
You've read the pitch. You understand that software has a structural gap between intent and implementation, that a declared identity layer makes the gap visible, and that agents can close it continuously. The concept makes sense.
Now the question: what does this actually look like on a Tuesday morning?
Not the technology. The organization. Who reports to whom. What meetings disappear. How the VP of Product spends her afternoon. What the compliance team does instead of auditing spreadsheets. Where engineers focus when agents are writing the application code.
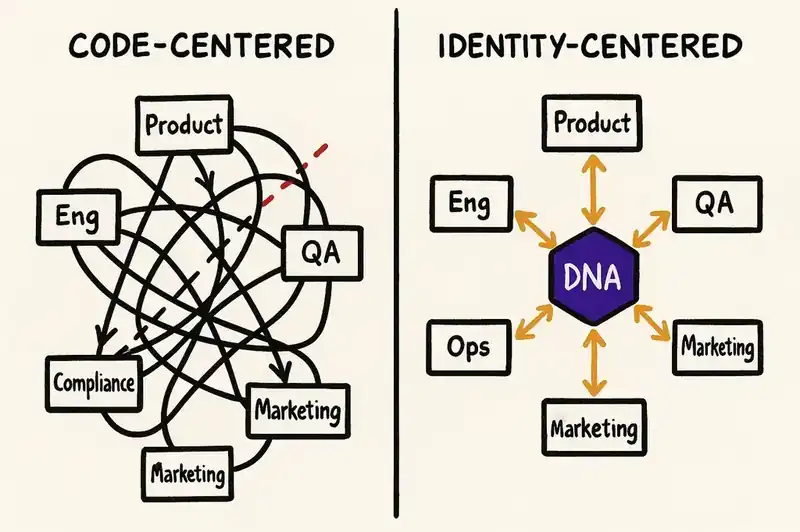
The answer is a structurally different operating model. The traditional org was designed around code production: PMs decide, engineers build, QA tests, ops runs. An identity-first org is designed around trust production. Every function, from product to compliance to support, contributes to or operates from the identity layer. The roles are genuinely different. Humans engage with each other and with customers to build understanding, decide what belongs in the DNA, and manage how efficiently agents converge toward it.
The center shifts
Draw a circle in the middle of a whiteboard. In the traditional org, that circle is labeled "Code." Everything radiates outward from it. Product feeds requirements into code. Engineering produces code. QA validates code. Ops deploys and monitors code. Marketing describes what the code does. Support troubleshoots what the code broke. Code is the artifact that gets produced, reviewed, deployed, and monitored. It is the gravitational center of the organization.
Now erase the label and write "Identity."
The identity layer (the persistent, version-controlled declaration of what your software is, what it honors, and what it refuses to become) sits at the center. Every function radiates outward from it, contributing to or consuming from the layer. Product proposes mutations to the identity. Engineering builds the infrastructure that makes identity-driven development possible. Compliance adds regulatory constraints directly to the layer. Marketing reads the layer to understand what the product actually does. Support queries it to answer customer questions. Ops monitors whether the running system converges with the declared identity.
Code still gets produced. Agents produce it. But the human energy goes into defining and evolving the identity. The organizational gravity shifts from "what did we ship?" to "what did we declare, and how close is the system to honoring it?"
Trust builders
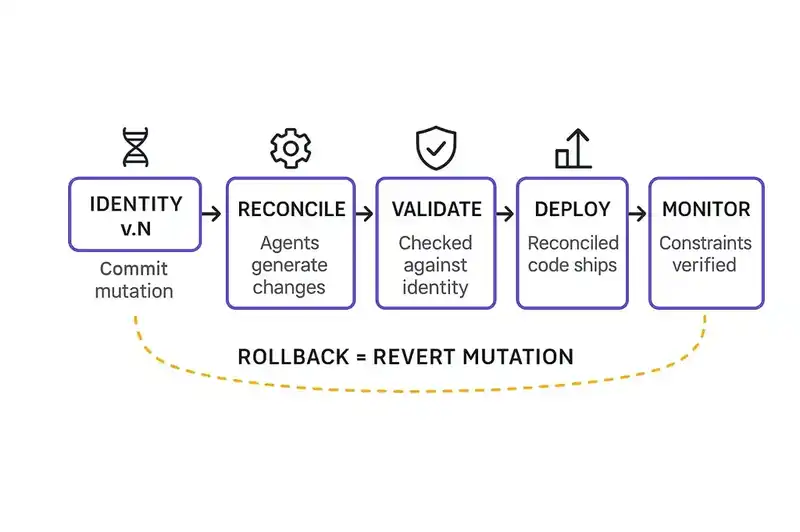
In the traditional model, product managers, researchers, and customer-facing teams produce tickets, PRDs, and roadmap slides. In an identity-first org, they produce something different: proposed identity mutations.
Trust builders are the humans who engage with customers, each other, and the market to understand what the software should become. They run product discovery. They conduct customer research. They watch competitors and the regulatory horizon. This is the same work that good product organizations do today. The difference is where the output lands.
Instead of writing a PRD and filing tickets for engineering, a trust builder proposes a change to the identity layer. "We learned from enterprise customers that data residency is a hard requirement, not a preference. The identity should declare region-aware data storage as a constraint on all services that handle customer PII." That proposal includes the reasoning. It references the customer conversations, the competitive analysis, the regulatory context. It is a case for a mutation, not a request for a feature.
Before the mutation gets committed, AI models the downstream impact. Which services are affected. What code needs to change. What the estimated reconciliation cost looks like in tokens and time. The trust builder sees the consequences of the proposed change before anyone debates whether to make it. Discovery still drives the decision, the identity layer captures what was learned, not the learning itself.
Benefit: Product decisions become observable and debatable before they propagate, not after the code ships.
Identity stewards
Who decides what actually goes into the DNA layer? Identity stewards are the cross-functional humans who own the question: "What should this software be?"
Stewards are drawn from product, engineering, and domain expertise. They understand the business intent and the technical implications well enough to evaluate a proposed mutation. When a trust builder proposes adding a data residency constraint, stewards debate the trade-offs. They model the downstream effects: how many services need to change, what contracts break, whether the constraint conflicts with existing declarations. They review proposed mutations the way a good architecture review board reviews design proposals -- except the review is about identity, not implementation.
This is a review process, not a committee that meets monthly. It runs on every identity change, scaled to the size of the mutation. A small constraint addition might need one steward's approval. A fundamental shift in the software's declared purpose goes through the full group, with AI-generated impact analysis informing the discussion.
The critical property: the identity layer is version-controlled. Every mutation is a commit. Every commit has a review trail. When a steward who understood the original reasoning leaves the company, the reasoning is still there -- in the mutation history, in the review comments, in the impact analysis that informed the decision.
Benefit: Intent survives personnel changes. The "why" behind every declaration lives in the layer, not in someone's memory.
Convergence operators
The identity layer declares what the software should be. Agents reconcile the code toward it. Convergence operators are the humans who manage the space between.
They prioritize which divergences to close first, using the framework from prioritizing the delta: risk-weighted, cost-estimated, dependency-ordered. A compliance gap with a regulatory deadline goes before an internal style inconsistency. A cheap fix that closes a high-risk gap goes before an expensive refactor with low stakes. The ordering is judgment, not formula.
They monitor agent behavior. They catch over-enforcement -- an agent applying a security logging constraint to a health-check endpoint that processes no user data. They tune configurations: which constraints get aggressive reconciliation, which get conservative treatment, how much of the weekly token budget goes to closing compliance gaps versus architectural cleanup.
They watch the convergence charts. The software is never done, so the gap between identity and implementation is always non-zero. Convergence operators manage the rate at which the gap closes, the oscillation that happens when new constraints land, and the steady-state delta during quiet periods.
This role is closest to what platform engineering teams do today, but focused on the identity-to-code relationship rather than infrastructure. It is operational and measurable. The question is "how fast is the system becoming what it declared itself to be?" (The stewards own the separate question of whether the declaration is right.)
Benefit: Implementation becomes measurable and tunable. Convergence velocity, steady-state delta, and over-enforcement rate replace "story points completed."
Release management from identity
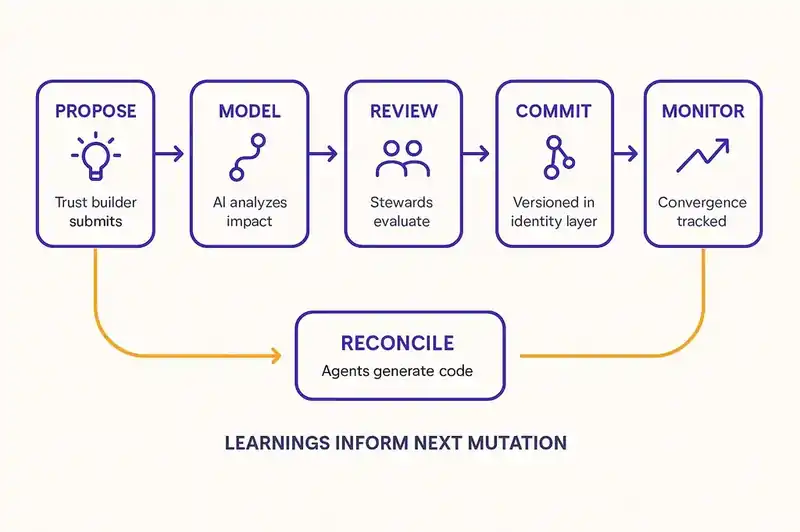
In the traditional model, a release is "deploy this branch." A collection of commits, bundled into a build, pushed through a pipeline, promoted to production. The relationship between the release and the business intent behind it is implicit at best. You hope the commits in the branch correspond to the features the PM described, which correspond to the customer needs the researcher identified.
In an identity-first org, a release is "converge to identity version N."
You commit an identity mutation -- a new constraint, a modified contract, a boundary shift. Agents reconcile the code. CI validates every change against the identity layer (not just "do the tests pass?" but "does this change move the implementation closer to the declared identity?"). The reconciled code deploys. Production monitoring checks whether the new constraints hold in the running system.
Rollbacks are identity rollbacks. If the mutation causes problems, you revert the identity change. Agents re-reconcile the code to the previous identity version. The rollback is tied to intent ("we're reverting the data residency constraint because it broke the integration with partner X") not to commits ("we're reverting commits a3f7b2 through e9d1c4 because something broke and we think it's in there somewhere").
Benefit: Releases are tied to intent, not commits. Rollbacks revert decisions, not code.
Compliance as a dashboard, not a project
In most organizations, compliance is a quarterly fire drill. An audit approaches. Someone creates a project. Teams scramble to document what they do, verify that they actually do it, and fix the gaps before the auditor arrives. Evidence gets collected manually. Controls get verified by walking the floor. The whole thing takes months and costs a fortune, and the results are stale by the time the report is published.
In an identity-first org, compliance officers work directly with the identity layer.
They audit identity declarations, not code. "Is the constraint for encryption at rest declared on every service that handles PII? Yes. Are all services converged to that constraint? The dashboard says 94%, three services have open deltas, estimated to close within 48 hours." The compliance officer sees the same convergence data the engineering team sees, because both read from the same identity layer.
When new regulations land, compliance adds the constraints directly. SOC 2 requirements become identity mutations. Agents propagate. The delta becomes visible immediately, and the convergence timeline is estimable. Reports generate from the identity layer because the layer knows what the system declared and how close the implementation is to honoring it.
Compliance tools like Vanta and Drata handle evidence collection and control monitoring. Identity engineering handles the layer beneath: ensuring the code actually implements the constraints those tools verify you have. They're complementary. One checks the box. The other changes the code.
Benefit: Compliance goes from a quarterly fire drill to always-on observability, auditable and current.
Marketing and GTM grounded in identity
A persistent problem in product marketing: the messaging doesn't match the product. The PM described the feature six months ago. The engineer built something slightly different. The marketer wrote copy based on the PM's description. The customer buys based on the copy. The product doesn't do what the copy said. Everyone blames someone else.
In an identity-first org, marketing reads the identity layer.
The identity layer declares what the product does, what constraints it honors, what contracts it exposes. It is the current, version-controlled declaration of what the software is, not a six-month-old PRD. When a trust builder proposes a new capability and it gets committed to the identity, marketing sees the change. When a constraint gets added or removed, the identity changelog surfaces it.
Blog posts, positioning documents, and feature announcements reference the declared identity. The identity layer says it does Z, and the convergence dashboard shows the implementation is at 97% alignment with that declaration.
When identity changes, marketing knows, because the identity layer has a changelog and marketing is subscribed to it. Messaging updates happen proactively.
Benefit: Messaging stays accurate without "let me check with engineering." The product's declared identity is the single source of truth for what it does.
Support and customer success from identity
A customer asks: "Does your product support single sign-on with SAML?" In the traditional org, the support agent checks a knowledge base article that was last updated eight months ago, or escalates to engineering and waits for someone to check.
In an identity-first org, the support agent queries the identity layer. The answer is there: "Authentication contract declares SAML SSO support for enterprise tier customers. Current convergence: 100%." The answer is authoritative. It comes from the same layer that agents build against.
Customer success takes it further. A customer's use case maps to specific identity artifacts: the contracts, constraints, and behavioral guarantees that serve their needs. When a customer reports unexpected behavior, support can diff the identity against the implementation for the specific feature in question. "The identity declares idempotency on this endpoint. The reconciliation dashboard shows a delta was opened two days ago and is 80% closed. The behavior you're seeing is a known divergence that's actively being reconciled." That's a different conversation from "let me file a ticket and get back to you."
When identity mutations happen that affect a customer's use case, customer success sees it in the changelog. They can reach out proactively: "We've strengthened the data residency guarantees on your region. Here's what changed."
Benefit: Support answers are authoritative, not tribal. Customer success can trace use cases to identity artifacts and communicate changes proactively.
Engineering in this world
Engineers don't disappear. They shift.
In the traditional org, most engineering time goes to writing application code: features, bug fixes, integrations, migrations. In an identity-first org, agents handle the application code. Engineers focus on the infrastructure that makes identity engineering work.
The reconciliation engine diffs declared identity against actual implementation and generates changes. The agent orchestration layer manages which agents run, what they read, and how they interact. CI integration runs multi-dimensional validation where different agents evaluate code changes against different slices of the identity layer. The observability stack tracks convergence, deltas, over-enforcement, and token spend.
This is platform engineering, not application development. Engineers build the machinery that lets identity-driven development work at scale. Instead of writing one feature, they build the system that lets agents write all features correctly, continuously, against declared identity.
Some engineers become convergence operators. Some build tooling. Some work on the identity layer infrastructure itself. The role is closer to building the factory than assembling the product. Reconciliation is probabilistic, which means the engineering challenge is making probabilistic systems reliable enough to trust: improving accuracy, reducing over-enforcement, and building feedback loops that let the system learn from corrections.
Benefit: Engineering focuses on leverage instead of repetition. Building the platform multiplies output across every identity mutation, every agent, and every service.
The identity mutation workflow
Across all these functions, a single workflow ties the org together.
A trust builder proposes a change based on customer research. AI models the impact. Stewards review and commit. Agents reconcile the code. Convergence operators monitor and tune. Learnings from reconciliation inform the next proposal. The loop is continuous, not sprint-boxed. Each function has a clear role. Each role contributes to or operates from the same identity layer.
Before and after
What changes for each function, condensed:
| Function | Before (Code-Centered) | After (Identity-Centered) |
|---|---|---|
| Product | Writes PRDs and tickets. Intent lives in documents that drift. | Proposes identity mutations. Intent is version-controlled and traceable. |
| Engineering | Writes application code. Measured by velocity. | Builds platform infrastructure. Measured by convergence enablement. |
| Compliance | Quarterly audit projects. Manual evidence collection. | Adds constraints to identity layer. Monitors convergence dashboards. |
| Marketing | Describes what PM said the product does. Messaging drifts. | Reads identity layer. Messaging tracks declared reality. |
| Support | Escalates to engineering. Answers are tribal knowledge. | Queries identity layer. Answers are authoritative and current. |
| Customer Success | Reactive to complaints. Limited visibility into product state. | Traces use cases to identity artifacts. Proactive on changes. |
| QA/Testing | Validates code against test cases. | CI agents validate code against identity slices. Multi-dimensional. |
| Ops/SRE | Monitors infrastructure and incidents. | Monitors convergence between identity and production behavior. |
| Release Management | Deploys branches. Rollbacks revert commits. | Converges to identity versions. Rollbacks revert mutations. |
| Leadership | Hopes strategy translates through planning to code. | Watches strategy propagate through identity to convergence dashboards. |
The building, not the blueprint
This is a description of an operating model that follows from a single premise: if you declare what your software is, and agents reconcile the code toward that declaration, then every function in the organization can work from the same persistent layer instead of passing lossy messages through a chain of documents and meetings.
Some of this exists today in fragments. Platform engineering teams already abstract away infrastructure. Compliance automation tools already monitor controls. Product ops teams already try to make product decisions traceable. An identity-first org connects these fragments through a single layer, so the compliance officer and the marketing lead and the support agent and the convergence operator are all looking at the same declaration of what the software is -- updated in real time, version-controlled, queryable.
The transition isn't instant. Organizations adopt this incrementally: one team declares its identity, the benefits become visible, other teams follow. The first identity mutation takes the longest because the infrastructure and habits don't exist yet. The tenth takes a fraction of the time. The pattern compounds the same way convergence compounds -- each investment makes the next change cheaper.
The teams that get here first will operate with a coherence that code-centered organizations cannot match, because every function reads from and contributes to the same persistent truth about what the software is and what it is becoming.
That is what an identity-first organization looks like. Same org chart. Different center of gravity.