slower at the start. Teams that measure productivity by lines of code generated per hour will resist SDD because it optimizes for a different metric: lines of code that are correct the first time.
None of these are reasons to wait. The alternative — unstructured AI generation at increasing speed and scale — has a known failure mode, and the data on that failure mode is unambiguous.
Write the spec. Govern the agent. Keep the spec alive. The code will follow.
The specs are real. The reconciliation is not yet standard. We're building the layer that makes declared intent enforceable across agents, tools, and time.