
Every codebase in production right now has a gap between what the software should be and what it is.
Not a bug. Not a missing feature. A structural delta between the intent that justified building the thing and the reality of what actually runs. Your payment service should enforce idempotency on every endpoint, but three of them don't. Your data pipeline should honor GDPR deletion requests within 30 days, but two downstream caches weren't included in the purge logic. Your API should follow the versioning convention your team agreed on in Q3, but 40% of endpoints still use the old pattern.
You know this gap exists. You've never been able to see it. Not the shape of it, not the size of it, not the exact files and functions where intent and implementation diverge. So you do what every engineering organization does: you pretend the code is complete, ship the feature, and move on.
This worked when humans wrote all the code and held the context in their heads. It does not work when agents generate 41% of committed code (GitClear, 2025 analysis of 211 million changed lines) and the person who understood the original intent left two sprints ago.
The industry's current answer is context engineering: feed the agent better information so it produces better output. That's necessary. It's also treating a symptom. The actual problem is that nobody defined what the software is in a way that persists across sessions, agents, and team members. Without that definition, every agent interaction is a fresh guess. With it, you get a different development model. The gap between intent and implementation becomes visible, quantifiable, and continuously closing.
That model requires identity engineering. It changes how teams are structured, how work flows, and where humans spend their time.
We already tried a human identity layer. It was called product management.
Product managers were supposed to solve this. They hold the "why" behind the software. They maintain the vision, prioritize what matters, arbitrate between competing concerns. In theory, the PM is the living identity layer — the person who knows what the software is supposed to be and makes sure every feature serves that identity.
In practice, that identity lives in their head. Some of it makes it into PRDs, Notion docs, Jira epics. But the documents capture the what (build this feature, solve this problem, hit this metric). They rarely capture the full why: the trade-offs considered and rejected, the constraints that shaped the decision, the relationships between features that only make sense because one person held the whole picture.
When that PM leaves, the product doesn't just lose a contributor. It loses the reasoning behind hundreds of decisions. Features start drifting because nobody remembers why they were scoped that way. New features get built that contradict boundaries the PM held in their head but never wrote down. Priorities shift because the context that informed them walked out the door.
This isn't a failure of product management. It's a failure of medium. Human memory is lossy, non-transferable, and unavailable at 3 AM when an agent is generating code. The best PM in the world can only look at a problem through their own context window: a company goal, a recent conversation with a customer, a stakeholder's priorities that got extra weight because the meeting happened yesterday instead of last month.
We tolerated this because there was no alternative. The PM's head was the best identity layer we had.
Specs: already one layer removed, and they still drift
Specifications are the output of that human identity layer, and they're already one step removed from the actual intent. The PM's understanding gets compressed into a document. The document gets interpreted by engineers. The engineers build something that approximates the interpretation. Three layers of lossy compression between business intent and running code.
Then the spec drifts.
Augment Code's analysis of spec-driven development found the core problem: "Reality changes faster than specs do." Tight deadlines turn spec updates into low-priority tasks. Decisions made in Slack don't make it back to the document. Edge cases discovered during implementation get handled in code but never reflected in the spec.
This was always a problem. It becomes a different kind of problem when agents are reading the spec. A stale design doc might mislead the next engineer who reads it. A stale spec misleads agents that don't know any better — they execute plans that no longer match reality, confidently, without flagging anything is wrong. The agent doesn't second-guess. It doesn't check whether the spec still reflects what the codebase actually does. It builds what the spec says, even when the spec is wrong.
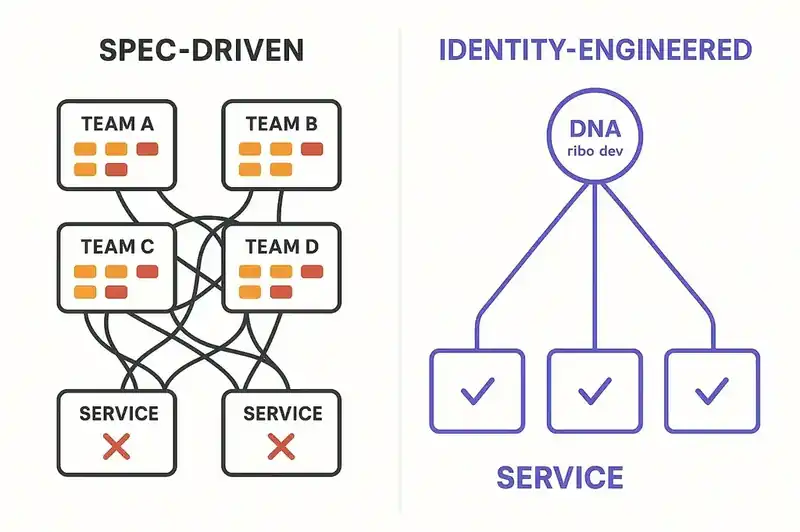
Spec-driven development answers the question "what should we build next?" It does not answer the question "what is this software?" Those are different questions. The first produces a document that's useful until the feature ships. The second requires a persistent layer that's useful for the life of the system.
Identity engineering: the DNA is already there
Identity engineering starts from a different premise. The software already has an identity: a set of purposes, constraints, contracts, and relationships that define what it is. The problem isn't inventing that identity. It's declaring it in a form that persists across sessions, agents, and personnel changes.
A declared identity layer (what we call Software DNA) isn't a spec for the next feature. It's a persistent, machine-readable, version-controlled declaration of what the software is, what it honors, and what it refuses to become. It encodes purpose and boundaries ("this service processes payments; it does not manage user profiles"), behavioral contracts ("this endpoint guarantees idempotency"), constraints ("all PII access requires audit logging"), and system relationships ("this service depends on the auth service and is consumed by the billing dashboard").
Once you have that declaration, the gap becomes visible.
For the first time, you can diff the declared identity against the actual implementation. Not in the abstract — concretely, across every file, endpoint, and dependency. The payment service declares idempotency on all endpoints. Three endpoints don't implement it. That's a measurable delta. The data pipeline declares GDPR compliance. Two caches aren't covered. That's a quantifiable gap.
This changes the dynamic. You can see exactly where the code falls short. And rather than relying on humans to find and close those gaps manually, you can point agents at them.
If this sounds familiar, it should. Model Driven Architecture promised something similar in the 2000s: declare the system, generate the code. It failed because generation was brittle, the abstractions couldn't handle real-world complexity, and the economics didn't work. Identity engineering is structurally different. It doesn't generate code from declarations — it reconciles code against them, continuously, using LLMs that handle ambiguity instead of code generators that don't. And the forcing function that MDA never had — near-zero marginal cost of code generation — is here now.
Cross-cutting concerns: declare once, propagate everywhere
Say your company decides to pursue SOC 2 Type II certification. In a spec-driven world, this becomes a project. Someone audits the codebase. Multiple teams file tickets. Each team interprets the requirements differently. Compliance touches engineering, HR, customer service, and executive leadership. ComplyJet estimates 100 to 200 hours of internal effort and $5,000 to $20,000 in internal cost per certification cycle, and that's before audit fees. Changes scatter across teams, timelines, and backlogs. Six months later, you discover that two services never implemented the required access logging because the tickets fell through the cracks.
In an identity-engineered world, SOC 2 requirements become constraints in the identity layer. You declare them once: "All data access requires audit logging. All authentication events require retention for 90 days. All API endpoints require rate limiting." The declaration is a decision. It goes through review. It gets committed.
Now every agent in the system sees that constraint. New features get built with audit logging from the start, because the agent reads the identity layer before generating code. Background agents scan the existing codebase, find the delta between declared constraints and current implementation, and start closing it. CI agents validate every incoming change against the constraint. The requirement propagates through structure, not through ticket management.
The pattern applies to any cross-cutting concern: GDPR data handling, EU AI Act compliance (enforcement begins August 2, 2026), architectural standards, security policies, performance SLOs. Each one is a mutation to the identity layer. Each mutation propagates automatically through every agent that reads it.
To be clear: compliance automation tools like Vanta and Drata already handle evidence collection and control monitoring well. Identity engineering operates at a different layer: ensuring your code actually implements the constraints those tools verify you have. One checks the box. The other changes the code. They're complementary.
The inverse is also true. When a constraint is removed from the identity layer (a regulation changed, a business decision shifted), agents propagate that removal too. Code that existed only to satisfy a now-removed constraint gets identified and cleaned up. Features gated behind a now-irrelevant policy get simplified.
The problems that quietly disappear
Identity engineering solves problems you've been working around so long you stopped noticing them.
Documentation writes itself. Your identity layer is the documentation. Not a separate artifact that someone maintains, but the authoritative declaration of what the software does, what it honors, and how it connects to everything else. When a new engineer joins, they don't need to find the right Confluence page or corner the senior developer who "just knows." They read the identity layer. When the VP of Sales asks "does our platform support X?" the answer is queryable, not buried in someone's Slack history. "Documentation is always out of date" stops being true, because the identity layer isn't describing the software after the fact. It's defining it before the fact, and reconciliation keeps the two aligned.
Non-engineers stop being blocked by engineers. Today, when a product manager wants to understand how a compliance requirement affects the codebase, they file a ticket and wait for an engineer to investigate. When a sales team needs to know which features depend on a specific integration, they ask around. When legal needs to assess the impact of a new regulation, they schedule a meeting.
With a queryable identity layer, those questions become self-serve. A product leader explores the dependency graph between features. A compliance officer sees which services a proposed regulatory change affects. A business stakeholder traces the relationship between a customer-facing feature and its underlying constraints, without writing a single line of code, without waiting for engineering bandwidth. The identity layer is the shared language between technical and non-technical parts of the organization.
You can watch the software change in response to decisions. This is the one that changes how it feels to lead a product organization. Today, you make a strategic decision ("we're going to prioritize reliability over new features this quarter") and then you hope it translates through planning, through tickets, through sprints, through code. You find out months later whether it actually happened.
With identity engineering, you add a constraint to the identity layer: tighten the SLO, add a resilience requirement, raise the bar on error handling. Then you watch the delta. How many files need to change. How fast agents are closing the gap. Which services are lagging. Strategic decisions become observable. The feedback loop between "we decided this" and "this is actually happening in the code" shrinks from months to days.
Cross-cutting compliance becomes a mutation, not a migration. The SOC 2 example above is one instance. Think about what this means for compliance in general. ISO 27001. HIPAA. PCI DSS. EU AI Act. Each of these is a set of constraints that touches code across your entire system. Today, each one is a project: a months-long initiative with its own project manager, its own Jira board, its own collection of tickets scattered across teams. With identity engineering, each one is a set of constraints you commit to the identity layer. You introduce the standard. You watch the software morph to meet it. The gap is visible. The convergence is measurable. Compliance stops being a project and becomes a property of the system.
The operating model: who does what when the code writes itself
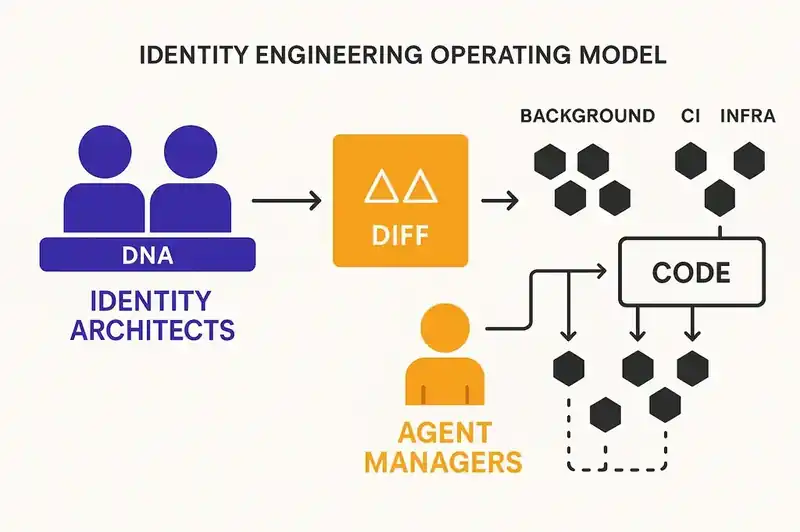
If agents are writing the code, what are the humans doing?
Anthropic's 2026 Agentic Coding Trends Report found that developers use AI in roughly 60% of their work but can "fully delegate" only 0 to 20% of tasks. They called this the delegation gap. It is the central problem of the current era. The gap exists because agents don't know what the software is supposed to be. They can generate code. They can't judge whether the code serves the software's identity.
Identity engineering closes the delegation gap by giving agents the judgment layer they're missing. And in doing so, it redefines what humans do.
Identity architects. This role absorbs most of what product managers, staff engineers, and technical leads do today, but focused upstream. Identity architects decide what goes into the DNA layer. Not writing code. Not writing specs. Deciding what the software is: its purpose, its boundaries, its constraints, its contracts.
This is where the hardest thinking happens. An identity architect proposing a new constraint uses AI to model the impact: which services are affected, what code needs to change, what the dependency chain looks like, what the cost will be in tokens and time. They're making a case for a change to the software's identity the way a geneticist would evaluate a mutation, understanding the downstream effects before committing.
This is also where non-technical contributors find their footing. Everyone has been asking "where do I fit if I don't write code?" You're the architect of what matters. You understand the business, the customer, the regulatory environment. You decide what the software should honor. The technical implementation is downstream of that decision. Your job is to make the identity right. The agents' job is to make the code match.
A fair objection: identity engineering doesn't replace product discovery. If the identity is wrong, you converge faster toward the wrong destination. The identity layer captures the output of discovery, not the discovery itself. It's versioned for exactly this reason — it changes as you learn. That's what makes the humans defining it the most critical role in the system.
Agent managers. A new operational role. Less "writing code" and more "reading diffs, verifying compliance, tuning agent behavior." They oversee the agents that implement against the identity layer. They watch the delta between declared identity and actual implementation. They intervene when agents make choices that are locally correct but systemically wrong. They refine configurations based on what the reconciliation loop reveals.
Anthropic's report found that engineers delegate tasks that are "easily verifiable" and keep "conceptually difficult or design-dependent" work for themselves. Agent managers sit at exactly that boundary. They don't do the implementation. They verify that the implementation serves the identity.
Background agents. These run continuously, outside of any feature development cycle. A new compliance constraint gets added to the DNA layer. Background agents scan the codebase, identify every file and function that doesn't comply, and start generating changes. A deprecated feature gets marked for removal in the identity layer. Background agents trace every reference, every integration point, and produce a removal plan.
This is where the completeness fallacy gets addressed. The code was never complete. There were always gaps between intent and implementation, scattered across files, entry points, edge cases. Background agents make those gaps visible and start closing them. Your token spend is the speed at which you catch up to your own declared identity.
CI agents. Today, CI validates that the code builds and the tests pass. In an identity-engineered model, CI becomes multi-dimensional. Different agents evaluate the same code change through different slices of the identity layer:
- A security agent checks the change against declared security constraints
- An infrastructure agent evaluates scaling implications based on declared performance SLOs
- A compliance agent validates against regulatory constraints in the identity layer
- A quality agent checks architectural consistency against declared patterns
- An impact analysis agent traces the change through declared system relationships
Each agent pulls from the same identity layer but reads a different subset. The code change gets evaluated from multiple perspectives simultaneously, each grounded in the persistent declaration of what the software is supposed to be. A distinction that matters: the identity layer validates intent conformance, not code quality. Test suites, security scanning, and code review remain essential. The identity layer tells agents what to build. Existing quality tooling verifies they built it safely.
Infrastructure agents. Monitoring production, but with identity awareness. They know what the software declared it must honor: which SLOs matter, which data flows are compliance-sensitive, which services are critical path. Alerts get prioritized based on identity, not just severity. A latency spike on a service that declared a 99.9% SLO matters more than the same spike on an internal tool that declared best-effort availability.
The economics: why this is cheaper than what you're doing now
The cost model for identity engineering inverts the current economics of AI-assisted development.
Right now, organizations face what the industry calls the LLM cost paradox: token prices drop 10x annually for equivalent capability, but AI bills keep climbing because usage scales faster than prices fall. Frontier reasoning models command $5 to $25 per million output tokens. Claude Opus runs $25, GPT-5 sits at $10. Fast execution models run 50 to 100x cheaper: Claude Haiku at $5 per million output tokens, GPT-5 Nano at $0.40. The spread between "think hard" and "just execute" is enormous.
Identity engineering turns this price disparity into an architectural advantage.
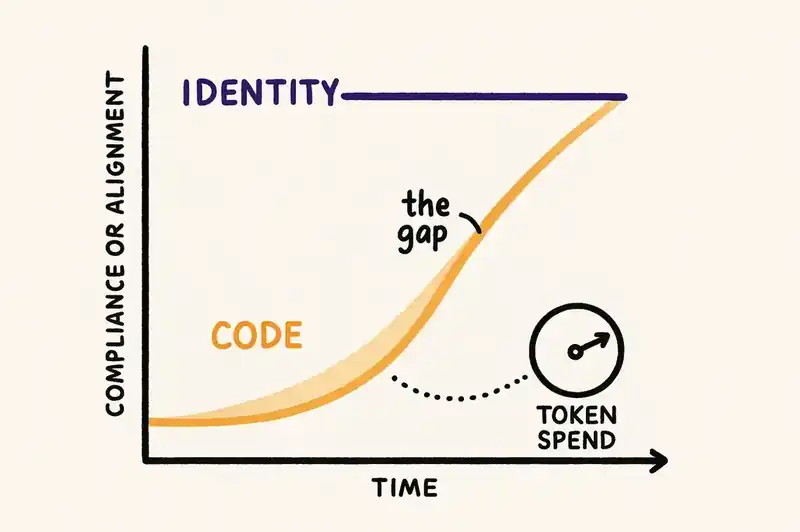
Expensive models for identity decisions. When a human proposes a change to the identity layer (a new constraint, a modified contract, a boundary shift), the impact analysis should use the most capable model available. This is where judgment matters. The model needs to trace dependencies, evaluate trade-offs, surface unintended consequences. You want the reasoning model here. And because identity changes are infrequent relative to code changes, the cost is manageable.
Cheap models for implementation. Once the identity is declared, agents implementing against it don't need frontier reasoning. The identity constrains the output. A fast, inexpensive model iterating against clear constraints, validated by reconciliation checks, produces better results than an expensive model guessing at unstated intent. Companies already using cascading model strategies report 60 to 87% cost reduction by routing 90% of queries to economical models and reserving expensive models for the 10% that require advanced reasoning.
Token spend as a velocity variable. In this model, how fast you close the gap between declared identity and current implementation is a direct function of token spend. Want to catch up to your SOC 2 constraints faster? Allocate more tokens to background agents. Want new features to ship without identity drift? Allocate more tokens to CI agents. The relationship between spend and outcome becomes measurable and tunable — and which diffs to prioritize becomes a real planning discipline, not a backlog guessing game.
Multiple cheap passes beat one expensive pass. Because the identity layer defines what "correct" means, you can let cheap models make many changes in parallel, then validate each against the identity layer. A wrong change gets caught by the reconciliation check, not by an expensive model trying to get it right the first time. Spec-driven development doesn't have this property. A faulty spec means everything downstream drifts, and the spec itself goes stale. The identity layer doesn't go stale because agents are continuously reconciling against it.
The cognitive limit nobody talks about
Even the best product manager looks at a problem through a subset of context. A company OKR drives extra focus on performance. A recent customer escalation biases toward reliability. A board presentation next week pulls attention toward features that demo well. These aren't failures of judgment. They're the natural constraints of human cognition. Humans have context windows too.
The 2025 DORA Report found something that illustrates this at scale: AI coding assistants boost individual output (21% more tasks completed, 98% more pull requests merged), but organizational delivery metrics stay flat. Individual developers get faster. The organization doesn't. DORA is right that this is an organizational problem, and identity engineering is one piece of the organizational infrastructure that addresses it — alongside CI/CD maturity, value stream management, and review processes. It targets the specific gap those other capabilities can't: the absence of a persistent definition of what the software is supposed to be.
Identity engineering addresses this by letting agents do what humans can't: look at a single change through multiple lenses simultaneously. Security. Compliance. Performance. Business logic. Each lens draws from the relevant slice of the identity layer. No single person, no matter how experienced, holds all of those concerns in their head for every change. Agents can, because the concerns are declared in a persistent layer they can query.
Over time, this compounds. The system builds a history of every reconciliation: every gap found, every delta closed, every constraint propagated. Technical managers start refining the identity based on what the delta reveals about the codebase's actual gaps. The product organization stops flying blind. They can see exactly where the software falls short of its declared identity, and they can prioritize based on the size and impact of the gap, not on whoever spoke loudest in the last planning meeting.
The full loop: what this looks like in practice
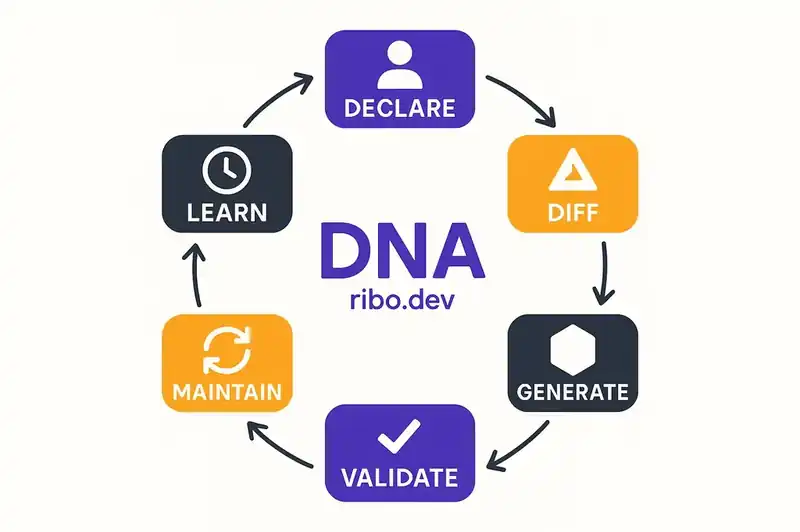
Here is the operating model, end to end.
Humans interact with the identity layer. They declare what the software is, using AI to model the consequences. A product leader proposes adding a constraint: "All user-facing API responses must include structured error codes." Before committing that identity change, AI models the impact. 47 endpoints affected. 12 already compliant. Estimated 1.5 million tokens to reconcile the remaining 35 at current model pricing. The decision to commit is human. The impact analysis is machine.
Agents see the diff. The moment an identity change is committed, agents can diff the declared state against the actual implementation. This is the reconciliation loop, the same pattern that made Terraform and Kubernetes work for infrastructure, applied to the software itself. Agents identify every file, function, and endpoint where the implementation doesn't match the identity. Token spend determines how fast the gap closes.
New features pull from identity. When an agent starts generating a new feature, it reads the current identity layer first. Every constraint, every contract, every boundary is present in the generation context. The feature is built compliant from the start. No drift. No retroactive compliance tickets. The cost of compliance is paid at generation time, which is the cheapest possible moment.
CI validates from identity. Every pull request gets evaluated by specialized agents, each reading a different slice of the identity layer. The security agent sees security constraints. The compliance agent sees regulatory requirements. The architecture agent sees structural boundaries. A single code change gets N evaluations, each grounded in the persistent declaration of what the software must honor.
Background agents maintain. Between feature cycles, agents watch the identity layer for changes and propagate them. A constraint gets added; agents start reconciling. A constraint gets removed; agents clean up the code that existed only to satisfy it. Features declared deprecated in the identity layer get traced and scheduled for removal. The codebase converges toward its declared identity continuously, not just during sprints.
History accumulates. Every reconciliation, every diff, every delta closed gets recorded. The system gets smarter about what typically needs to change when a particular kind of identity mutation happens. Technical managers see patterns: "Every time we add a compliance constraint, these three services take the longest to reconcile because of their architectural debt." That insight drives infrastructure investment. The identity layer is both a declaration of what the software is and a diagnostic tool for what's hardest to change.
This operating model requires infrastructure
The operating model described in this article does not work with documents in a /specs folder. It does not work with Notion wikis. It does not work with context files auto-generated by an AI tool.
It requires infrastructure. A persistent, machine-readable, version-controlled, queryable identity layer that agents can read before generating, that CI can validate against, and that reconciliation loops can diff against the actual codebase. It needs governance: different approval paths for identity changes vs. code changes. It needs observability: the ability to see the delta, track its closure, and measure the cost of reconciliation. It needs enforcement: violations that fail the build, not the code review.
The biological metaphor is structural, not decorative. DNA encodes what to build without specifying how to fold the resulting proteins. Ribosomes read the instructions and produce functional output. The DNA persists across generations. Individual cells get replaced constantly. The organism maintains its identity.
Software DNA encodes what the software is. Agents — the ribosomes — read the identity and produce functional code. The code can be rewritten, refactored, or replaced entirely. The identity survives.
This infrastructure does not exist yet. The tools for context engineering are maturing rapidly: RAG, MCP, memory systems, tool orchestration. But context engineering optimizes the query. Someone has to build the schema. Without the schema, every query is a guess. With it, every agent in the system works from the same persistent truth, and the operating model described in this article becomes possible.
What is still hard
The identity layer is only as good as the humans defining it. Garbage in, garbage out applies at the identity level just as much as at the code level. A poorly declared constraint will be faithfully enforced across the entire codebase, making the mess consistent rather than random, but still a mess. The rigor agents bring is in implementation. The rigor humans bring is in deciding what goes into the identity. That is a different skill from writing code, and the industry has not developed it yet.
Reconciliation is probabilistic, not deterministic. LLM-based checking catches drift the way a good code reviewer catches architectural violations — heuristically, not formally. That is better than the current state of zero reconciliation, but teams should expect the tooling to sharpen as reconciliation data accumulates.
Organizational adoption is the real bottleneck. The technology for persistent identity layers, reconciliation loops, and multi-agent validation is buildable today. Convincing an engineering organization to change how it thinks about software, from "what should we build next?" to "what is this software?", is a harder sell. It requires a shift in planning, in roles, in how teams measure progress. Not every organization is ready.
The teams that define what their software is — persistently, declaratively, in a form that machines can read and enforce — will outperform the teams that only define what to build next. The gap between intent and implementation will stop being invisible. The operating model will shift from "hire more engineers to write more code" to "declare the identity and let agents converge toward it."
The question is not whether this shift happens. It is whether you are the one defining the identity, or still pretending the code is complete.
The scarce resource is deciding, not typing. We're building the tooling that makes those decisions persistent, queryable, and enforceable across every agent on the team.